




论文题目:Multibehavior Intent Disentangled Learning for Fine-Grained Interest Discovery in Recommendation
发表期刊:IEEE Transactions on Computational Social Systems (Vol. 12, No. 6, Dec 2025)
作者:Yuqing Du, Guan Yuan, Guixian Zhang 等
代码地址:https://github.com/shawn-dm/MBIDR
1. 引言:为什么我们需要“意图解耦”?
在推荐系统领域,利用用户的辅助行为(Auxiliary Behaviors,如浏览、收藏、加购)来辅助预测目标行为(Target Behavior,通常是购买)已经成为缓解数据稀疏问题的有效手段。
然而,现有的多行为推荐方法(如 GHCF, CEMBR 等)往往存在一个关键缺陷:忽略了用户交互背后的“意图”。
- 行为内的混淆 (Intra-behavior confusion):同样是“浏览”行为,可能是用户无聊时的随意点击(弱偏好),也可能是为了深入了解商品详情(强偏好)。
- 行为间的混淆 (Inter-behavior confusion):通常认为“购买”比“浏览”更能代表强偏好,但有时购买可能只是代购(弱偏好),而反复浏览可能隐含了极强的潜在兴趣。
为了解决这个问题,本文提出了一种多行为意图解耦推荐模型 (MBIDR)。该模型的核心在于:不仅关注用户做了什么(行为类型),更通过自动化的方式解耦用户为什么做(潜在意图)。
2. 模型架构详解
MBIDR 的整体框架主要包含三个核心模块:意图感知交互分类器、自适应关系学习以及模型预测与训练。
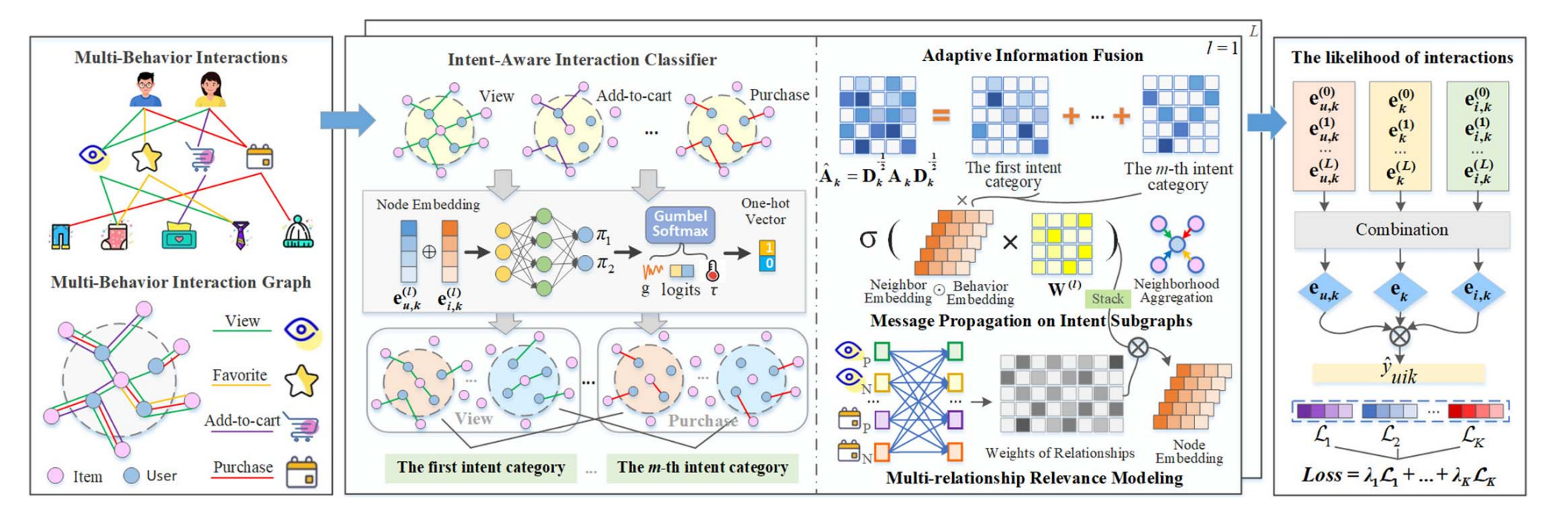
图 1:左侧是多行为交互图;中间展示了意图分类器(将交互划分为不同子图)和自适应融合过程;右侧是最终的预测层。
2.1 意图感知交互分类器 (Intent-Aware Interaction Classifier)
这是论文最核心的创新点。传统的做法是直接根据行为类型(View, Cart, Buy)划分自图,而 MBIDR 在此基础上,进一步将每种行为下的交互划分为不同的“意图类别”。
如何自动发现潜在意图?
由于用户的意图是隐式的(没有标签),论文设计了一个端到端的学习机制:
-
特征拼接:对于用户 u u u 和物品 i i i 在行为 k k k 下的交互,拼接两者的 Embedding 输入到多层感知机(MLP)中。
π = M L P ( e u , k ∣ ∣ e i , k ) \pi = MLP(e_{u,k} || e_{i,k}) π=MLP(eu,k∣∣ei,k)
其中 π = [ π 1 , π 2 ] \pi = [\pi_1, \pi_2] π=[π1,π2] 表示该交互属于不同意图类别的概率(为简化模型,论文中设定为 2 类)。 -
Straight-Through Gumbel-Softmax (STGS) 采样:
为了将交互分配给特定的意图子图,我们需要得到一个 One-hot 向量。直接使用argmax操作是不可导的,无法进行反向传播。因此,作者使用了 Gumbel-Softmax 技巧。p m = e x p ( ( g m + l o g ( π m ) ) / τ ) Σ n = 0 1 e x p ( ( g n + l o g ( π n ) ) / τ ) p_{m}=\frac{exp((g_{m}+log(\pi_{m}))/\tau)}{\Sigma_{n=0}^{1}exp((g_{n}+log(\pi_{n}))/\tau)} pm=Σn=01exp((gn+log(πn))/τ)exp((gm+log(πm))/τ)
- g m g_m gm 是从 Gumbel 分布中采样的噪声。
- τ \tau τ 是温度系数(Temperature),控制分布的平滑程度。
STGS 的优势:它允许模型在训练过程中以概率的方式探索不同的意图划分,同时保持梯度可导。这避免了硬分类(Hard Assignment)导致的模型过早收敛于次优解。
最终,基于生成的 Mask 矩阵,原始的“浏览行为图”被拆分成了“浏览-意图1子图”和“浏览-意图2子图”。
2.2 自适应关系学习 (Adaptive Relation Learning)
将交互解耦到细粒度的意图子图后,如何聚合这些信息?简单的平均或固定权重(如认为购买权重 > 浏览权重)是不可取的,因为不同场景下用户意图的重要性是动态变化的。
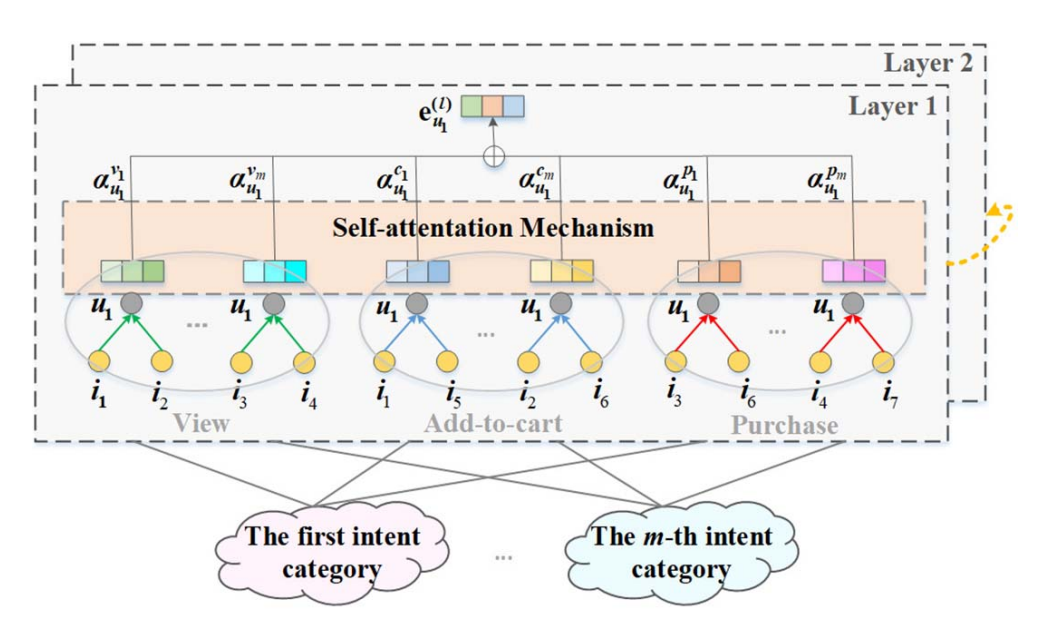
图 2:模型通过注意力机制计算权重(如 α u , 1 v m \alpha_{u,1}^{v_m} αu,1vm),动态衡量不同意图子图对用户偏好学习的重要性。
-
子图信息传播:
在每个意图子图 G k m \mathcal{G}_{k}^{m} Gkm 上,使用图卷积聚合邻居信息:
e u , k m ( l ) = σ ( A g g ( { e i , k ( l − 1 ) ⊙ e k ( l − 1 ) ∣ i ∈ N u , k m } ) W ( l ) ) e_{u,k_{m}}^{(l)}=\sigma(Agg(\{e_{i,k}^{(l-1)}\odot e_{k}^{(l-1)}|i\in\mathcal{N}_{u,k_{m}}\})W^{(l)}) eu,km(l)=σ(Agg({ei,k(l−1)⊙ek(l−1)∣i∈Nu,km})W(l))
这里不仅考虑了节点 Embedding,还融入了行为类型的 Embedding e k e_k ek。 -
多关系相关性建模 (Self-Attention):
模型将所有意图子图下的用户表示拼接,利用 Self-Attention 机制自动学习权重 α u , k \alpha_{u,k} αu,k:
α u , k = s o f t m a x ( ( W 2 k ) ⊤ t a n h ( ( e u W 1 k ) ⊤ ) ) \alpha_{u,k}=softmax((W_{2}^{k})^{\top}tanh((e_{u}W_{1}^{k})^{\top})) αu,k=softmax((W2k)⊤tanh((euW1k)⊤))
这使得模型能够根据上下文,赋予“强意图浏览”比“弱意图加购”更高的权重,从而实现更精准的偏好融合。
2.3 模型预测与训练
- 层级组合:采用类似 LightGCN 的策略,对不同 GNN 层的输出取均值( β = 1 / ( L + 1 ) \beta=1/(L+1) β=1/(L+1)),得到最终的用户和物品表示。
- 非采样损失函数 (Non-sampling Loss):
为了解决多行为数据中正负样本极度不平衡的问题,且避免负采样带来的偏差,论文采用了高效的非采样损失策略。
L ( Θ ) = ∑ k = 1 K λ k L k ( Θ ) + μ ∣ ∣ Θ ∣ ∣ 2 2 \mathcal{L}(\Theta)=\sum_{k=1}^{K}\lambda_{k}\mathcal{L}_{k}(\Theta)+\mu||\Theta||_{2}^{2} L(Θ)=k=1∑KλkLk(Θ)+μ∣∣Θ∣∣22
该损失函数利用了全量的历史交互数据,通过权重系数 λ k \lambda_k λk 平衡不同行为任务的贡献。
3. 实验结果与分析 (Experiments)
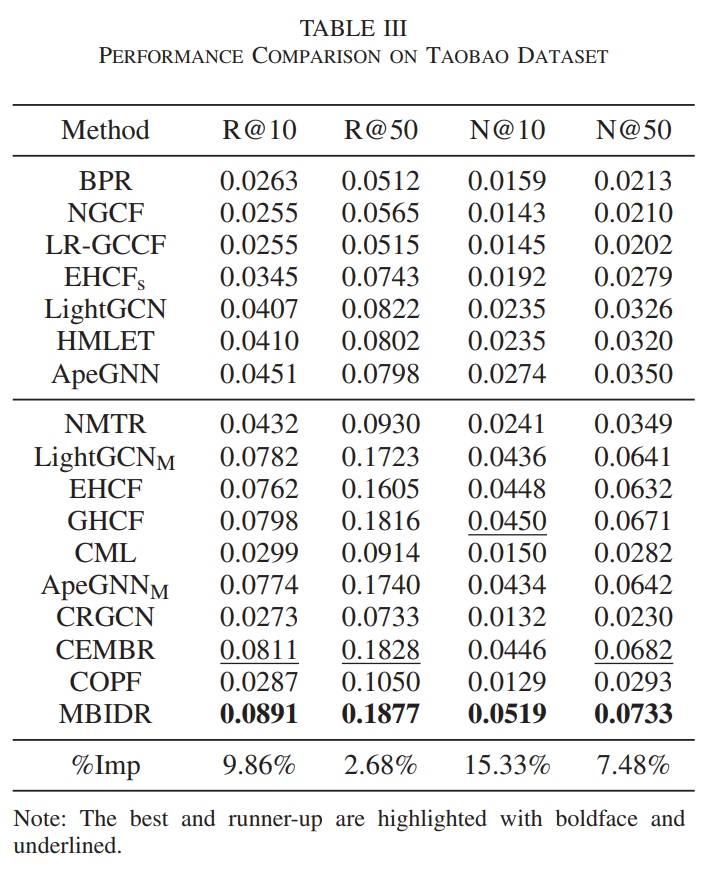
实验在 Beibei (母婴电商) 和 Taobao (综合电商) 两个大规模真实数据集上进行。
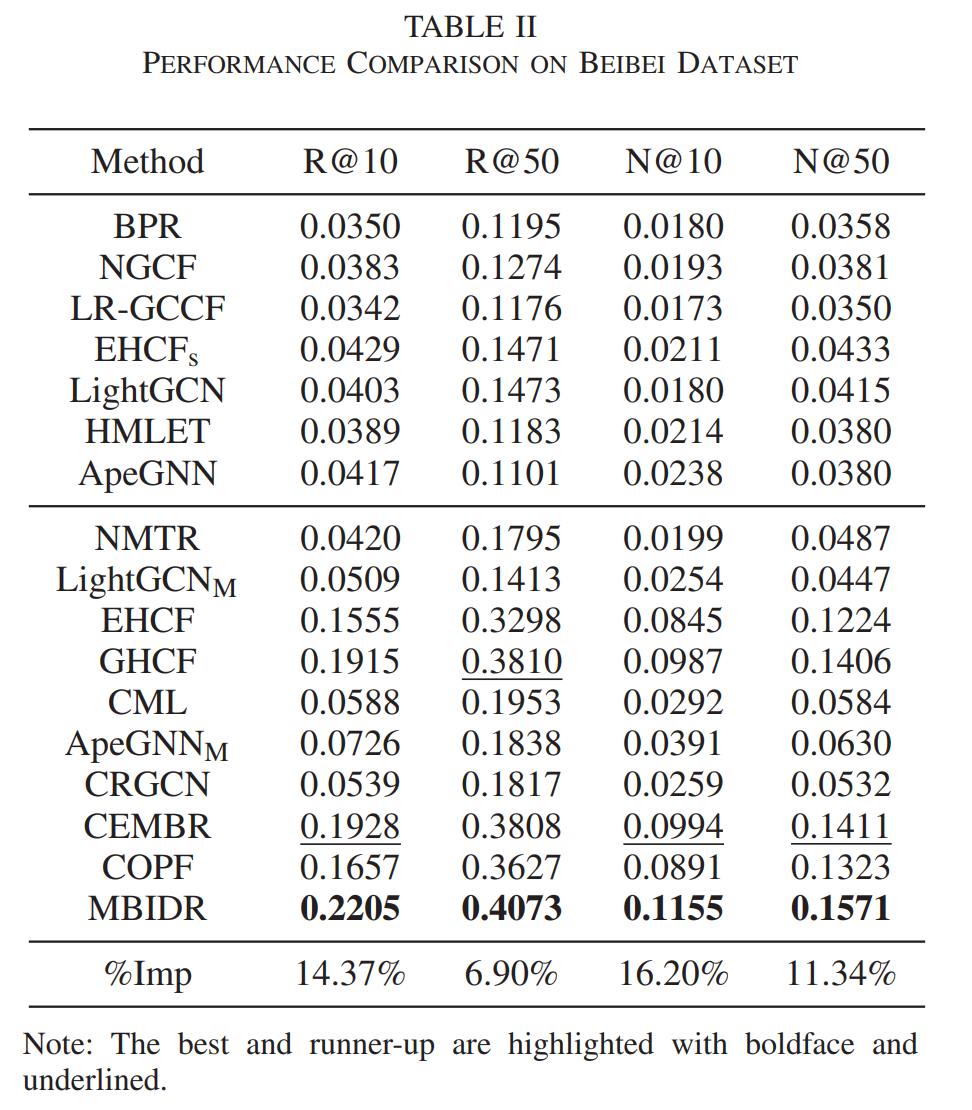
3.1 核心性能对比 (SOTA Comparison)
MBIDR 与主流的单行为模型 (LightGCN等) 和多行为模型 (GHCF, CML, CEMBR等) 进行了对比。
| 模型 | Beibei (Recall@10) | Beibei (NDCG@10) | Taobao (Recall@10) | Taobao (NDCG@10) |
|---|---|---|---|---|
| MBIDR | 0.2205 | 0.1155 | 0.0891 | 0.0519 |
| 提升幅度 | +14.37% | +16.20% | +9.86% | +15.33% |
数据来源:Table II & Table III
主要结论:
- MBIDR 在两个数据集上的各项指标均取得了最优结果。
- 相比最强基线,提升幅度显著,证明了细粒度的意图解耦能有效过滤噪声,增强强偏好信号的表达。
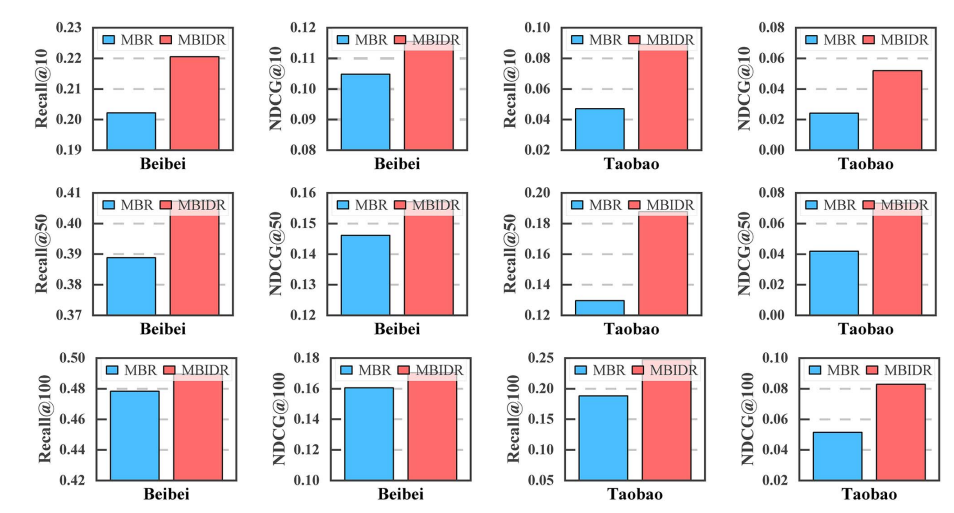
3.2 关键消融实验 (Ablation Study)
为了验证各模块的有效性,论文进行了详细的消融分析:
-
意图分类器有效吗?(RQ2)
- 变体 MBR (移除意图分类,直接在行为图上卷积) 的性能显著低于 MBIDR。
- 结论:粗粒度的行为建模存在严重的偏好混淆问题,意图解耦是必要的。
-
STGS 采样是必须的吗?(RQ3)
- 将 STGS 替换为 “MLP直接输出 + 梯度裁剪” (即硬分类)。结果显示 STGS 效果更好。
- 原因:硬分类容易让某些交互“死板”地固定在某一个类别中,缺乏探索性;而 Gumbel 噪声带来的随机性帮助模型找到了更优的划分边界。
3.3 鲁棒性分析 (Robustness)
模型在面对数据质量问题时表现如何?
-
面对数据稀疏 (Cold-start):
- 将用户按交互数量分组,在交互最少(<9次购买)的用户组中,MBIDR 依然大幅领先 GHCF 和 CEMBR。
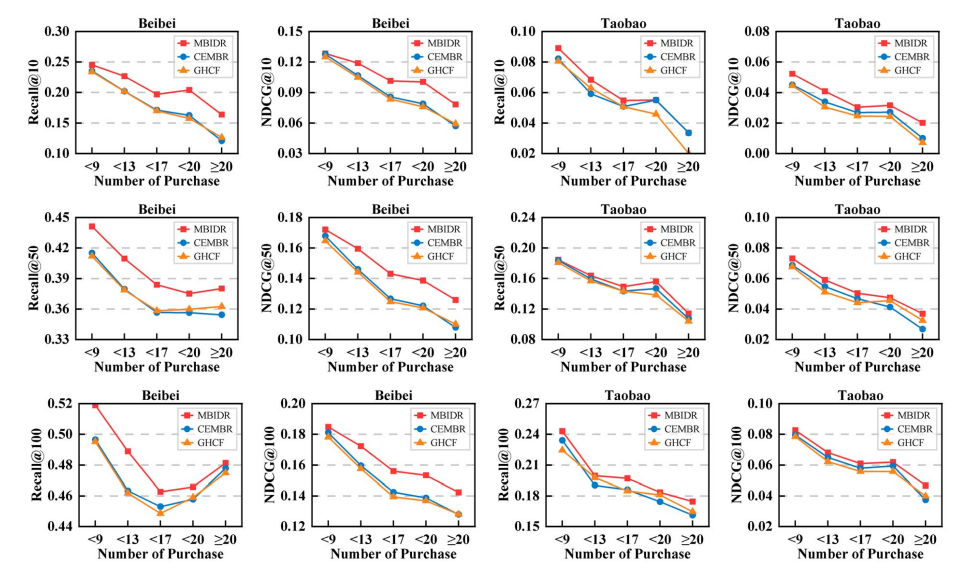
- 将用户按交互数量分组,在交互最少(<9次购买)的用户组中,MBIDR 依然大幅领先 GHCF 和 CEMBR。
-
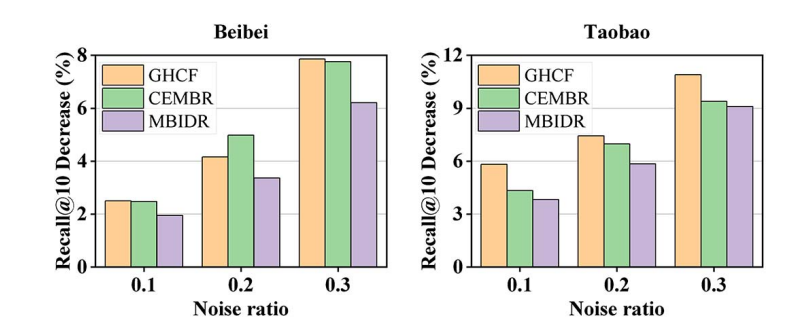
面对噪声交互 (Noise):
-
在辅助行为中人为混入 10%~30% 的随机噪声。MBIDR 的性能下降幅度最小。
-
原因:意图分类器成功将这些随机噪声归类到了“低权重”的意图子图中,通过自适应加权抑制了它们的负面影响。
-
4. 总结与思考
这篇论文通过 Gumbel-Softmax 巧妙地实现了离散意图的端到端学习,解决了一个长期存在的问题:多行为推荐中行为与意图不匹配,导致偏好建模失真和噪声干扰的问题。
主要贡献点:
- 自动化意图解耦:不再依赖人工规则,而是让模型自己学习如何将交互分类。
- 动态权重分配:通过 Self-Attention 实现了行为与意图层面的自适应融合。
- 优异的抗噪性:能够自动识别并降权噪声交互,特别适合真实的电商环境。

















 807
807

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









