 PCDreamer:基于扩散先验的点云补全
PCDreamer:基于扩散先验的点云补全




原文论文:PCDreamer: Point Cloud Completion Through Multi-view Diffusion Priors 作者:G. Wei, Y. Feng, L. Ma, C. Wang, Y. Zhou, and C. Li
论文地址: https://arxiv.org/abs/2411.19036
代码地址: GitHub - GSW-D/PCDreamerCode: The code of paper PCDreamer
一、引言
点云补全在推动三维视觉发展中扮演着关键角色,是自动驾驶、机器人技术和增强现实等众多应用的核心环节。由扫描遮挡或传感器范围限制导致的不完整点云数据带来了重大挑战。尽管已有诸多创新方法被提出,但在点云全局完整性和局部几何细节方面仍存在显著改进空间。本文针对存在自遮挡的单视角局部点云补全问题展开研究。
如图1(a)(b)所示,单视角扫描特性常导致三维形状丢失超50%的信息。典型案例包括缺失整个背面的台灯,以及缺少座椅右侧大部分结构和腿部的椅子。这种大面积缺失区域意味着补全过程面临巨大的解空间。现有主流方法仅依赖局部点云的几何信息,采用由粗到精的方式生成完整形状。虽然能补全缺失椅背支撑的椅子整体轮廓(图1(c)),但对于缺失关键灯罩顶部的台灯,这些方法会产生随机局部猜测。
图1
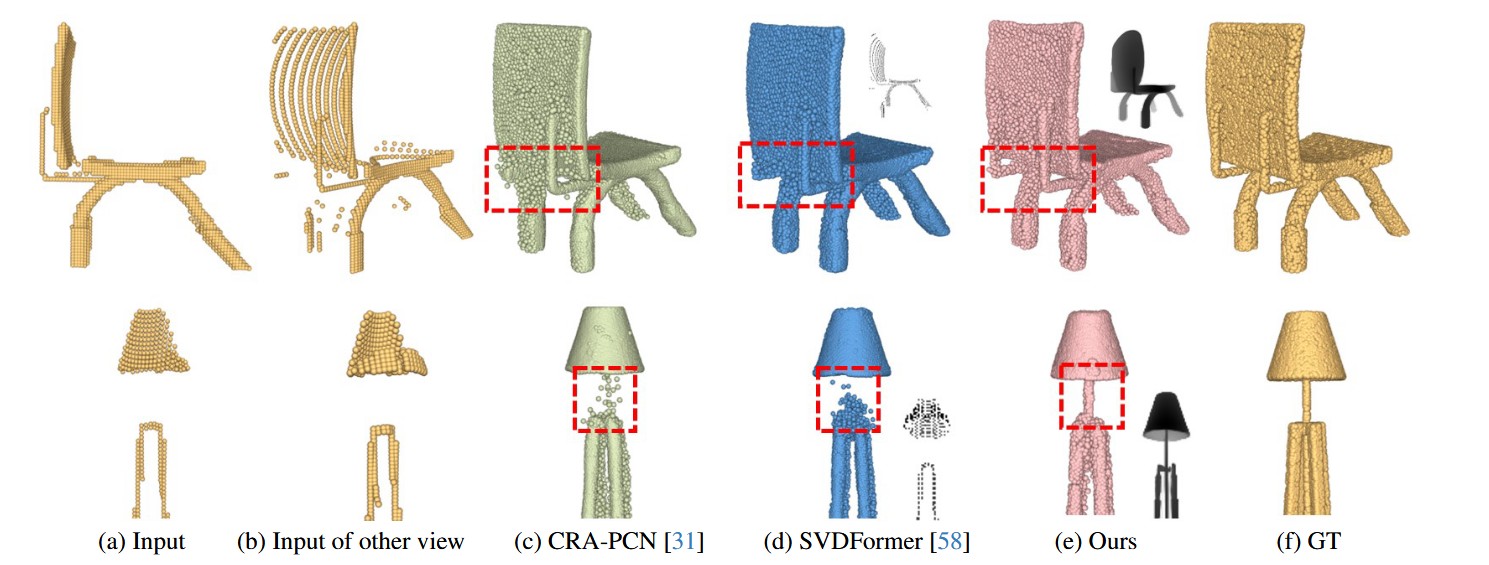
部分研究尝试引入额外图像信息提升补全效果(图1(d)椅子),但实践中获取配对图像数据具有挑战性。受扩散模型图像生成成功启发,我们发现大模型生成的多视角图像具有视图一致性优势,能为形状补全提供丰富的全局与局部线索。例如基于局部点云生成的图像能捕捉对称元素(图1(e)上:椅背;下:灯罩顶部),实现包含所有关键特征的完整形状重建。
为此,我们提出PCDreamer算法,通过三个核心模块实现高质量点云补全:首先利用多视角扩散模型根据单视角局部点云"幻化"出逼真图像集;其次通过注意力机制融合图像与点云观测,生成保留全局结构与局部特征的初始完整形状;最终采用置信度引导的形状整合器消除多视角图像不一致性,输出高保真度的最终模型。大量实验验证了本方案的卓越性能。
二、模型架构
PCDreamer 的整体架构与传统的点云补全网络(如 PCN, PoinTr)有着本质的区别。传统方法通常试图直接在 3D 空间中学习点坐标的回归,而 PCDreamer 则选择了将 3D 补全任务转化为 2D 图像生成(Inpainting)任务,再通过几何投影还原回 3D 空间。
模型的整体流程可以概括为三个阶段:多视角图像生成(Multi-view Image Generation)、3D 形状提升与融合(3D Lifting & Fusion) 以及 最终点云整合(Shape Consolidation)。
1. 多视角图像生成:让扩散模型“脑补”缺失视角(Multi-view Image Generation)
这是整个框架中最具创新性的部分。模型的输入是一个残缺的稀疏点云 。
-
从 3D 到 2D 的投影:
首先,模型通过一个虚拟相机系统,将输入的残缺点云投影渲染为多张 2D 深度图或轮廓图。这些图像中包含了物体“可见部分”的信息。 -
扩散先验的引入(The Diffusion Prior):
传统的补全经常因为缺乏参考而产生模糊的结构。PCDreamer 利用了一个预训练的 多视角扩散模型(Multi-view Diffusion Model)(类似于 MVDream 或经过微调的 Stable Diffusion)。-
Conditioning(条件注入):模型将上一步渲染出的“残缺投影”作为控制条件(Condition),类似于 ControlNet 的工作原理。
-
Joint Denoising(联合去噪):扩散模型开始生成物体在其他视角(包括背部、侧面等不可见区域)的 RGB 图像。关键在于,这个过程利用了 Attention 机制在不同视角间共享信息,确保生成的前视图和后视图在纹理和几何结构上是语义一致的。
-
结果:我们得到了一组围绕物体 360 度的高质量、语义连贯的 RGB 图像。
-
2. 3D 形状提升与融合:从平面回归立体(Shape Fusion / 3D Lifting)
现在我们有了一组漂亮的 2D 图片,但我们的目标是 3D 点云。这一步需要解决“从 2D 像素恢复 3D 坐标”的难题。
-
深度估计(Depth Estimation):
由于扩散模型生成的只是 RGB 图像,PCDreamer 引入了一个单目深度估计模块(Monocular Depth Estimator),为生成的每一张 RGB 图像预测对应的深度图(Depth Map)。 -
反向投影(Back-projection):
利用相机内参和外参,将带有深度的像素点反向投影回 3D 空间。这样,每一张生成的图片都变回了一小片 3D 点云。 -
粗糙点云融合(Coarse Fusion):
将来自不同视角的点云碎片拼凑在一起。这里通过一个基于坐标的对齐算法,将这些由“幻觉”生成的点与原始输入的真实点(Ground Truth parts)融合,形成一个完整的、但可能带有噪声的粗糙点云(Coarse Point Cloud)。
3. 形状整合与精细化:去噪与均匀化(Shape Consolidation & Refinement)
直接融合的多视角点云通常面临两个问题:一是不同视角拼接处的重影或错位,二是由于深度估计误差带来的表面噪声。
为了解决这个问题,PCDreamer 设计了一个精细化模块(Refinement Module):
-
特征编码与重采样:
使用轻量级的 PointNet++ 或 Transformer 结构提取粗糙点云的全局特征。 -
几何一致性优化:
模型通过一个折叠网络(FoldingNet-like structure)或上采样模块,对点云进行平滑处理。它会重新分布点的密度,确保物体表面均匀,并去除那些因深度预测错误而产生的离群点(Outliers)。 -
最终输出:
经过这一步,原本拼接痕迹明显的粗糙点云,变成了一个表面光滑、细节丰富且保留了原始几何特征的完整 3D 点云。
三、实验结果
为了验证 PCDreamer 利用 2D 扩散先验解决 3D 问题的有效性,作者在主流的点云补全基准数据集上进行了广泛的测试。实验结果表明,该方法不仅在数值指标上刷新了 State-of-the-art (SOTA),更在视觉质量上实现了质的飞跃。
1. 实验设置与评估指标
-
数据集:
-
PCN (Point Completion Network) Dataset:这是最经典的点云补全基准,包含 8 个类别的物体(如飞机、椅子、车等),数据具有不同程度的缺失。
-
ShapeNet-55:一个类别更丰富(55 类)、更具挑战性的数据集,通常用于评估模型的泛化能力和 Zero-shot(零样本)表现。
-
-
评估指标:
主要使用 Chamfer Distance (CD-L1) 作为核心指标。CD 值越小,代表补全后的点云与真实点云(Ground Truth)越接近。此外,还使用了 F-Score 来衡量形状的几何保真度。
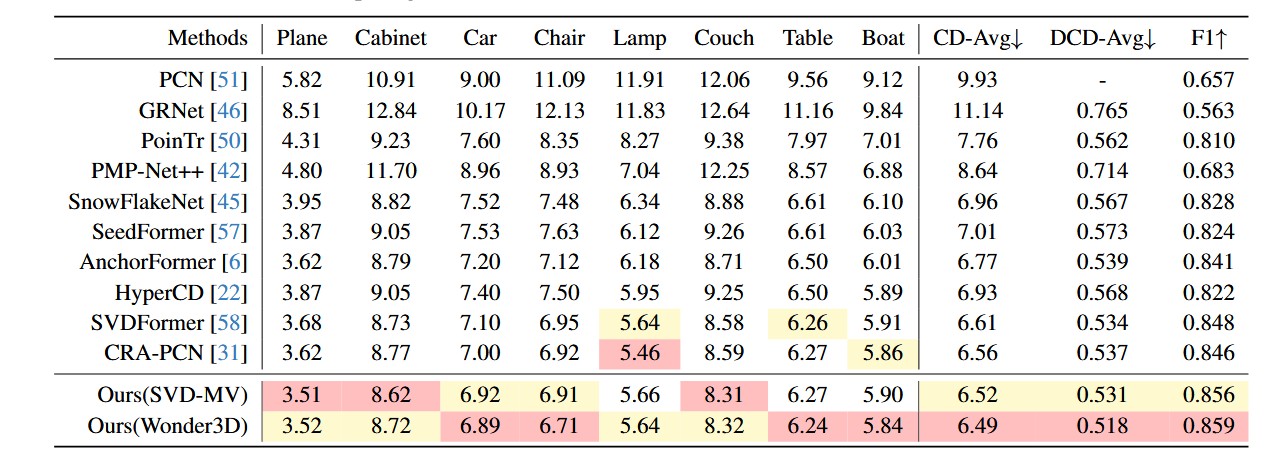
2. PCN 数据集上的 SOTA 表现(定量分析)
在 PCN 数据集的对比实验中,PCDreamer 与近年来最强的竞争对手进行了正面交锋,包括 PoinTr, SnowflakeNet, ProxyFormer 以及 SeedFormer 等。
-
数值优势:实验数据显示,PCDreamer 在所有类别的平均 Chamfer Distance 上均取得了最低的误差值。特别是在椅子(Chair)、灯具(Lamp)等结构复杂、拓扑多变的类别上,性能提升尤为显著。
-
突破瓶颈:传统的基于折叠网络(Folding-based)或 Transformer 的方法,往往在处理细长结构(如椅腿)或孔洞结构时表现挣扎,而 PCDreamer 得益于扩散模型的强先验,能够精准地“回忆”出这些复杂的几何结构。
3. 视觉效果对比(定性分析)
除了冷冰冰的数字,PCDreamer 在可视化结果上的优势更加直观。
-
细节纹理的恢复:
对比其他方法生成的模糊一团的点云,PCDreamer 生成的点云具有极高的清晰度。 - 拓扑一致性:在补全飞机的机翼或汽车的轮胎时,PCDreamer 展现出了极好的整体连贯性,点分布均匀,极少出现传统方法中常见的离群噪点(Outliers)。

4. 强大的零样本泛化能力 (Zero-shot Generalization)
这是该论文最大的亮点之一。作者在 ShapeNet-55 数据集上进行了 Zero-shot 测试,即:模型在训练时从未见过某个类别(如钢琴),但在测试时却能补全它。
-
跨类别迁移:
实验结果表明,PCDreamer 在未见类别上的表现大幅优于 PoinTr 和 SeedFormer。 -
原因分析:
这直接归功于模型引入的 Multi-view Diffusion Priors。虽然 3D 模型没见过“钢琴”,但预训练的 2D 扩散模型(Stable Diffusion 变体)在海量互联网图片中见过无数次钢琴。这种从 2D 域迁移来的通用知识,使得 PCDreamer 具备了极其强悍的泛化能力,不再局限于训练集中的那几个死板类别。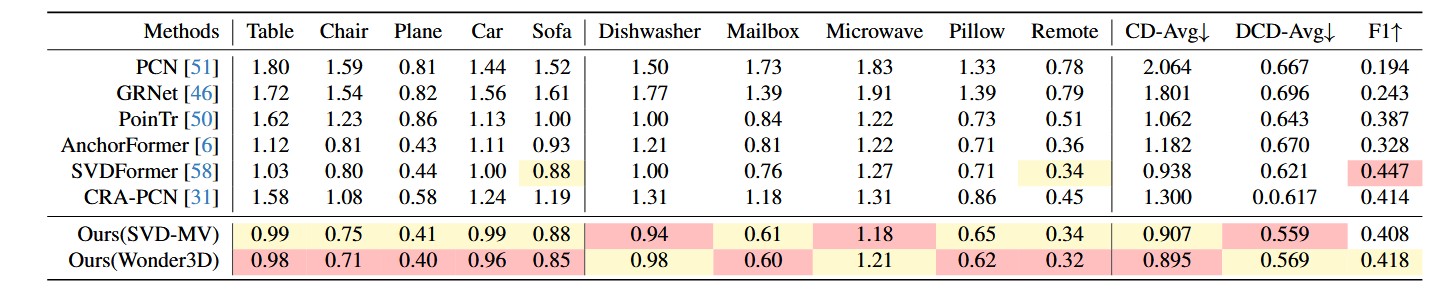
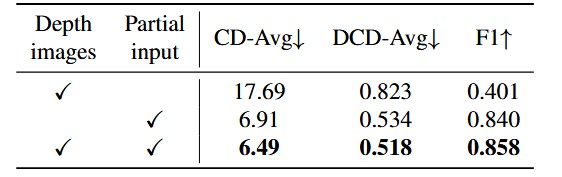
5. 消融实验 (Ablation Study)
作者还进一步验证了各个模块的必要性:
-
多视角 vs. 单视角:证明了生成多视角图像(Multi-view)比仅生成单张图像能提供更丰富的几何约束。
-
深度估计与精细化:验证了 Refinement 模块对于去除深度估计噪声、平滑物体表面的关键作用。
四、结论
这篇论文最核心的贡献在于,通过引入多视角扩散先验(Multi-view Diffusion Priors),成功借用了 2D 视觉大模型在海量数据中学到的通用知识。实验证明,这种策略是非常有效的——它不仅解决了复杂结构的细节恢复问题,更赋予了模型在未见类别上惊人的 Zero-shot 泛化能力。简而言之,PCDreamer 告诉我们:想要更好地理解 3D 世界,有时候我们需要先回到 2D 世界去寻找答案。
虽然 PCDreamer 效果惊艳,但在实际应用中仍面临一些挑战,这也是论文中诚恳讨论的部分,值得我们在博客中提及:
-
推理速度 (Inference Latency):
由于引入了扩散模型(Diffusion Model)进行多视角图像生成,PCDreamer 的推理时间相比于传统的基于 GAN 或 Transformer 的方法要长得多。在需要实时处理(Real-time)的自动驾驶或机器人避障场景中,如何加速这一过程仍是待解决的难题。 -
依赖深度估计精度:
模型的最终效果很大程度上取决于“2D 图像转 3D 点云”这一步的精度。如果深度估计模块(Depth Estimator)出现误差,生成的点云几何结构就会出现变形。未来的改进方向可能需要联合优化生成与深度估计这两个过程。

















 784
784

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









