



Motivation动机&Challenge&挑战:
基于会话的推荐是基于用户当前会话的前一个操作来预测用户的下一个操作。主要的挑战是在整个会话中获取真实和完整的用户偏好。
在这里,我们可以首先看一下Sequential Recommendation (SR) & Session-Based Recommendation(SBR)最主要的区别,可以这么理解的:
① 匿名性。 在SR中,我们是知道用户的信息的,即用户是登录状态下访问的系统,这时候我们可以利用用户丰富的信息(user profile)来抽取其偏好,比如我们知道用户的年龄,地域,性别,职业等等,可以根据这些来辅助模型提供更精确的推荐。而在SBR中,我们是不知道用户的信息的,即用户是匿名的,比如用户未登录系统,就是在网站上逛逛,这时候我们是无法利用用户信息来建模的。
② 序列的长短。由于SR中存在用户的标识(ID),系统就可以记录其长时间的历史行为,根据历史行为来做出推荐。而SBR中由于没有用户的ID,相对来说记录行为的时长就比较短,比如就只能记录浏览器session过期这段时间内用户的行为。一般来时,SR中的序列长度要长于SBR的长度。
③ 以上两点也是session-based recommendation的难点,即匿名无法使用用户信息,序列长度短,可供建模的行为有限。可以看看以下几篇不错关于session-based recommendation的综述文章,更加深入的了解session推荐。
最近对于会话推荐的研究较多利用图结构表示整个会话,并采用图神经网络(GNN)对会话信息进行编码。这种建模选择被证明是有效的,并取得了显著的效果。然而,现有的研究大多只对会话中的每个项目进行独立的考虑,而没有从高层次的角度对会话语义进行研究。这种限制常常导致严重的信息丢失,并增加了在会话中捕获远程依赖关系的难度。
直观地说,与单个项目相比,一个会话片段(即一组本地连续的项目)能够提供灵活的用户意图,这是现有方法很难捕捉到的。
SOAT的做法:
本文针对会话推荐方向,相较于关注序列中的单个商品,本文关注如何利用GNN从连续片段中捕获用户偏好。通过多粒度连续用户意图单元捕获用户兴趣,作者提出了多粒度意图异构会话图(MIHSG),它捕获了不同粒度意图单元之间的交互并减轻了长依赖的负担。此外,作者提出了意图融合排名(IFR)模块来组合来自各种粒度用户意图的推荐结果。
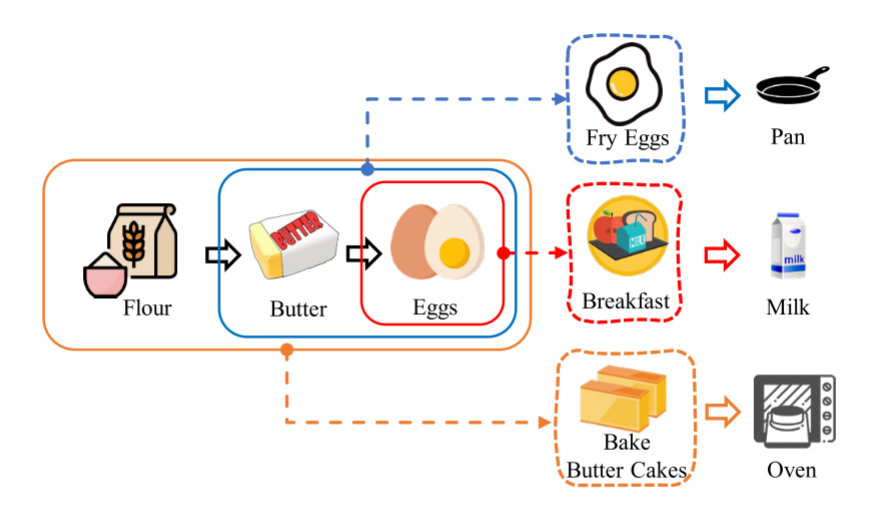
上图展示了三种力度的level-1/2/3的session,虚框中代表session的意图,箭头后面是下一步的推荐结果
ACT&方案
提出了多粒度意图异构会话图(MIHSG),它捕获了不同粒度意图单元之间的交互,减轻了长依赖的负担。此外,还提出了意图融合排序(IFR)模块来组合不同粒度用户意图的推荐结果。与目前仅利用单个条目意图的方法相比,IFR从不同粒度的用户意图中获益,从而产生更精确、更全面的会话表示,从而最终提高推荐性能。本文采用了异构会话图,GNN/RNN的一些思想。
模型结构
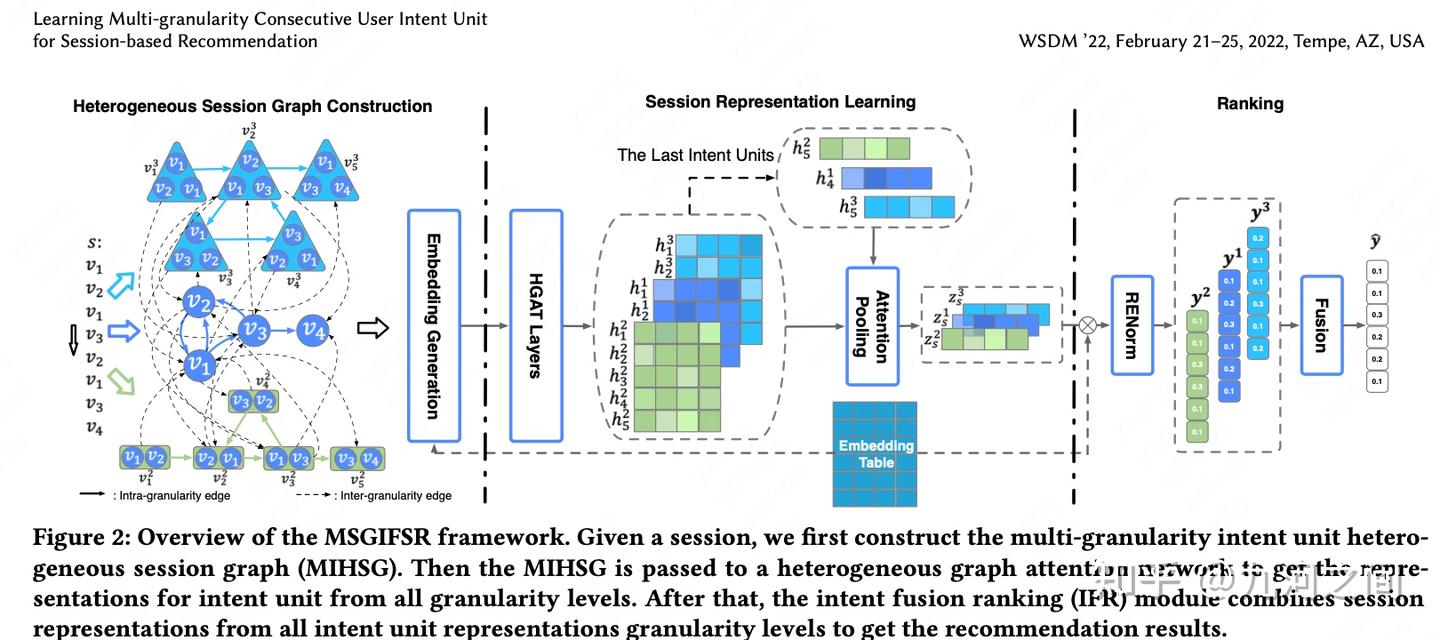
MIHSG结构
问题定义
令表示所有的商品的集合,会话表示为
,其中L是会话长度,
表示在位置i时商品的id。目的是给定si后,预测
连续意图单元
现存的会话推荐的方法更多的关注会话中的那个商品,而忽略了会话所能反映的更高级别的用户意图。本节所提方法不仅学习单个商品所表达的意图,还学习了连续片段中商品的组合意图。令表示一个连续片段,从第j个开始,长度为k。k表示连续意图捕获的粒度大小。
对于给定的会话s,用表示粒度为1的embedding,也就是单个商品的embedding,对于粒度级别为k的片段,用函数R来对片段内的商品embedding进行聚合,公式如下,
这部分考虑两类函数R,产生两类表征,即基于集合和基于序列来生成高级意图单元的表示。一方面,基于集合的聚合函数,例如MEAN、MAX 等可以提取顺序不变的意图;另一方面,基于序列的函数,例如Gate Recurrent Unit (GRU) 可以提取顺序敏感的意图。然后将两类表征相加,公式如下(Tips: K表示Session中元素个数,即粒度),即图中的Embedding Generation
MIHSG的构建
MIHSG 由多个子图组成,每个子图对同一级别连续意图单元的意图之间的转换进行建模。由 level- 连续意图单元构建的图被定义为 level- 意图会话图。level-k意图会话图,level-k表示粒度为k的情况。
level-k会话图捕获了用户-商品交互的空间连续性。他是有向图,每个节点代表一个level- 连续意图单元的意图,每条边连接两个连续相邻level- 连续意图单元。如果节点在会话序列中相邻,则它们具有连接。 level-1会话图捕获商品之间的细粒度意图转换。随着意图单元长度的增加,会话图包含意图单元之间的更高级别的转换模式。
MIHSG
将上述构建的不同粒度的会话图整合后,构建统一的异构会话图,MIHSG。这里引入一种边,命名为粒度间的边(inter-granularity edge),用这种边链接不同粒度的会话图和粒度为1的连续会话图。
例子:在会话 = { 1, 2, 1, 3} 中,可以构造两个粒度间的边。它们是 ( 1, inter, ( 2, 1)) 和 ( ( 2, 1), inter, 3)。这可以捕获跨粒度级别的意图转换模式。 上述例子中的(v2,v1)就是通过2.2节学习到的表征。
会话表征学习
学习连续意图单元的表征
使用HGAT对有向图的节点表征进行学习。对于有向边(s, e, t),s是源节点,t是目标节点,e是边,粒度为k的节点可以表示为ks,kt,令ϕe表示边的类型。对于一个粒度为k的MIHSG,。对于每一层,利用双向注意力机制,聚合出近邻和入近邻的表征。以入近邻为例,令
表示节点入近邻的节点集合。聚合公式如下,其中w和a是可学习参数,在不同层不共享。
是意图到单元的初始表征,σ为leakyrelu函数。
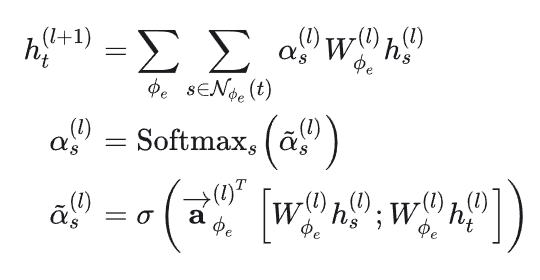
上述过程采用多头注意力机制,并采用取最大值而不是均值或拼接,公式如下,h是每个头,R是取最大。

利用HGAT对入近邻和出近邻分别进行聚合后,可以得到两类embedding和
,节点v的局部表征表示为上面两者的和
,其最终表征为局部表征和会话中所有表征的均值的和
学习整个会话的表征
会话表征的计算不是在图上计算,而是在划分的k粒度的片段上计算。令每个片段的表征为,nk表示每个级别粒度的片段的数量,K表示所有可能的粒度级别。对于每个级别的连续意图单元,生成局部表征zlk和全局表征zgk来反映用户偏好。用该级别中最后一个单元
(即,最后的片段)作为
,结合软注意力机制计算得到
。为了使每个级别的会话表征捕获完整的用户意图,文中组合所有意图单元的embedding以生成上下文集合
表示其中过的元素。全局表征计算公式如下,主要就是通过注意力机制加权,这里不赘述。
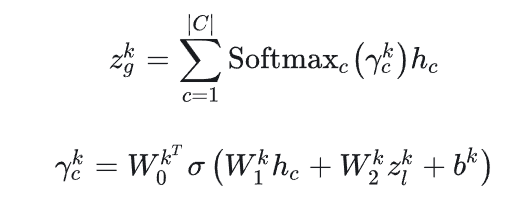
粒度为k的用户偏好表征计算公式为,
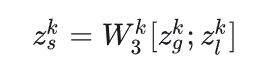
意图融合排序和优化(RENorm: Repeat-Explore Normalization)
根据上面的计算得到不同粒度的偏好表征后,,利用意图融合排序来捕获更全面的用户偏好。
首先在分别对不同级别粒度单独计算,对于每个粒度为k的意图,采用内积计算候选商品意图和粒度为k的会话表征之间的是相似度,公式如下,
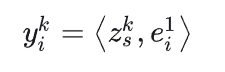
考虑复购和探索问题,文中将会话中的商品和会话外的商品区分开,分别对计算得到的y采用softmax,公式如下,
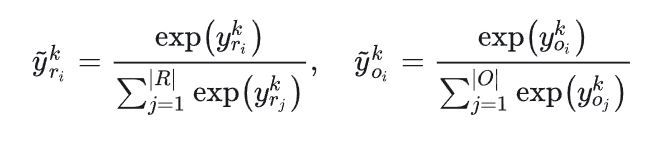
其中R是会话内的商品的集合,O是会话外的商品的集合,|I|=|O|+|R|。因为在会话内的,可能会有重复点击,将会话内外的区分开,能一定程度上考虑到复购和探索问题。
通过加权来平衡重复点击和探索点击,公式如下,
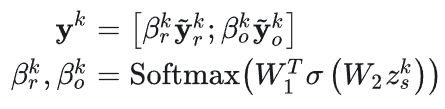
意图融合排名(IFR)
融合所有粒度级别的意图预测的推荐结果。引入一个加权求和算子来融合各级意图生成的概率分布,以生成最终的概率分布 y,公式如下,其中α是可学习参数,相当于对α进行标准化后加权。
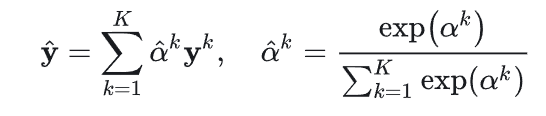
最后损失函数采用交叉熵损失函数。
Results and Conclusion
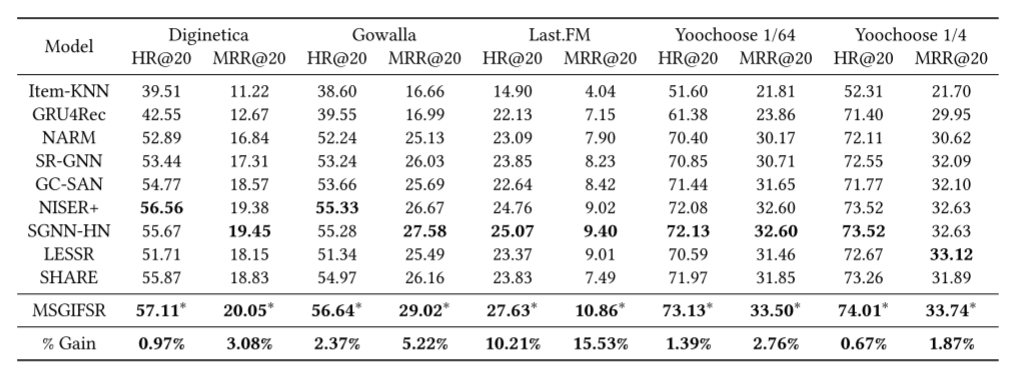
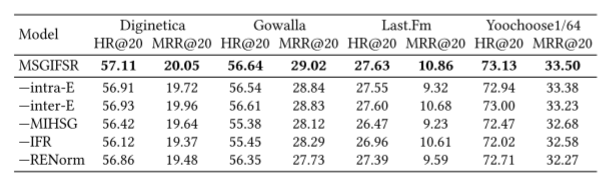
本文研究了基于会话的推荐问题,提出了一种提取会话中不同意图粒度信息的新模型MSGIFSR。可以看出,不同的连续组合意图粒度提供了更丰富的用户偏好,提出的MIHSG通过建模粒度内和粒度间的意图单元边缘,成功地捕获了多层次连续意图单元之间的复杂偏好转换关系和长程依赖关系。此外,意图单元编码器机制考虑了一组项目的顺序变化和顺序不变关系,这有利于表示意图单元的含义。最后消融研究表明,意图融合排名模块成功地整合了来自所有意图单位级别的建议结果。

















 393
393

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









