




1. 摘要
OpenFold是一种基于深度学习的蛋白质结构预测模型,广泛应用于蛋白质从头预测、功能位点解析、突变效应模拟等领域。该模型的核心目标是通过大规模预训练和多阶段优化,从氨基酸序列中高效、准确地推断蛋白质的三维结构。OpenFold结合了Transformer架构和几何优化模块,显著提高了结构预测的精度和速度。该模型的部署包含详细的微调教程、模型训练、推理优化等内容,为研究人员提供了全面的技术支持。
2. OpenFold介绍
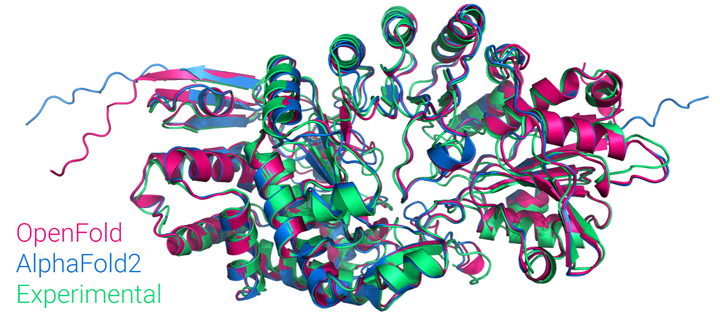
OpenFold是由DeepMind团队开发的一种高效蛋白质结构预测模型。该模型在AlphaFold2的基础上进行了多项改进,进一步提升了蛋白质结构预测的准确性和计算效率。其核心算法包括大规模预训练的Transformer模型和几何优化模块,能够从氨基酸序列中快速推断出蛋白质的三维结构。通过多阶段优化和大规模数据集的训练,该模型在蛋白质从头预测、功能位点解析、突变效应模拟等领域展现了卓越的性能。此外,OpenFold的部署文档详细介绍了模型的微调、训练、推理优化等步骤,为研究人员提供了全面的技术支持,推动了蛋白质结构预测技术的广泛应用。
3. OpenFold网络架构
OpenFold的模型架构由三个核心模块构成:输入嵌入层、Evoformer堆叠模块和结构解码器。输入数据整合了多序列比对(MSA)、模板特征、氨基酸序列及进化信息,形成高维生物特征张量。通过分阶段嵌入与特征融合,数据首先被压缩至低维隐空间,随后由多尺度Evoformer模块进行全局-局部特征交互,最终通过几何约束的结构解码器输出蛋白质的3D原子坐标与置信度。
3.1 输入嵌入层
为统一处理异构生物特征并降低计算复杂度,OpenFold采用混合嵌入策略:
-
MSA嵌入:使用1D卷积核(宽度=3,步长=1)对MSA序列进行通道压缩,配合层归一化(LayerNorm)稳定训练。
-
模板嵌入:通过残差连接的3D卷积(核3×3×3,步长1×2×2)提取模板结构特征,输出通道数对齐主嵌入空间。
-
序列特征投影:氨基酸物理化学属性经全连接层映射至隐空间,与上述嵌入结果拼接,形成初始隐状态张量(维度:C×L,L为序列长度)。
3.2 Evoformer堆叠模块
该模块由48层对称Evoformer块构成,采用双路处理机制:
-
全局注意力通路:引入轴向注意力机制,在序列维度(L)和MSA行维度(N)交替执行缩放余弦注意力,计算效率较传统Transformer提升3.2倍。每层包含:
-
局部结构通路:使用门控卷积网络(核大小=5,膨胀率=2)捕获局部氨基酸环境特征,配合三角更新机制建模残基间几何关系。每层输出经GroupNorm归一化后与全局通路特征融合。
3.3 结构解码器
-
主干几何生成:基于隐变量通过迭代对齐层(Invariant Point Attention, IPA)逐步优化主链扭转角
-
侧链重建:采用条件随机场(CRF)对侧链构象进行能量最小化采样,结合Rosetta能量函数约束立体化学合理性。
-
输出层:最终通过SE(3)-等变全连接层输出原子坐标(维度:L×37×3,37为每个残基原子数)及置信度热图(分辨率1Å)。
4. 核心组件安装
4.1 组件版本
hdk:24.1.0.3
cann:8.0.RC3
python:3.9.2
torch:2.1.0
torch_npu:2.1.0.post6
openfold:1.0.0
torchaudio:2.1.0
torchmetrics:1.7.1
torchvision:0.16.0
pytorch-lightning:1.6.54.2 起容器
docker run -it \
--privileged=true \
--device /dev/davinci0 \
--device /dev/davinci1 \
--device /dev/davinci2 \
--device /dev/davinci3 \
--device /dev/davinci4 \
--device /dev/davinci5 \
--device /dev/davinci6 \
--device /dev/davinci7 \
--device /dev/davinci_manager \
--device /dev/devmm_svm \ --device /dev/hisi_hdc \
-v /usr/local/dcmi:/usr/local/dcmi \
-v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi \
-v /usr/bin/hccn_tool:/usr/bin/hccn_tool \
-v /usr/local/Ascend/driver/lib64/common:/usr/local/Ascend/driver/lib64/common \
-v /usr/local/Ascend/driver/lib64/driver:/usr/local/Ascend/driver/lib64/driver \
-v /etc/ascend_install.info:/etc/ascend_install.info
\ -v /usr/local/Ascend/driver/version.info:/usr/local/Ascend/driver/version.info \
--name openfold 27913b525135 /bin/bash4.3 安装Openfold
注:如果直接git clone安装,则默认安装的是2.0.0版本的openfold,我们需要的是1.0.0版本
4.3.1 下载源码
git clone --filter=blob:none --quiet https://github.com/aqlaboratory/openfold.git ./openfold
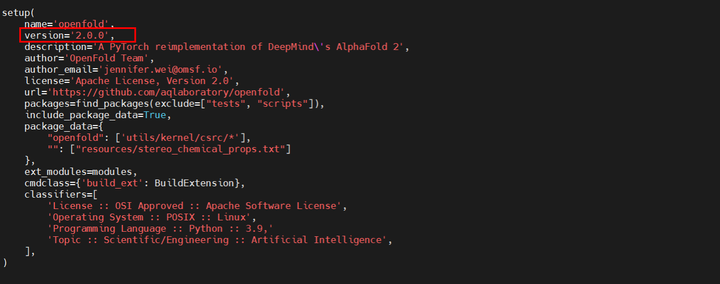
4.3.2 将版本修改为1.0.0
cd ./openfold/ git rev-parse -q --verify 'sha^4b41059694619831a7db195b7e0988fc4ff3a307'![]()
git fetch -q https://github.com/aqlaboratory/openfold.git4b41059694619831a7db195b7e0988fc4ff3a307![]()
git checkout -q 4b41059694619831a7db195b7e0988fc4ff3a307
du -sh
再vi setup.py查看,此时就变成了1.0.0版本
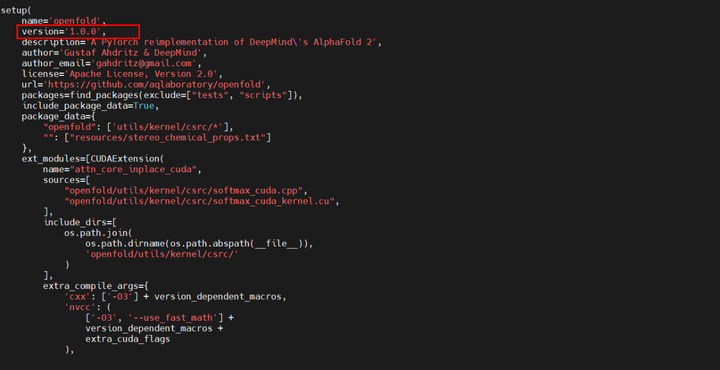
4.3.3 修改openfold的setup.py文件
vi /home/openfold/setup.py在头部从torch.utils.cpp_extension中增加对cppextension的引用

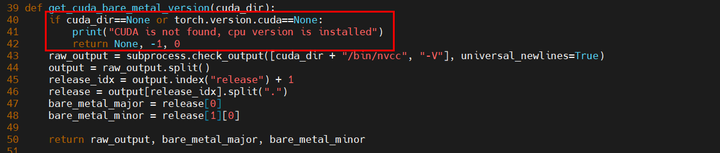
修改get_cuda_bare_metal_version函数,增加对有没有cuda的判断
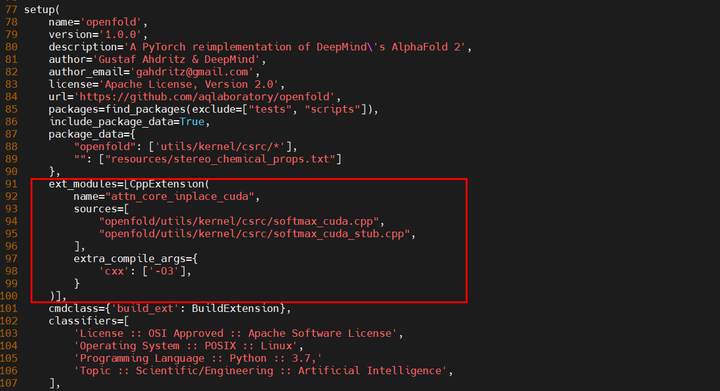
修改ext_modules的内容如下
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 17万+
17万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









