



优化论(Optimization Theory)是数学和计算机科学中一个重要的分支,旨在寻找给定问题的最优解。这个领域的应用非常广泛,从经济学、工程学到机器学习、金融等各个领域都有其踪迹。我们可以通过一系列直观的比喻来理解优化论的基本概念和技术细节。
基本概念
1.目标函数(Objective Function):
比喻:想象你在一个山谷里徒步旅行,目标是找到山谷中最低的点(或山峰的最高点)。目标函数就像这座山谷的地形图,它告诉你每个点的海拔高度。优化的目标是找到这个地形图上的最低点或最高点。
技术细节:目标函数通常表示为![]() ,其中
,其中![]() 是变量向量,
是变量向量,![]() 是目标函数在
是目标函数在 ![]() 处的值。
处的值。
2.决策变量(Decision Variables):
比喻:在徒步旅行的例子中,决策变量就像是你当前所在的位置的坐标(比如横坐标和纵坐标)。这些变量决定了目标函数的值。
技术细节:决策变量可以是一个或多个,表示为向量![]()
3.约束条件(Constraints):
比喻:假设你在徒步旅行中有一些限制,比如不能穿过河流或者必须保持在某个路径上。约束条件就是这些限制,规定了哪些路径是可行的,哪些是不允许的。
技术细节:约束条件可以是等式或不等式,限制了决策变量的取值范围。
优化问题的分类
1.线性规划(Linear Programming, LP):
比喻:如果地形是由平坦的平面组成,那么寻找最低点就变得简单了,因为每个路径都是直线。线性规划就是这样的一类问题,目标函数和约束条件都是线性的。
2.非线性规划(Nonlinear Programming, NLP):
比喻:如果地形是复杂的,有山有谷,那么寻找最低点就变得困难。非线性规划就是这样的一类问题,目标函数或约束条件是非线性的。
3.整数规划(Integer Programming, IP):
比喻:假设你只能站在地图上的格点上(比如网格上的交点),不能站在两点之间的位置。整数规划就是这样的问题,决策变量只能取整数值。
技术细节:整数规划的问题形式类似于线性或非线性规划,但要求 x 的所有分量都是整数。
优化方法
1.梯度下降法(Gradient Descent):
比喻:在山谷中寻找最低点时,你可以沿着当前所在位置的最陡下降方向走。梯度下降法就是基于这样的原理,每一步都沿着目标函数的梯度方向移动。
技术细节:梯度下降法的更新公式为:
![]()
其中![]() 是步长,
是步长,![]() 是目标函数在
是目标函数在![]() 处的梯度。
处的梯度。
2.牛顿法(Newton’s Method):
比喻:牛顿法不仅考虑了当前的斜率,还考虑了地形的曲率,就像是使用地形的二阶信息来更快地找到最低点。
技术细节:牛顿法的更新公式为:
![]()
其中![]() 是目标函数在
是目标函数在![]() 处的Hessian矩阵。
处的Hessian矩阵。
约束优化算法是一类专门处理目标函数在存在约束条件下求解最优解的方法。为了更好地理解约束优化算法,我们需要了解一些核心概念和基本方法。
约束优化的核心概念
1.可行域(Feasible Region):
比喻:想象你在一个园艺场里种植不同种类的植物,但只有特定区域可以种植。可行域就是这些允许种植的区域。
2.拉格朗日乘子法(Lagrange Multipliers):
比喻:假设你在调整种植区域时,既想保持植物健康生长(目标函数),又要遵循园艺场的规定(约束条件)。拉格朗日乘子法就像在这两者之间找到一个平衡点。
常用的约束优化算法
1.罚函数法(Penalty Method):
比喻:罚函数法就像在种植区域外种植植物时会受到罚款,这样你会尽量保持在可行域内。
2.障碍函数法(Barrier Method):
比喻:障碍函数法就像在可行域边界设置了障碍物,防止你越过边界。
3.拉格朗日乘子法(Lagrangian Method):
比喻:拉格朗日乘子法就像同时调整种植区域和遵守规定的权重,使两者达到平衡。
实例
我们需要最小化函数![]() 并且满足约束条件
并且满足约束条件![]()
罚函数法
1.构造罚函数:
首先,我们将约束条件转换为一个惩罚项。对于约束条件![]() 我们可以构造以下罚函数:
我们可以构造以下罚函数:![]()
这里,我们使用平方形式来确保任何违约束的情况都会被显著地惩罚。
2.构造新的目标函数:
将惩罚项加入到目标函数中,形成新的目标函数:![]()
其中![]() 是一个正的罚参数,用来调整惩罚项的权重。
是一个正的罚参数,用来调整惩罚项的权重。
3.求解优化问题:
我们的目标是找到使新的目标函数![]() 最小的
最小的![]() 和
和![]() 值。
值。
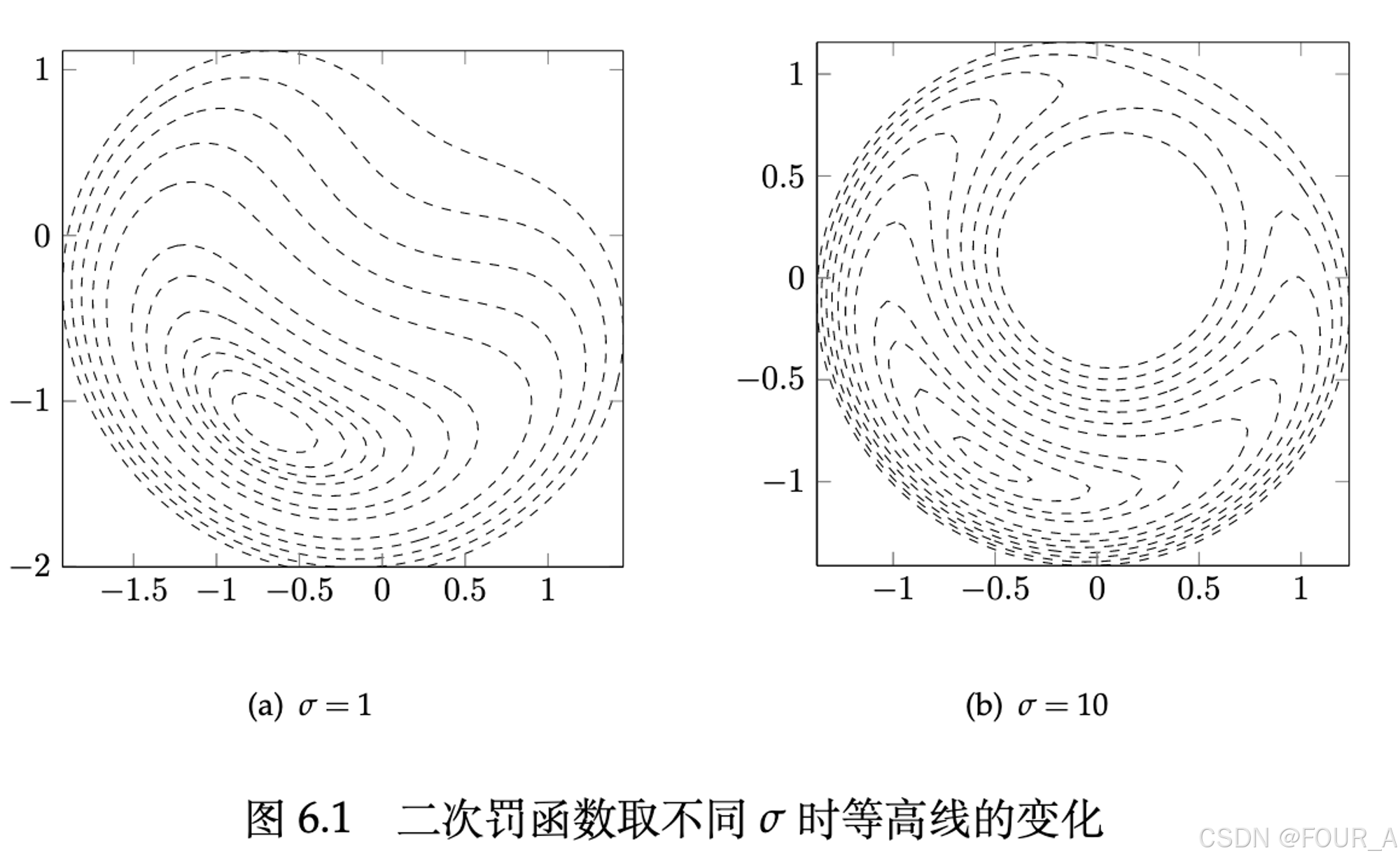
这两个图展示了二次罚函数在不同罚参数 ![]() 值时的等高线图。等高线图是一种展示三维地形的方法,其中每条线表示函数值相同的点的集合。
值时的等高线图。等高线图是一种展示三维地形的方法,其中每条线表示函数值相同的点的集合。
左图 (a)![]() =1
=1
这个图显示了当罚参数 ![]() =1 时的情况。等高线显示目标函数在不同点的值分布,等高线较为平滑,表明目标函数值的变化较为缓慢,罚函数的影响较小。
=1 时的情况。等高线显示目标函数在不同点的值分布,等高线较为平滑,表明目标函数值的变化较为缓慢,罚函数的影响较小。
右图 (b)![]() =10
=10
这个图显示了当罚参数![]() =10时的情况。我们可以看到等高线的形状和分布与左图有明显的不同,等高线变得更为密集和复杂,表明目标函数值在靠近约束边界时变化迅速,罚函数的影响显著增加。
=10时的情况。我们可以看到等高线的形状和分布与左图有明显的不同,等高线变得更为密集和复杂,表明目标函数值在靠近约束边界时变化迅速,罚函数的影响显著增加。
罚函数的作用
罚函数的目的是将违反约束条件的解显著地惩罚,使得优化过程更倾向于在可行域内找到最优解。罚参数 ![]() 控制了这个惩罚的强度。
控制了这个惩罚的强度。
低罚参数 ![]() = 1:惩罚强度较低,等高线分布较为平缓。违反约束条件的解不会受到很大的惩罚,因此优化过程可能会在可行域外找到较低的函数值点。
= 1:惩罚强度较低,等高线分布较为平缓。违反约束条件的解不会受到很大的惩罚,因此优化过程可能会在可行域外找到较低的函数值点。
高罚参数 ![]() = 10 :惩罚强度较高,等高线分布较为陡峭。违反约束条件的解会受到显著的惩罚,因此优化过程更倾向于在可行域内找到最优解。
= 10 :惩罚强度较高,等高线分布较为陡峭。违反约束条件的解会受到显著的惩罚,因此优化过程更倾向于在可行域内找到最优解。
为了更好地理解这个图,让我们回顾一下罚函数法的目标函数形式:
![]()
原始目标函数:![]()
罚函数:![]()
随着![]() 的增加,罚函数的影响变得更加显著。这意味着在优化过程中,违反约束条件
的增加,罚函数的影响变得更加显著。这意味着在优化过程中,违反约束条件![]() 的点会被显著地惩罚,使得优化算法更倾向于找到满足约束条件的最优解。
的点会被显著地惩罚,使得优化算法更倾向于找到满足约束条件的最优解。
直观解释
想象你在平地上行走(左图 (a)),地面比较平坦,因此你可以随意移动。但是,当地面上突然出现很多山谷和山峰(右图 (b)),你就会倾向于沿着较为平坦的区域移动,以避免爬山或下谷。高罚参数![]() 就像这些山谷和山峰,迫使你在可行域内找到最优路径。
就像这些山谷和山峰,迫使你在可行域内找到最优路径。
总结
低罚参数![]() 使得优化过程在可行域外也能找到较低的目标函数值点,但可能不满足约束条件。
使得优化过程在可行域外也能找到较低的目标函数值点,但可能不满足约束条件。
高罚参数![]() 强制优化过程在可行域内找到最优解,因为违反约束条件的点会被显著惩罚。
强制优化过程在可行域内找到最优解,因为违反约束条件的点会被显著惩罚。

收敛准则
收敛准则是用来决定优化算法何时停止迭代的标准。常见的收敛准则包括以下几种:
1.目标函数值变化很小:
如果在连续的迭代中,目标函数的值变化很小(小于某个阈值),则认为算法已收敛,可以停止迭代。
2.梯度值很小
如果目标函数的梯度(或导数)值很小,表示已经到达了极值点附近,则可以停止迭代。
3.迭代次数达到上限:
如果迭代次数达到了预先设定的最大迭代次数,则停止迭代。

















 2904
2904

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









