



 本文深入探讨了神经网络的基本原理,包括神经元的工作机制、感知机及多层神经网络的结构,介绍了BP算法及其在训练过程中的作用。此外,还讨论了深度学习与神经网络的关系,以及过拟合的解决方案。
本文深入探讨了神经网络的基本原理,包括神经元的工作机制、感知机及多层神经网络的结构,介绍了BP算法及其在训练过程中的作用。此外,还讨论了深度学习与神经网络的关系,以及过拟合的解决方案。
第五章-神经网络
神经网络,其原理便是模仿大脑神经元工作,对任何问题都可以进行学习,最终达到预测目的。
定义:由具有适应性简单单元组成的广泛并行互连的网络,它的组织能够模拟生物神经系统对真实世界物体所做出的交互反应。
原理:其最基本的成分是神经元(neuron)。神经元工作原理为:当它“兴奋”时,会向相连的神经元发送化学物质,从而改变这些神经元内的电位。如果神经元内的电位超过了某一个阈值,它就会被激活,“兴奋”起来,向其他神经元发送化学物质。
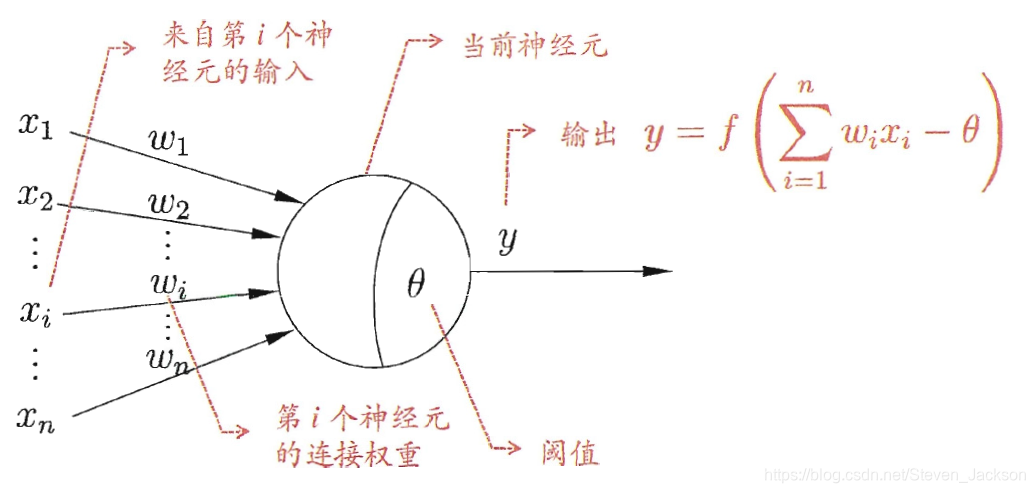
上图所示即为最基本的单个神经元的工作原理:接受来自“树突”的n个刺激,每一个树突都有相应的权值w,最终通过阈值的计算,完成输出y。常用的阈值函数为sigmoid函数,其具有良好的性质。
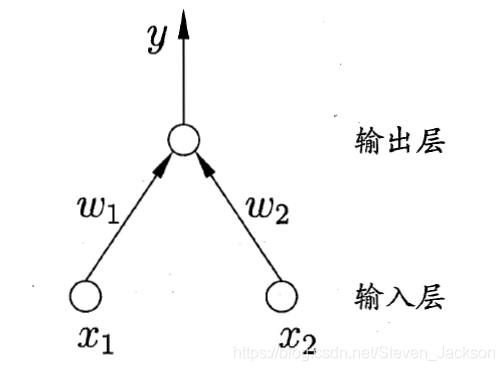
由两层神经元构成的,称为感知机,其具有两层结构,“输入”、“输出”层,其能够完成较简单的工作。
由多层神经元构成的,称为神经网络。下图为BP神经网络,误差逆传播算法。
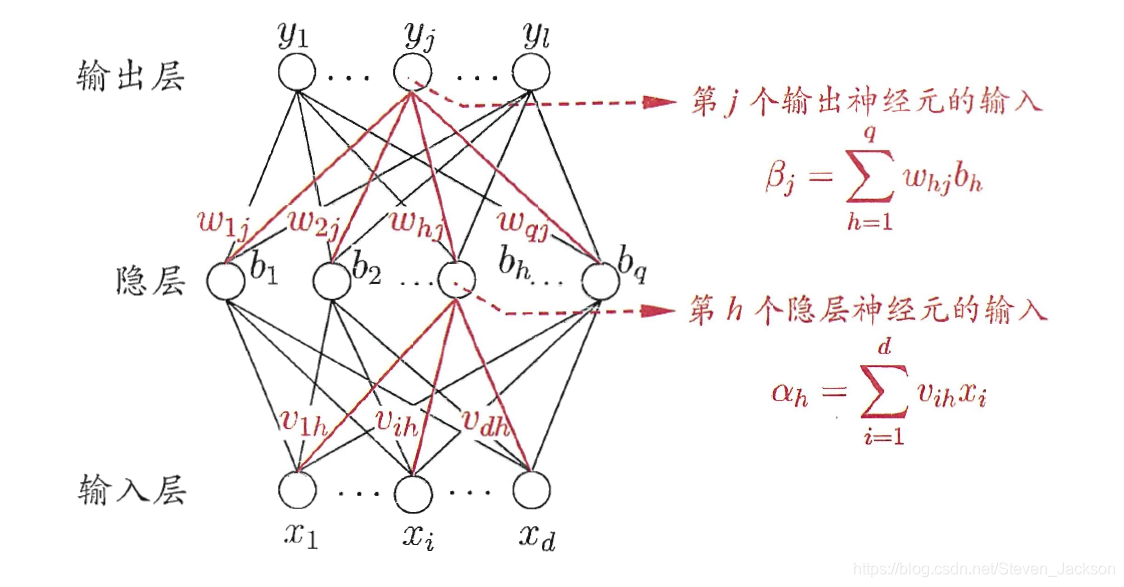
其具有中间层(隐层),通过不断得矫正各神经元间连接权重,从而获得模型。
那么如何获得矫正呢?下面为笔者的推算,思考。
首先,我们确定误差函数,即用于计算每次预测值与实际误差。假定我们使用
确定本次预测为正例的可能性,
为sigmoid函数,
后面半截为本次预测为反例的可能性。要根据其逐层的权值,对其求导,即可得出误差最小值。


上述推导过程也很直观地体现在西瓜书中,我们可以通过这一系列推导得到权值的更新公式:
(与手推过程字母表示不同)注意:
为学习速率
在不断更新权值的过程中,模型不断和真实值拟合。由于其强大的表示能力,常常发生过拟合的现象,通常有两种解决方案:
- 早停,将数据分成训练集和验证集,训练集用来计算梯度、更新连接权和阈值,验证集用来估计误差,若训练集误差降低但验证集误差升高,则停止训练,同时返回具有最小验证集误差的连接权和阈值。
- 正则化,其基本思想是在误差目标函数中增加一个用于描述网络复杂度的部分,例如连接权值的平方和,即:不能太复杂,太复杂往往会发生过拟合。
全局最小与局部最小
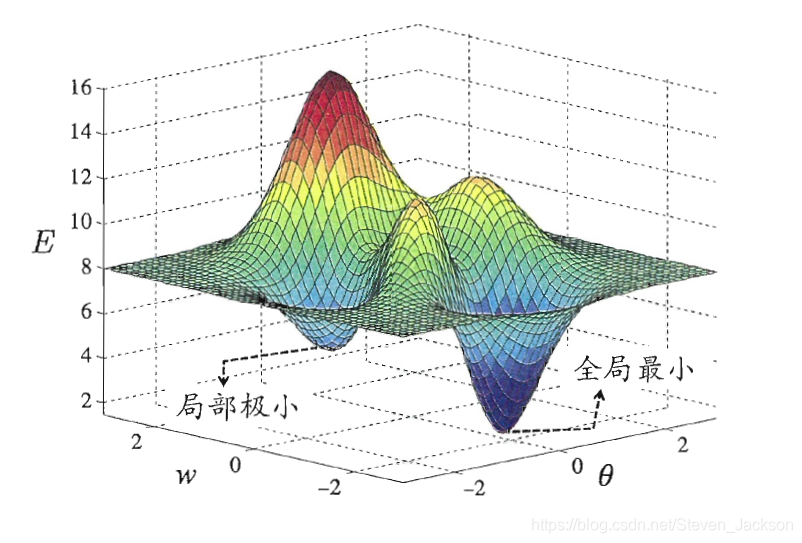
全局最小值和局部最小示意图如上。
训练神经网络通常使用梯度下降法,于是不可避免得有可能陷入“局部极小值”。人们通常使用以下三种方法改进:
- 以多组不同参数值初始化多个神经网络,分别进行训练,最终比较极小值;
- 使用“模拟退火”,模拟退火在每一步都以一定的概率接受比当前更差的结果,从而有助于“跳出”局部极小值。
- 使用随机梯度下降,即有可能不选择当前最优值,从而有可能跳出当前局部最优。
神经网络除了BP算法之外,还有很多延伸算法,如RBF网络,ART网络,SOM网络,级联相关网络等,不做赘述。
除此之外,深度学习与神经网络的关系也密不可分。典型的深度学习模型就是很深层的神经网络。显然对神经网络模型,提高容量的一个简单办法就是增加隐层的数目,隐层多了,模型复杂度也就会增加。典型的深度学习算法:无监督逐层训练,CNN等。
神经网络是一种“黑箱模型”,即不用特别理解其解释性,参数会通过不断迭代而自我矫正,从而达到拟合目的。

















 603
603

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









