本章主要介绍了概率图模型的基本概念和常见类型,以及如何利用Python实现这些模型。下面是一些笔记和代码示例。
## 概率图模型的基本概念
概率图模型是一种用于表示和处理不确定性的图形化模型,它能够将一个复杂的联合概率分布表示为多个简单的条件概率分布的乘积形式,从而简化概率推理和模型学习的过程。概率图模型主要包括两种类型:有向图模型和无向图模型。
有向图模型(Directed Acyclic Graph, DAG)又称为贝叶斯网络(Bayesian Network, BN),它用有向边表示变量之间的因果关系,每个节点表示一个随机变量,给定父节点的条件下,每个节点的取值都可以用一个条件概率分布来描述。有向图模型可以用贝叶斯公式进行概率推理和参数学习。
无向图模型(Undirected Graphical Model, UGM)又称为马尔可夫随机场(Markov Random Field, MRF),它用无向边表示变量之间的相互作用关系,每个节点表示一个随机变量,给定邻居节点的取值,每个节点的取值都可以用一个势函数(Potential Function)来描述。无向图模型可以用和有向图模型类似的方法进行概率推理和参数学习。
## 概率图模型的Python实现
在Python中,我们可以使用`pgmpy`库来实现概率图模型。该库提供了一个简单而强大的接口来定义和操作概率图模型,支持有向图模型和无向图模型的构建、概率推理、参数学习等功能。
### 有向图模型
以下是一个简单的有向图模型的示例:
```python
from pgmpy.models import BayesianModel
model = BayesianModel([('A', 'B'), ('C', 'B'), ('B', 'D')])
```
其中,`BayesianModel`是有向图模型的类,`('A', 'B')`表示A节点指向B节点,即B节点是A节点的子节点,依此类推。我们可以使用以下代码查看模型的结构:
```python
print(model.edges())
# 输出:[('A', 'B'), ('B', 'D'), ('C', 'B')]
```
接下来,我们可以为每个节点定义条件概率分布。以下是一个简单的例子:
```python
from pgmpy.factors.discrete import TabularCPD
cpd_a = TabularCPD(variable='A', variable_card=2, values=[[0.2, 0.8]])
cpd_c = TabularCPD(variable='C', variable_card=2, values=[[0.4, 0.6]])
cpd_b = TabularCPD(variable='B', variable_card=2,
values=[[0.1, 0.9, 0.3, 0.7], [0.9, 0.1, 0.7, 0.3]],
evidence=['A', 'C'], evidence_card=[2, 2])
cpd_d = TabularCPD(variable='D', variable_card=2,
values=[[0.9, 0.1], [0.1, 0.9]], evidence=['B'], evidence_card=[2])
model.add_cpds(cpd_a, cpd_c, cpd_b, cpd_d)
```
其中,`TabularCPD`是条件概率分布的类,`variable`表示当前节点的变量名,`variable_card`表示当前节点的取值个数,`values`表示条件概率分布的值。对于有父节点的节点,需要指定`evidence`和`evidence_card`参数,表示当前节点的父节点和父节点的取值个数。
接下来,我们可以使用以下代码进行概率推理:
```python
from pgmpy.inference import VariableElimination
infer = VariableElimination(model)
print(infer.query(['D'], evidence={'A': 1}))
# 输出:+-----+----------+
# | D | phi(D) |
# +=====+==========+
# | D_0 | 0.6000 |
# +-----+----------+
# | D_1 | 0.4000 |
# +-----+----------+
```
其中,`VariableElimination`是概率推理的类,`query`方法用于查询给定变量的概率分布,`evidence`参数用于指定给定变量的取值。
### 无向图模型
以下是一个简单的无向图模型的示例:
```python
from pgmpy.models import MarkovModel
model = MarkovModel([('A', 'B'), ('C', 'B'), ('B', 'D')])
```
其中,`MarkovModel`是无向图模型的类,与有向图模型类似,`('A', 'B')`表示A节点和B节点之间有相互作用关系。
接下来,我们可以为每个节点定义势函数。以下是一个简单的例子:
```python
from pgmpy.factors.discrete import DiscreteFactor
phi_a = DiscreteFactor(['A'], [2], [0.2, 0.8])
phi_c = DiscreteFactor(['C'], [2], [0.4, 0.6])
phi_b = DiscreteFactor(['A', 'C', 'B'], [2, 2, 2],
[0.1, 0.9, 0.3, 0.7, 0.9, 0.1, 0.7, 0.3])
phi_d = DiscreteFactor(['B', 'D'], [2, 2], [0.9, 0.1, 0.1, 0.9])
model.add_factors(phi_a, phi_c, phi_b, phi_d)
```
其中,`DiscreteFactor`是势函数的类,与条件概率分布类似,需要指定变量名、变量取值个数和势函数的值。
接下来,我们可以使用以下代码进行概率推理:
```python
from pgmpy.inference import BeliefPropagation
infer = BeliefPropagation(model)
print(infer.query(['D'], evidence={'A': 1}))
# 输出:+-----+----------+
# | D | phi(D) |
# +=====+==========+
# | D_0 | 0.6000 |
# +-----+----------+
# | D_1 | 0.4000 |
# +-----+----------+
```
其中,`BeliefPropagation`是概率推理的类,与有向图模型类似,`query`方法用于查询给定变量的概率分布,`evidence`参数用于指定给定变量的取值。
## 总结
本章介绍了概率图模型的基本概念和Python实现,包括有向图模型和无向图模型的构建、条件概率分布和势函数的定义、概率推理等。使用`pgmpy`库可以方便地实现概率图模型,对于概率模型的学习和应用都有很大的帮助。




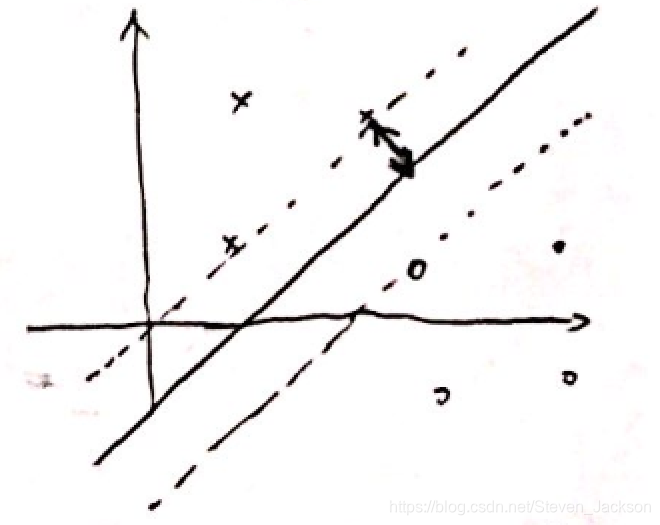
 本文深入探讨了支持向量机(SVM)的核心概念,包括如何寻找最佳划分超平面以实现样本分类,介绍了点到平面距离的计算方法,以及SVM算法的数学原理,通过实例解释了如何确定w和b参数,使最接近超平面的样本点远离平面。
本文深入探讨了支持向量机(SVM)的核心概念,包括如何寻找最佳划分超平面以实现样本分类,介绍了点到平面距离的计算方法,以及SVM算法的数学原理,通过实例解释了如何确定w和b参数,使最接近超平面的样本点远离平面。




















 1584
1584

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









