



论文链接:https://arxiv.org/pdf/2505.04163
代码链接:https://github.com/archon159/RAFT
主要内容:这篇文章提出了一种新的时间序列预测框架 RAFT(Retrieval-Augmented Forecasting of Time-series)。其核心思想是:除了利用深度模型学习序列的时空依赖外,还从历史数据中检索与当前输入片段最相似的历史模式,并将这些片段对应的未来走势作为参考,通过相似度加权融合进预测过程。这样的方法既能利用深度模型的表达能力,又能充分挖掘历史中重复出现的模式,尤其在罕见模式或时间相关性较弱的场景下表现突出。大量实验表明,RAFT 在多个时间序列基准数据集上显著优于现有方法,有效提升了预测的准确性与鲁棒性。
1.引言
1.1 时间序列预测的重要性
- 背景:时间序列预测通过分析历史数据来预测未来趋势,对于许多领域(如气候建、能源、经济、交通流量和用户行为等)的决策制定至关重要。
- 作用:通过提供可靠的预测,时间序列预测能够帮助人们在各个领域制定有效的策略和政策。
1.2 现有方法的局限性
- 深度学习模型的发展:在过去十年中,深度学习模型(如卷积神经网络(CNNS)和循环神经网络(RNNS))在捕捉历史数据中的模式变化方面表现出色,推动了时间序列预测领域的发展。尤其是基于注意力机制的 Transformer 架构,对时间序列预测产生了重大影响。
- 现有方法的不足
- 复杂非平稳模式:现实世界中的时间序列数据具有复杂的、非平稳的式,这些模式可能缺乏内在的时间相关性,并且来自非确定性过程。这使得模型在从这些不频繁出现的模式中进行外推时面临挑战。
- 记忆所有模式的效率问题:盲目记忆所有模式(包括声和不相关模式)在模型的泛化能力和效率方面存在疑问。
1.3本文提出的RAFT方法
- 核心思想:RAFT 通过检索增强(Retrieval-Augmented)的方式,直接从训练数据集中检索与输入模式最相似的历史数据候选,并利用这些候选的未来值与输入一起进行预测。这种方法通过检索模块外部提供关于过去模式的信息,减轻了模型在训练过程中记忆所有模式的负担。
- 优势
- 显式利用历史模式:在推理时,有用的过去模式可以直接被利用,而不是通过模型0权重中学习到的信息来利用。这使得模型能够覆盖那些缺乏时间相关性或与其他模式没有共同特征的模式,从而减轻学习负担并增强泛化能力。
- 应对罕见模式:即使某些模式在历史数据中很少出现且难以被模型记忆,检索块也能在这些模式重新出现时轻松利用它们。
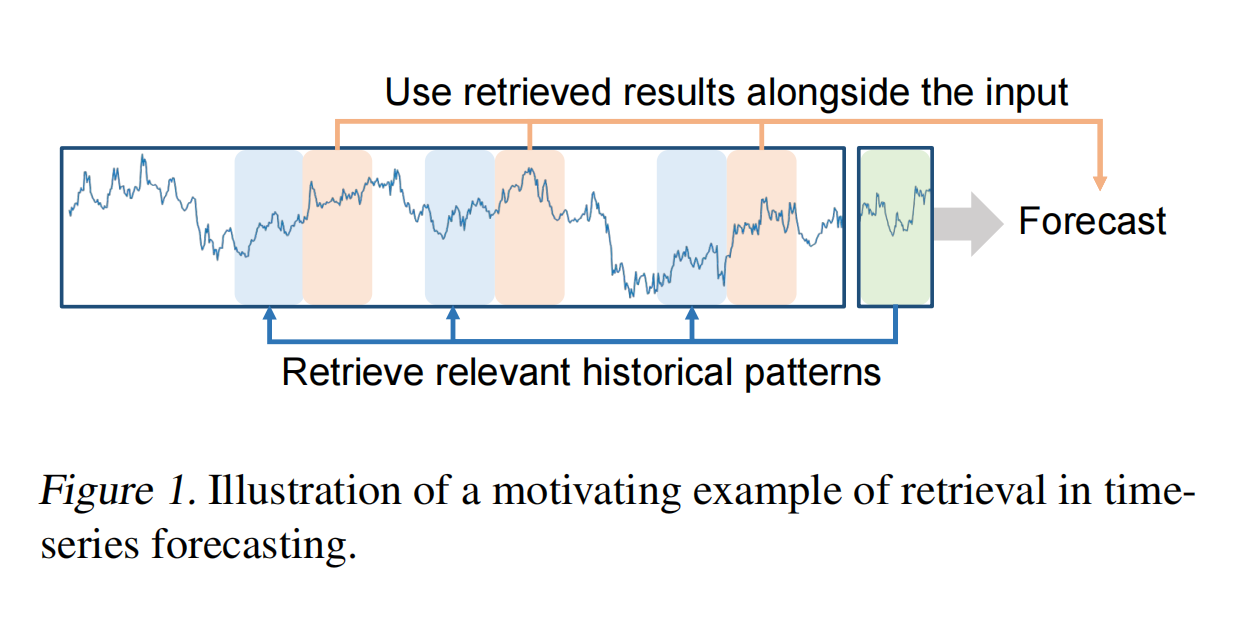
Figure 1 通过一个直观的例子展示了 RAFT 方法的核心思想:通过检索与当前输入相似的历史模式,并利用这些模式的未来趋势信息来增强模型的预测能力。图中展示了当前输入的时间序列片段(用蓝色表示)。这个输入片段是模型需要基于其进行未来预测的部分模型通过检索模块在训练数据集中查找与输入片段最相似的历史模式(用绿色表示)。这些历史模式被称为“关键片段(key patches)",它们与输入片段具有相似的时间模式。检索模块会找到与输入片段最相似的关键片段,并获取其后续的时间序列片段(称为“值片段(value patches)")。这些值片段包含了与输入片段相似模式的未来趋势信息。检索到的值片段(绿色)与输入片段(蓝色)一起被用于预测未来的时间序列。通过结合输入片段和检索到的历史模式的未来趋势信息,模型能够更准确地预测未来的时间点。
2.相关工作
2.1 深度学习在时间序列预测领域的应用和发展
- 卷积神经网络(CNNS)和循环神经网络(RNNS):卷积神经网络通过卷积层捕捉局部时间模式,适用于处理具有局部相关性的时间序列数据。循环神经网络通过其循环结构建模时间序列的顺序依赖性,适合处理具有长期依赖关系的数据。Hewamalage et al.(2021)指出 RNNS 及其变体(如 LSTM 和 GRU)在时间序列预测中表现出色。
- Transformer 架构
- Transformer 的引入:Vaswani et al.(2017)提出的 Transformer 架构通过自注意力机制(self-attention)建模输入之间的依赖关系,显著提升了时间序列预测的性能。
- 基于 Transformer 的变体:Informer:Zhou et al.(2021)提出的 Informer 使用了 ProbSparse 注意力模块和蒸馏技术,有效减少了网络规模,提高了计算效率;AutoFormer:Wu et al.(2021)提出的 AutoFormer 通过分解时间序列(趋势和季节性模式)来提高预测性能;FedFormer:Zhou et al.(2022)提出的 FedFormer 同样利用时间序列分解技术进一步提升了预测效果。
- 轻量级模型(Lightweight Models)
- 多层感知机(MLP):近年来,轻量级的 MLP 模型在时间序列预测中也取得了显著的性能。例如,TSMixer 和 DLinear 的研究展示了 MLP 在结合时间序列分解和多周期性分析时的强大性能。
- 多周期性分析:通过在不同周期对时间序列进行降采样或升采样,这些轻量级模型能够更有效地提取时间序列中的相关信息。Lin et al.(2024)提出的SparseTSF和 Wang etal.(2024)提出的 TimeMixer 进一步证明了这种方法的有效性。
深度学习模型能够自动学习时间序列中的复杂模式,包括局部模式、长期依赖关系和季节性模式。通过大量的训练数据,深度学习模型能够学习到通用的特征表示,从而在不同的时间序列数据上表现出良好的泛化能力。但其计算成本较高,尤其是 Transformer 架构其计算复杂度较高,训练和推理过程需要大量的计算资源。同时,深度学习型通常需要大量的数据来训练,以避免过拟合。且其通常被视为“黑盒“模型,其预测结果难以解释。
尽管深度学习模型在时间序列预测中取得了显著进展,但现实世界中的时间序列数据具有复杂的、非平稳的模式,这些模式可能缺乏内在的时间相关性。此外,型需要记忆所有模式(包括噪声和不相关模式)以进行预测,这不仅增加了计算负担,还可能影响模型的泛化能力。RAFT 通过检索增强的方式,直接从训练数据中检索与输入相似的历史式,并利用这些模式的未来趋势信息进行预测。这种方法不仅减轻了模型的学习负担,还提高了预测的准确性和效率。
2.2 检索增强模型
检索增强模型(Retrieval-Augmented Models)是一种结合了检索(Retrieval)和生成的混合方法。其基本工作流程如下Generation):
检索阶段:给定一个输入,模型首先从一个大型数据集中检索出与输入最相关的实例(或片段)。这些实例通常是通过某种相似性度量(如余弦相似度、皮尔逊相关系数等)来确定的。
生成阶段:检索到的相关实例与原始输入一起被送入模型,用于生成最终的预测结果这种方法的核心思想是通过检索模块提供额外的信息,帮助型更好地理解和生成输出。
- 检索增强模型在时间序列预测中的应用
在时间序列预测领域,检索增强模型的应用相对较少,但已经有一些研究展示了其潜力。例如:
- Iwata & Kumagai(2020):他们提出了一种方法,通过检索多个时间序列实体中的相似实体来进行预测。这种方法假设训练集中包含多种类型的时间序列实体,并通过聚合所有时间序列实体之间的相似性信息来进行预测。
- Yang et al.(2022):他们的研究进一步探索了在时间序列预测中检索相似实体的潜力。
- RAFT 的创新点
RAFT(Retrieval-Augmented Forecasting of Time-series)是本文提出的检索增强时间序列预测方法。它的主要创新点包括:
- 单时间序列的检索增强:与上述多时间序列实体的检索方法不同,RAFT 专注于单个时间序列的检索增强。它通过从同一个时间序列中检索与当前输入最相似的历史式,并利用这些模式的未来趋势信息来进行预测。
- 多周期检索:RAFT通过在不同周期对时间序列进行降采样,并在每个周期上应用检索模块,从而有效地捕捉短期和长期模式。这种方法不仅提高了预测的准确性,还减轻了模型的记忆负担。
- 简单高效的架构:RAFT 基于浅层 MLP 架构,通过检索模块提供额外的信息,从而简化了模型的学习过程。这种方法在保持高效的同时,还能够处理复杂的、非平稳的时间序列数据。
- 检索增强模型的优势
检索增强模型的主要优势在于:
- 减轻学习负担:通过检索模块提供额外的信息,模型不需要在训练过程中记忆所有可能的模式,从而减轻了学习负担。
- 提高泛化能力:检索模块能够捕捉到与输入最相似的历史模式,即使这些模式在训练数据中不常见,模型也能够利用它们进行预测,从而提高了泛化能力。
- 处理复杂模式:对于那些缺乏时间相关性或不常见的时间序列模式,检索模块能够有效地提供相关信息,帮助模型更好地处理这些复杂模式。
3.模型介绍
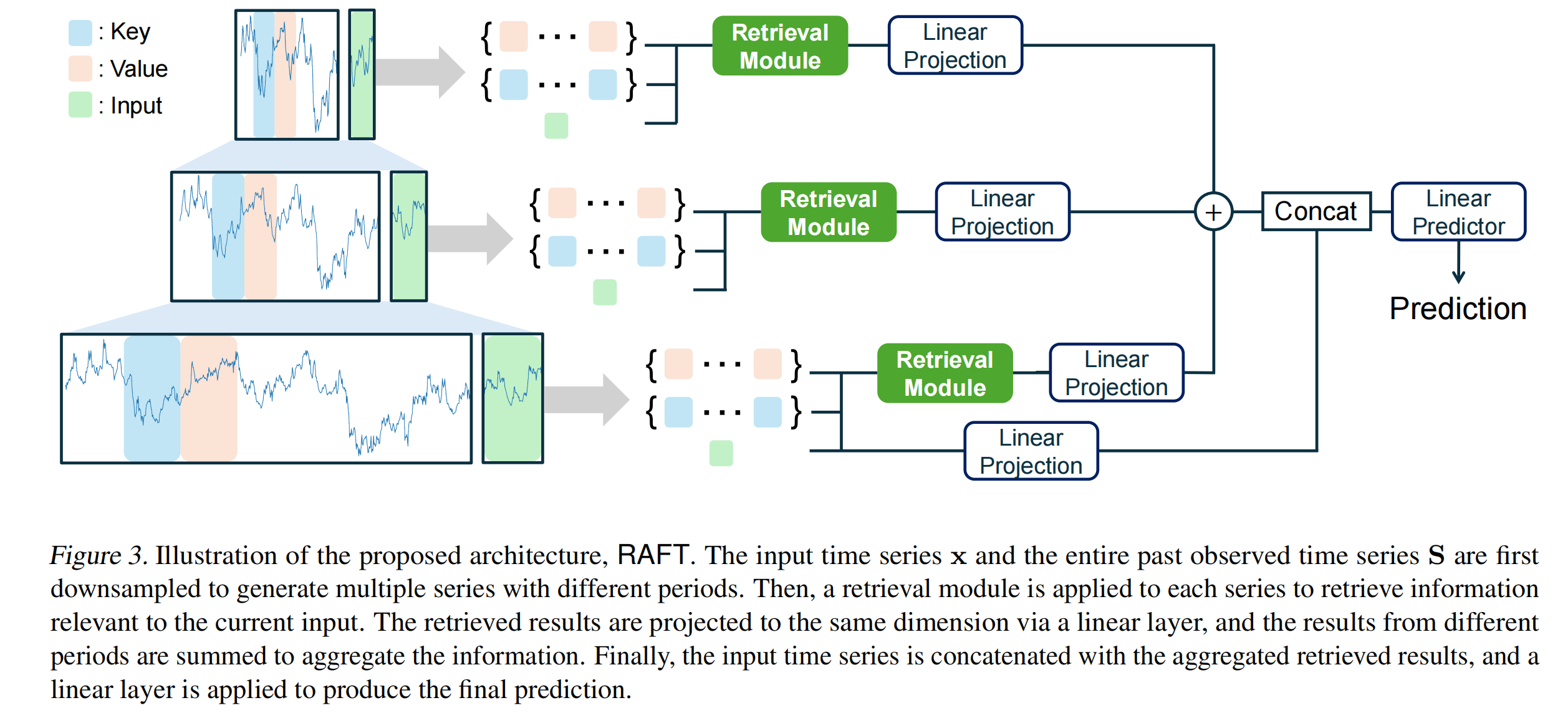
3.1 概述
- 输入与目标:给定一个单变量时间序列
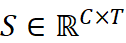 ,其中 T 是时间序列的长度,C 是观测变量的数量(即通道数)。模型的目标是利用历史观测值
,其中 T 是时间序列的长度,C 是观测变量的数量(即通道数)。模型的目标是利用历史观测值 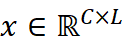 (称为“回溯窗口”)来预测未来的值
(称为“回溯窗口”)来预测未来的值 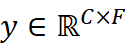 ,其中 L 是回溯窗口的大小,F 是预测窗口的大小,未来值用
,其中 L 是回溯窗口的大小,F 是预测窗口的大小,未来值用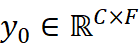 表示。
表示。
- 检索模块 (Retrieval Module) :RAFT 的关键创新之一是检索模块,它从整个时间序列 S 中检索与输入
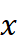 最相似的历史片段(称为“关键片段” K)。检索模块不仅找到与输入最相似的关键片段,还获取这些关键片段之后的时间序列片段(称为“值片段” V),这些值片段包含了未来趋势的信息。检索过程基于输入和关键片段 K 之间的相似性计算权重,并通过加权和的方式聚合值片段,生成检索结果
最相似的历史片段(称为“关键片段” K)。检索模块不仅找到与输入最相似的关键片段,还获取这些关键片段之后的时间序列片段(称为“值片段” V),这些值片段包含了未来趋势的信息。检索过程基于输入和关键片段 K 之间的相似性计算权重,并通过加权和的方式聚合值片段,生成检索结果 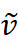 。
。 - 多周期检索 (Multi-Period Retrieval) :时间序列在不同时间尺度上可能表现出不同的特征。RAFT 通过在多个周期(如 1、2、4 等)上对时间序列进行降采样,生成多个不同时间尺度的时间序列。每个降采样后的时间序列都应用检索模块,从而捕捉不同时间尺度上的模式。从不同周期检索到的结果通过线性投影映射到相同的嵌入空间,并通过求和的方式进行聚合。
- 预测模块 (Prediction Module) :检索结果
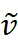 和输入被连接起来,然后通过一个线性模型生成最终的预测结果
和输入被连接起来,然后通过一个线性模型生成最终的预测结果 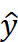 。最后,通过将预测结果
。最后,通过将预测结果 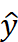 与输入
与输入 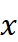 的最后一个时间步的值相加,恢复原始的偏移量,得到最终的预测值
的最后一个时间步的值相加,恢复原始的偏移量,得到最终的预测值 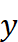 。
。
3.2 检索模块
检索模块是 RAFT 的核心组件之一,它通过从整个时间序列中检索与输入最相似的历史模式,并利用这些模式的未来趋势信息来辅助预测。检索块的主要目标是从训练数据集中找到与当前输入片段 最相似的历史片段(关键片段 K),并获取这些关键片段之后的时间序列片段(值片段 V)。这些值片段包含了未来趋势的信息,可以用于辅助预测。检索模块的工作流程可以分为以下关键步骤:
- 准备关键片段和值片段
1.使用滑动窗口方法从时间序列![]() 中提取所有可能的关键片段。每个关键片段的长度 为
中提取所有可能的关键片段。每个关键片段的长度 为![]() ,滑动窗口的步长为12 (可以根据需要调整)。
,滑动窗口的步长为12 (可以根据需要调整)。
2.定义关键片段集合![]() ,其中
,其中![]() 表示从时间步
表示从时间步![]() 开始的关键片段。 任何与输入片段
开始的关键片段。 任何与输入片段![]() 重叠的关键片段在训练阶段必须从集合
重叠的关键片段在训练阶段必须从集合![]() 中排除。
中排除。
3.对于每个关键片段![]() ,找到其在时间序列中后续的值片段
,找到其在时间序列中后续的值片段![]() 。值片段的长度为
。值片段的长度为![]() 。定义值片段集合
。定义值片段集合![]() ,其中
,其中![]() 表示关键片段
表示关键片段![]() 之后的值片段。
之后的值片段。
- 预处理
为了使模式更具可比性,作者对输入片段![]() 和所有关键片段
和所有关键片段![]() 以及值片段
以及值片段![]() 进行预处理,通过减去每个片段最后一个时间步的值来调整偏移量。
进行预处理,通过减去每个片段最后一个时间步的值来调整偏移量。
定义调整后的输入片段![]() ,其中
,其中![]() 是输入片段
是输入片段![]() 的最后一个时间步的值。同样,对关键片段
的最后一个时间步的值。同样,对关键片段![]() 和值片段
和值片段![]() 进行类似的偏移量调整,得到
进行类似的偏移量调整,得到![]() 和
和![]() 。
。
- 计算相似性
使用皮尔逊相关系数 (Pearson’s correlation) 作为相似性度量函数![]() ,计算调整后 的输入片段
,计算调整后 的输入片段![]() 与所有调整后的关键片段
与所有调整后的关键片段![]() 之间的相似性。皮尔逊相关系数排除了尺度变化和值偏移的影响,专注于捕捉时间序列的上升和下降趋势。
之间的相似性。皮尔逊相关系数排除了尺度变化和值偏移的影响,专注于捕捉时间序列的上升和下降趋势。
相似性计算公式为:
![]()
- 检索最相似的关键片段
从所有关键片段中选择与输入片段最相似的 ![]() 个关键片段。这里
个关键片段。这里 ![]() 是一个超参数,表示检索的数量。定义索引集合
是一个超参数,表示检索的数量。定义索引集合 ![]() ,表示最相似的
,表示最相似的 ![]() 个关键片段的索引。
个关键片段的索引。
计算权重:使用 SoftMax 函数计算每个值片段的权重。权重计算公式为:
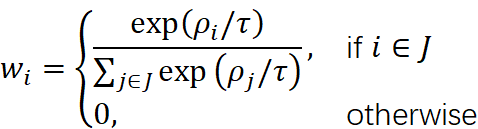
其中![]() 是温度参数,用于控制权重的分布。
是温度参数,用于控制权重的分布。
- 聚合值片段
最终的检索结果![]() 是通过加权求和的方式聚合最相似的关键片段对应的值片段得到的。聚合公式为:
是通过加权求和的方式聚合最相似的关键片段对应的值片段得到的。聚合公式为:
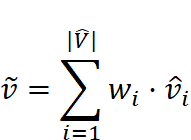
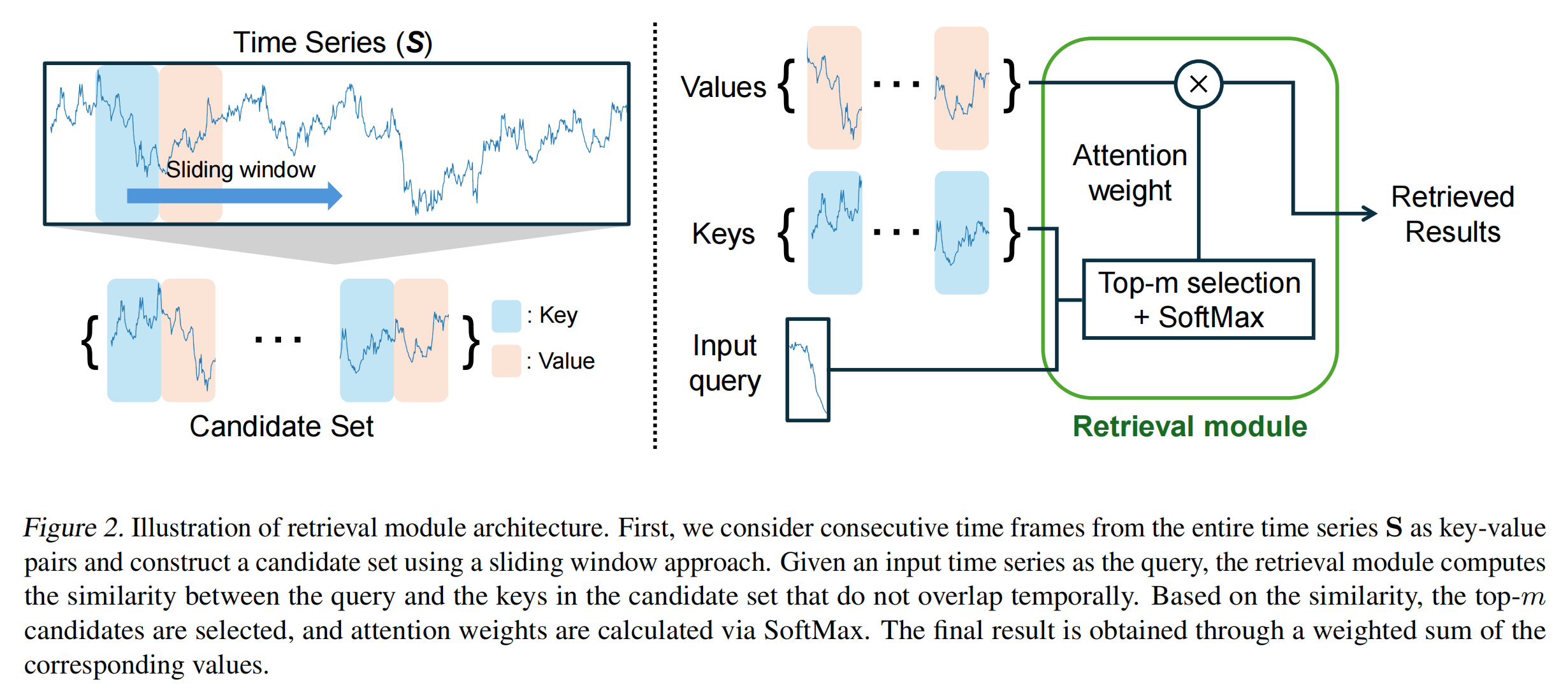
Figure 2 展示了检索模块的架构图,详细说明了从时间序列 S 中提取关键片段和值片段的过程,以及如何通过相似性计算和加权求和来生成最终的检索结果。
检索模块通过直接从历史数据中检索与输入最相似的模式,显式地利用这些模式的未来趋势信息,而不是依赖于模型权重中学习到的模式。这减轻了模型的学习负担,提高了预测的泛化能力。时间序列数据中可能存在复杂的、非平稳的模式,这些模式可能缺乏内在的时间相关性。检索模块能够找到与当前输入最相似的历史模式,并利用这些模式的未来趋势信息进行预测,从而更好地处理这些复杂模式。通过在多个周期上进行检索,RAFT 能够捕捉时间序列中的短期和长期模式,从而提高预测的准确性。
3.3 检索模块的结果与输入数据结合
- 单周期预测(Single Period Forecasting)
在单周期预测中,输入 ![]() 和检索到的片段
和检索到的片段 ![]() 被直接用于生成预测结果。具体步骤如下:
被直接用于生成预测结果。具体步骤如下:
1.输入预处理
对输入片段 ![]() 进行偏移量调整,去除最后一个时间步的值
进行偏移量调整,去除最后一个时间步的值![]() ,得到调整后的输入
,得到调整后的输入![]() :
:
![]()
2.检索模块的输出
检索模块输出的片段 ![]() 也经过相同的偏移量调整:
也经过相同的偏移量调整:
![]()
其中 ![]() 是
是 ![]() 的最后一个时间步的值。
的最后一个时间步的值。
3.特征融合
将调整后的输入 ![]() 和检索模块的输出
和检索模块的输出 ![]() 进行特征融合。具体来说,通过线性投影将它们映射到相同的特征空间,然后进行拼接:
进行特征融合。具体来说,通过线性投影将它们映射到相同的特征空间,然后进行拼接:
![]()
其中:![]() 和
和 ![]() 是线性投影函数,分别将
是线性投影函数,分别将 ![]() 和
和 ![]() 映射到相同的特征空间。
映射到相同的特征空间。 ![]() 表示特征拼接操作。
表示特征拼接操作。![]() 是最终的预测函数,通常是一个线性层,用于生成预测结果。
是最终的预测函数,通常是一个线性层,用于生成预测结果。
4.恢复偏移量
最后,将预测结果 ![]() 与输入片段
与输入片段 ![]() 的最后一个时间步的值
的最后一个时间步的值 ![]() 相加,恢复原始的偏移量,得到最终的预测结果
相加,恢复原始的偏移量,得到最终的预测结果 ![]() :
:
![]()
- 多周期预测(Multi-Period Forecasting)
在多周期预测中,时间序列在多个不同的周期上进行降采样,以捕捉不同时间尺度上的模式。具体步骤如下:
1.多周期降采样
对输入片段 ![]() 和整个时间序列
和整个时间序列 ![]() 在多个周期
在多个周期 ![]() 上进行降采样。每个周期
上进行降采样。每个周期 ![]() 的降采样方法是通过平均池化(average pooling)将时间序列的长度减少到
的降采样方法是通过平均池化(average pooling)将时间序列的长度减少到 ![]() 和
和 ![]() 。例如,对于周期
。例如,对于周期 ![]() ,降采样后的输入片段
,降采样后的输入片段 ![]() 和关键片段集合
和关键片段集合 ![]() 以及值片段集合
以及值片段集合 ![]() 的长度分别为
的长度分别为 ![]() 和
和 ![]() 。
。
2.多周期检索
对每个降采样后的时间序列 ![]() ,应用检索模块,检索与输入片段
,应用检索模块,检索与输入片段![]() 最相似的关键片段及其对应的值片段
最相似的关键片段及其对应的值片段 ![]() 。
。
3.特征融合与聚合
对每个周期 ![]() 的检索结果
的检索结果 ![]() 进行线性投影,将它们映射到相同的特征空间:
进行线性投影,将它们映射到相同的特征空间:
![]()
其中 ![]() 是针对周期
是针对周期 ![]() 的线性投影函数。 - 将所有周期的检索结果进行加权求和,得到聚合后的检索结果
的线性投影函数。 - 将所有周期的检索结果进行加权求和,得到聚合后的检索结果 ![]() :
:
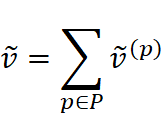
4.最终预测
将聚合后的检索结果 ![]() 与调整后的输入
与调整后的输入 ![]() 进行特征融合,生成最终的预测结果:
进行特征融合,生成最终的预测结果:
![]()
最后,恢复偏移量,得到最终的预测结果
![]()
- 损失函数
RAFT 使用均方误差(MSE)作为损失函数,通过最小化预测值![]() 和真实值
和真实值![]() 之间的差异来训练模型:
之间的差异来训练模型:![]() MSE
MSE![]() 。
。
4.实验
4.1 实验设置
- 数据集
作者选择了十个不同的时间序列预测基准数据集,这些数据集涵盖了多种领域和特征,具体如下:
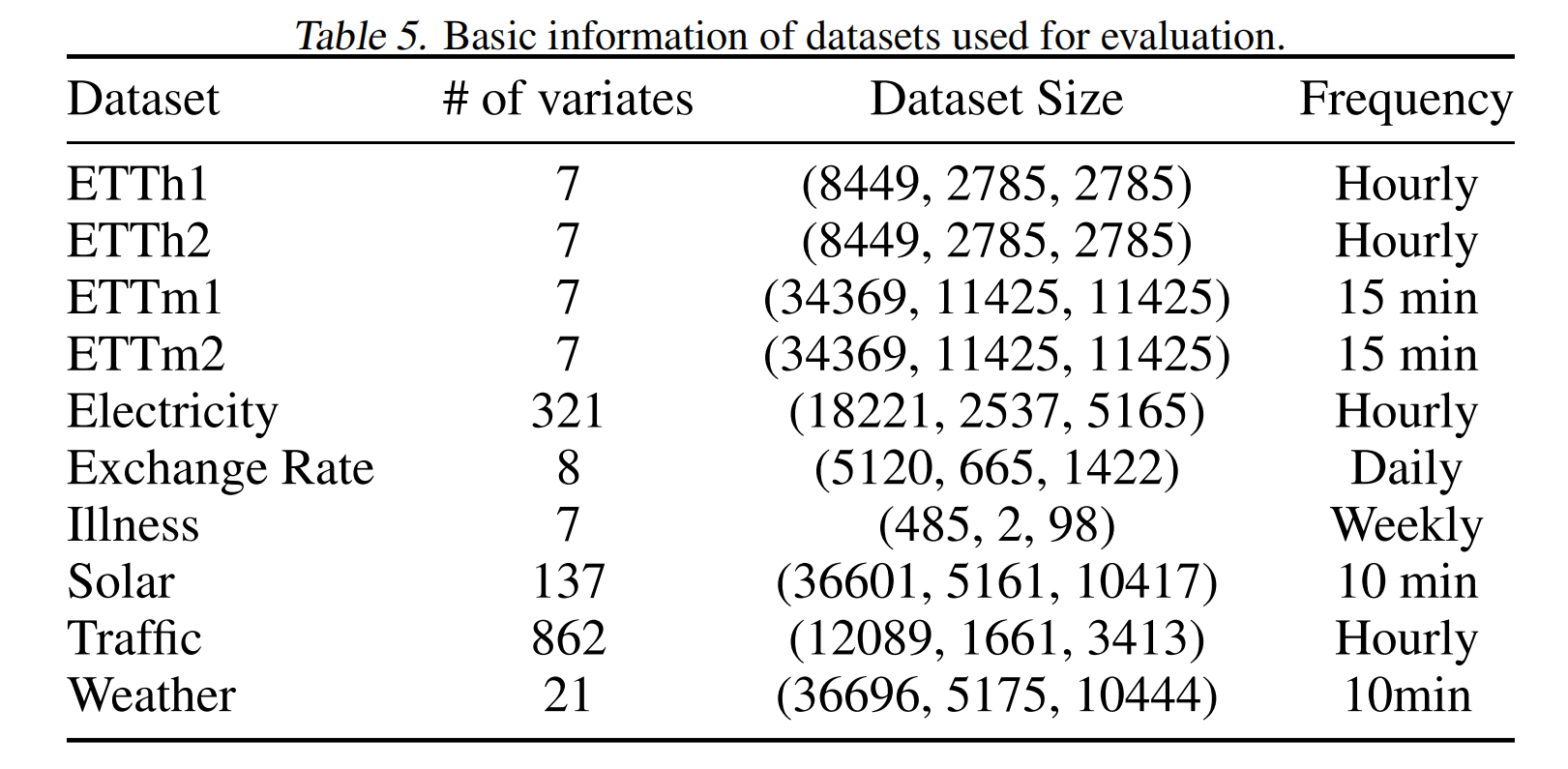
- ETT 数据集:包含两年的电力变压器温度数据,分为四个子集。
- Electricity 数据集:记录了大约四年的家庭用电功率消耗。
- Exchange Rate 数据集:包含27年(1990-2016)内八个国家的每日汇率。
- Ilness 数据集:记录了20年(2002-2021)内流感样疾病患者的比例。
- Solar 数据集:包含2006年从发电厂收集的10分钟太阳能功率预测。
- Traffic 数据集:包含48个月内高速公路的小时道路占用率。
- Weather 数据集:包含德国一年内的21个与天气相关的指标。
- 基线模型
为了评估 RAFT 的性能,作者选择了九个当代的时间序列预测基线模型,这些模型包括基于 Transformer 的架构、轻量级线性模型以及其他先进的方法:
- Autoformer (Wu et al., 2021):基于 Transformer 的架构,通过自相关机制进行时间序列分解。
- Informer(Zhou et al. 2021):高效的 Transformer 架构,使用ProbSparse 注意力模块。
- Stationary(Liu et al., 2022b):基于非平稳 Transformer 的模型。
- Fedformer(Zhou et al. 2022):频率增强的分解 Transformer。
- PatchTST(Nie et al., 2023):基于 Transformer 的架构,使用时间序列补丁。
- DLinear(Zeng et al. 2023):轻量级线性模型。
- MICN(Wang et al., 2023):通过卷积结构利用局部特征和全局相关性的模型。
- TimesNet(Wu et al., 2023):利用傅里叶变换分解时间序列数据的模块化架构。
- TimeMixer(Wang et al., 2024):利用分解和多周期性进行预测的模型。
- 实现细节
- 超参数设置:周期设置为 {1, 2, 4},遵循现有文献 (Wang et al., 2024);温度参数
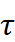 设置为 0.1;批大小设置为 32。学习率、回溯窗口大小
设置为 0.1;批大小设置为 32。学习率、回溯窗口大小 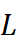 和 检索片段数量
和 检索片段数量 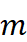 : 通过在验证集上进行网格搜索确定,以优化性能。
: 通过在验证集上进行网格搜索确定,以优化性能。 - 超参数选择:学习率从
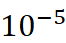 到 0.05 范围内选择。回溯窗口大小
到 0.05 范围内选择。回溯窗口大小 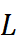 从 {96, 192, 336, 720} 中选择。检索片段数量
从 {96, 192, 336, 720} 中选择。检索片段数量 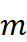 从 {1, 5, 10, 20} 中选择。
从 {1, 5, 10, 20} 中选择。
- 训练和评估:
- 使用公开的时间序列库 (TSLib) 进行实现。
- 每个实验在单个 NVIDIA A100 40GB GPU 上运行三次,报告平均结果。
- 评估指标
- 均方误差(MSE):用于评估预测值与真实值之间的差异。
- 平均绝对误差(MAE):用于评估预测值与真实值之间的平均绝对差异。
- 预测范围:在不同的预测范围(如 96、192、336、720)上评估性能。
- 多变量设置:输入和预测目标均包含多个通道。
4.2 实验结果
作者在十个不同的时间序列预测基准数据集上评估了 RAFT 的性能,并与其他九个当代基线模型进行了比较。这些数据集涵盖了多种领域,包括电力、经济、交通、天气等,具有不同的变量数量、数据长度和频率,具体结果如下:
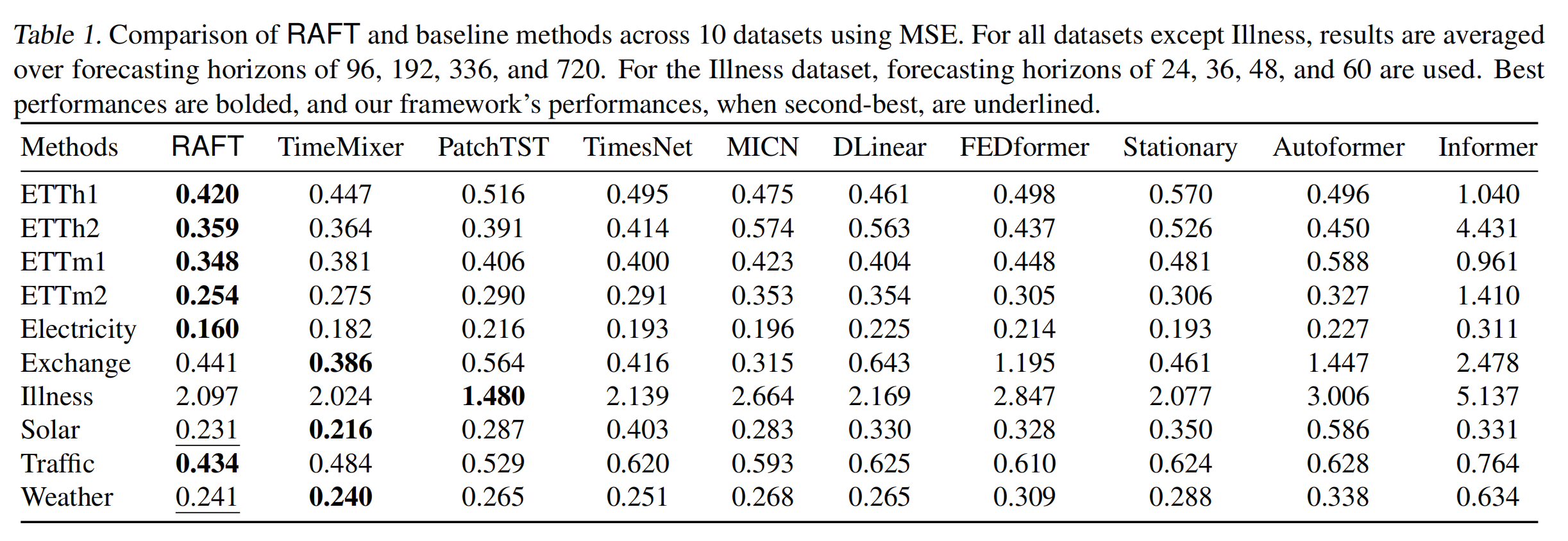
RAFT 在大多数数据集上均优于或接近所有基线模型,平均胜率(winratio)达到 86%。在某些数据集上(如 ETTh1、ETTh2、ETTm1、ETTm2等),RAFT 的性能提升尤为显著。
5.讨论
- 第一,检索的质量直接影响预测效果。输入片段与历史片段的相似度越高,其对应未来的走势也越接近真实未来,从而使预测更准确。因此,更好的检索结果意味着更好的预测性能。
- 第二,当某些模式在训练数据中很少出现时,模型难以记忆和学习。但如果这些罕见模式在预测时再次出现,检索模块能找到历史上相似的片段,并利用其未来走势,从而显著提升预测效果。
- 第三,在时间相关性较弱或近似随机的序列中,模型单靠学习难以捕捉规律。此时检索可以直接提供类似的历史片段作为参考,帮助模型降低学习难度并提升预测表现。
6.总结
6.1 研究贡献
- 提出 RAFT 方法:作者提出了一种新的时间序列预测方法--RAFT(Retrieval-Augmented Forecasting of Time-series)。 RAFT 通过从训练数据中检索与当前输入片段最相似的历史模式,并利用这些模式的未来趋势信息来辅助预测。
- 检索模块的优势:
- 减轻学习负担:通过检索模块,RAFT 直接利用历史数据中的相似模式,减少了模型在训练过程中需要学习的模式数量,从而减轻了学习负担。
- 提升泛化能力:RAFT 能够捕捉到时间序列中的复杂模式,即使这些模式在训练数据中不常见,也能通过检索历史数据中的相似模式来辅助预测,从而提升了模型的泛化能力。
- 实验验证:通过在十个不同的时间序列预测基准数据集上的实验,作者证明了 RAFT 在性能上优于现有的基线模型,平均胜率达到 86%。此外,作者还通过合成数据实验验证了检索模块在处理稀有模式和时间相关性较低的模式时的有效性。
- 适用性:作者进一步验证了检索模块在提升 Transformer 变体(如AutoFormer)性能方面的有效性,表明检索模块可以作为一种通用的增强手段,应用于不同的模型架构中。
6.2 研究局限性
- 检索技术的改进空间:尽管 RAFT 在多个数据集上表现出色,但作者指出现有的检索技术仍有改进空间。例如,可以探索更复杂的相似性度量方法,以更好地捕捉时间序列中的非线性和非平稳特性。
- 计算效率:检索模块的计算复杂度较高,尤其是在处理大规模数据集时。作者提到,可以通过优化检索算法(如增加滑动窗口的步长)来提高计算效率,但这也可能会影响检索结果的准确性。
- 数据集特性的影响:RAFT 的性能在不同数据集上存在差异,这表明数据集的特性(如模式的复杂性、稀有性等)对检索模块的效果有显著影响。未来的研究可以进一步探索如何根据数据集的特性选择合适的检索策略。
6.3 未来研究方向
- 改进检索技术:研究更高效的检索算法,以提高检索模块的计算效率同时保持或提升检索结果的准确性。
- 探索新的相似性度量:开发能够更好地捕捉时间序列中非线性和非平稳特性的相似性度量方法,以进一步提升检索模块的性能。
- 结合其他模型架构:探索将检索模块与其他先进的模型架构(如深度学习模型、混合模型等)结合的可能性,以进一步提升时间序列预测的性能。
- 应用到更多领域:将 RAFT 方法应用到更多实际领域(如金融、医疗气象等),验证其在不同应用场景中的有效性和适用性。

















 481
481

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









