





📢 欧洲准备改写互联网规则:科技巨头被迫拆掉围墙
https://www.wired.com/story/europe-dma-prepares-to-rewrite-the-rules-of-the-internet/
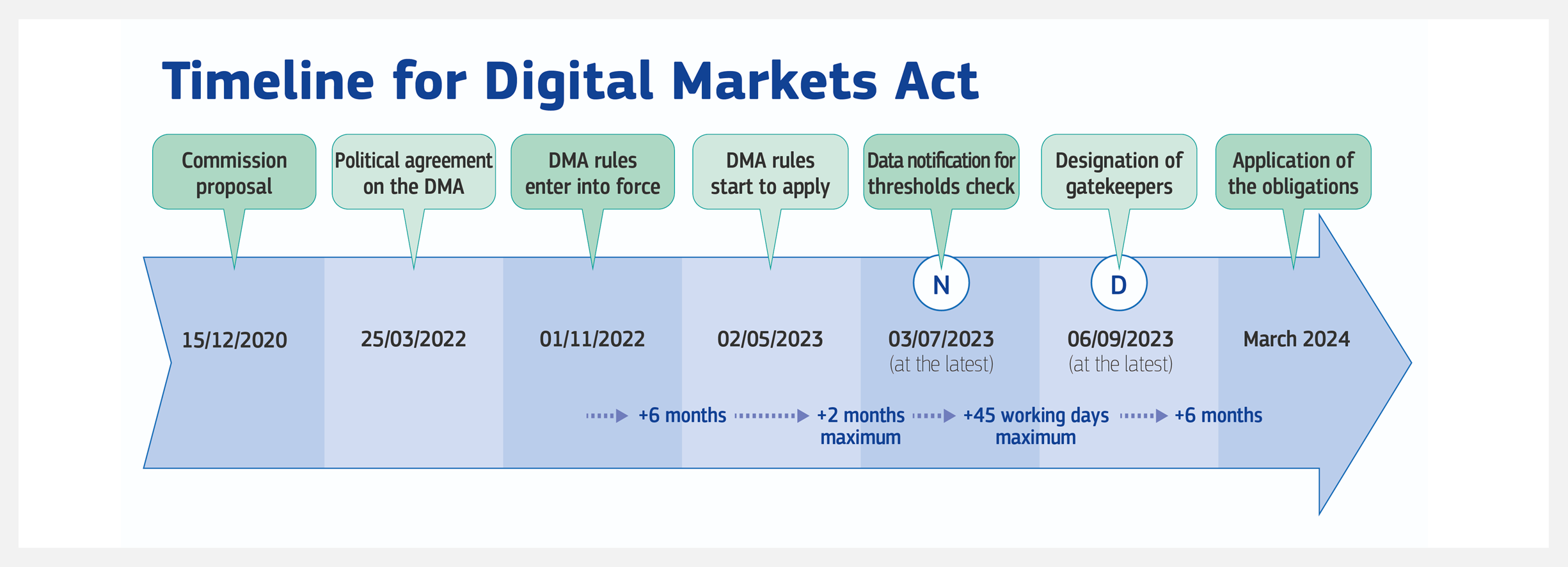
11 月 1 日,欧盟的《Digital Markets Act (数字市场法)》开始生效,要求占主导地位的平台让较小的竞争对手进入,并且迫使 WhatsApp 接收来自 Signal 或 Telegram 等竞争应用程序的消息,或者阻止亚马逊、苹果、谷歌优先使用他们自己的应用程序和服务。
欧盟将在春季宣布“gatekeepers (守门人)”名单——即那些规模大、地位稳固、受最严格规则约束的公司。分析师预测这个名单有12家左右公司,包含亚马逊、谷歌和 Meta等互联网巨头。
法案将给设备使用和应用程序操作带来重大变化,简而言之,互联网巨头在 2023 年将更加开放,被迫拆掉围墙。同时欧盟也在考虑通过有关人工智能的具体条款,包括禁止AI技术的滥用。
工具&框架
🚧 『Private Detector』开源色情图像检测引擎
https://github.com/bumble-tech/private-detector
Private Detector 是一个开源色情图像检测引擎,可以精准地对色情图像进行分类检测和模糊,并在用户打开照片之前向他们发送相关警告,可以应用于各种内容审核场景。这原本是 Bumble 公司的一个内部项目,在进行大量的重构后作为一个完全开源的项目发布。
🚧 『Pyxel』Python经典像素风游戏制作引擎
https://github.com/kitao/pyxel
Pyxel 是一个 Python 的经典像素风游戏制作引擎。像素风游戏的机制非常简单(如:最多只能显示 16 种颜色、播放 4 种声音等),通过Pyxel你也可以轻松地享受这种游戏的制作过程。

🚧 『flashlight』快速、灵活的C++机器学习库
https://github.com/flashlight/flashlight
flashlight 是一个快速灵活的 C++ 机器学习库,由 Facebook AI 研究语音团队及 Torch 和 Deep Speech 的创作者用 C++ 编写,支持机器学习算法及语音、视觉目标检测、语言模型等应用。
🚧 『ROLAND』动态图图学习框架
https://github.com/snap-stanford/roland
ROLAND是动态图图学习框架,具有以下特点:
- GNN的高度模块化
- 数据:数据加载,数据分割
- 模型:模块化的GNN实现
- 任务:节点/边缘/图层面的GNN任务
- 评估:准确度,ROC AUC,…
- 可重复的实验配置
- 每个实验都由一个配置文件完全描述
- 可扩展的实验管理
- 轻松启动数以千计的GNN平行实验
- 自动生成跨随机种子和实验的实验分析和数字。
- 灵活的用户定制
- 在graphgym/contrib/中轻松构建注册自定义模块,如数据加载器、GNN层、损失函数等。
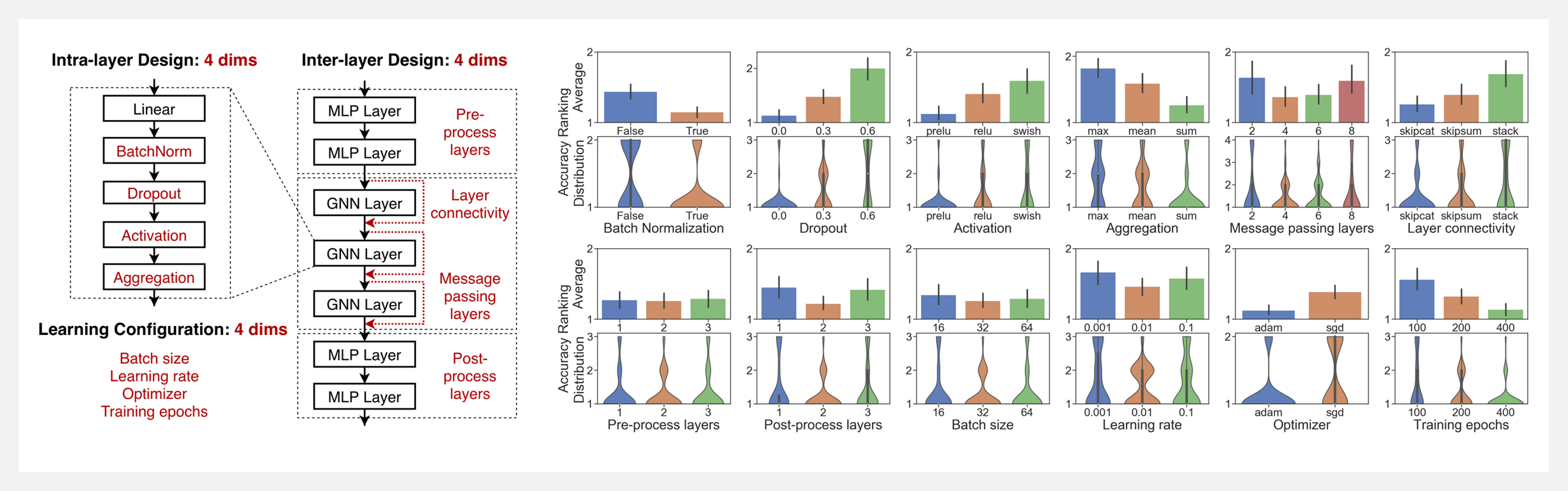
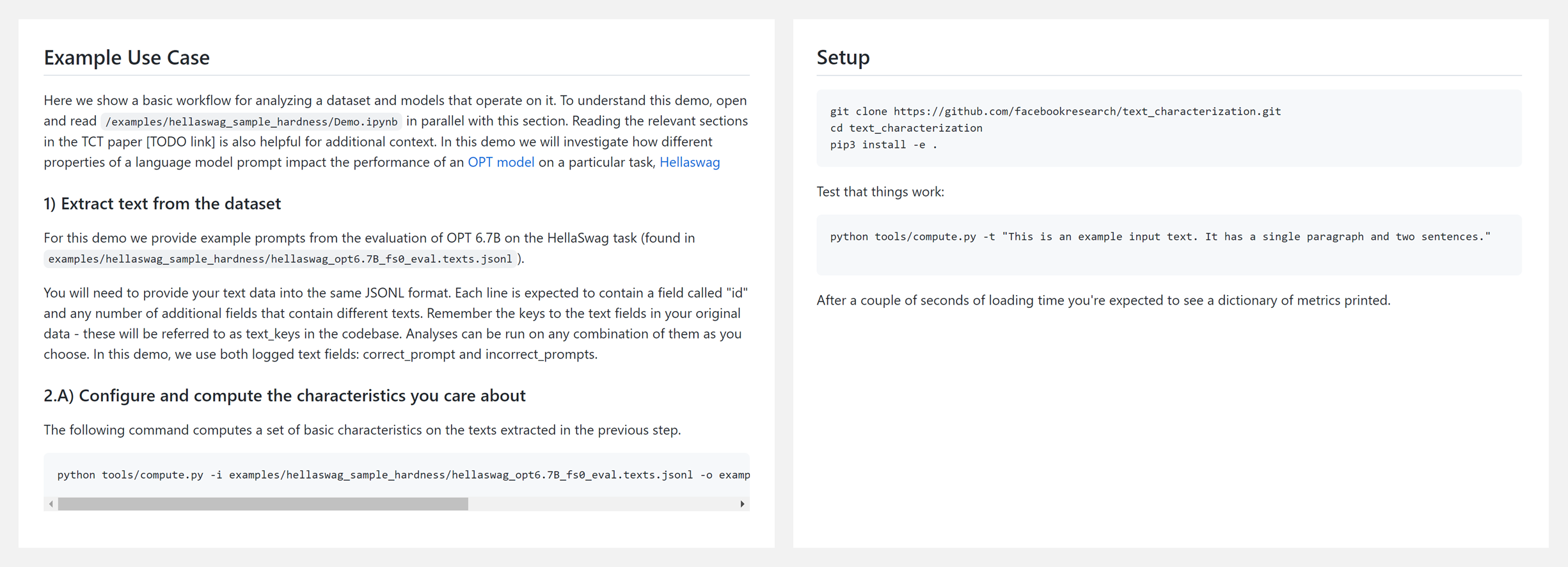
🚧 『Data Characterization Toolkit』用于计算各种文本特性并用它们轻松分析数据集和模型的库
https://github.com/facebookresearch/text_characterization_toolkit
博文&分享
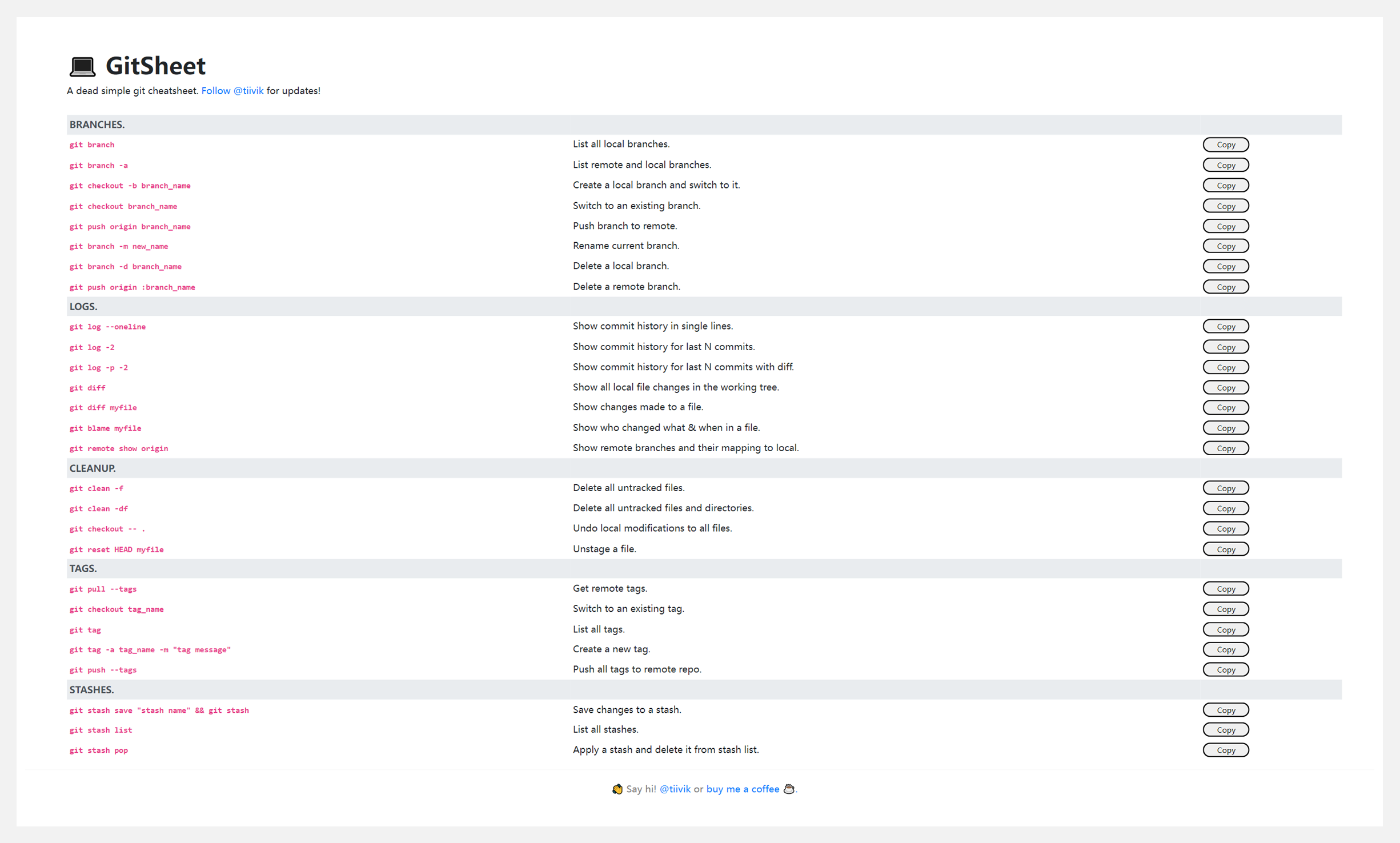
👍 『GitSheet』git常用命令速查
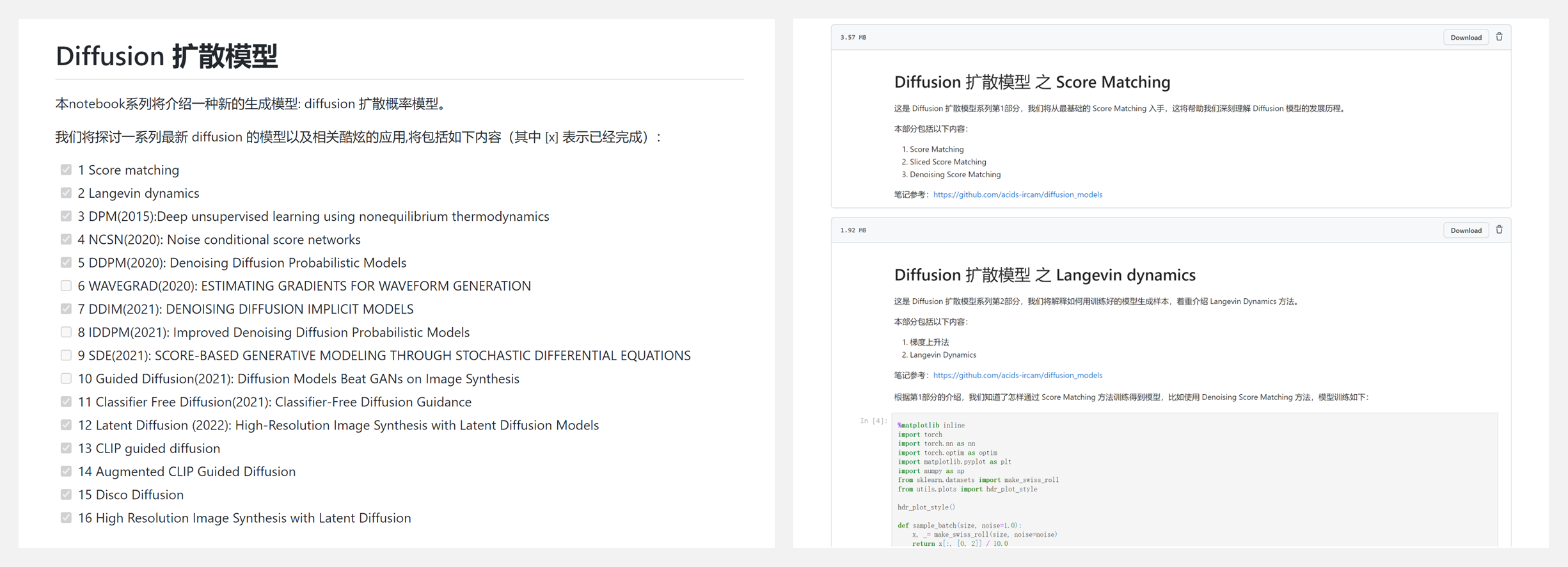
👍 『Diffusion』扩散模型实例教程集 (Notebooks)
https://github.com/sunlin-ai/diffusion_tutorial
本项目本介绍目前主流的生成模型——diffusion 扩散概率模型,包括 Score matching、Langevin dynamics、CLIP guided diffusion、Augmented CLIP Guided Diffusion、Disco Diffusion等。
数据&资源
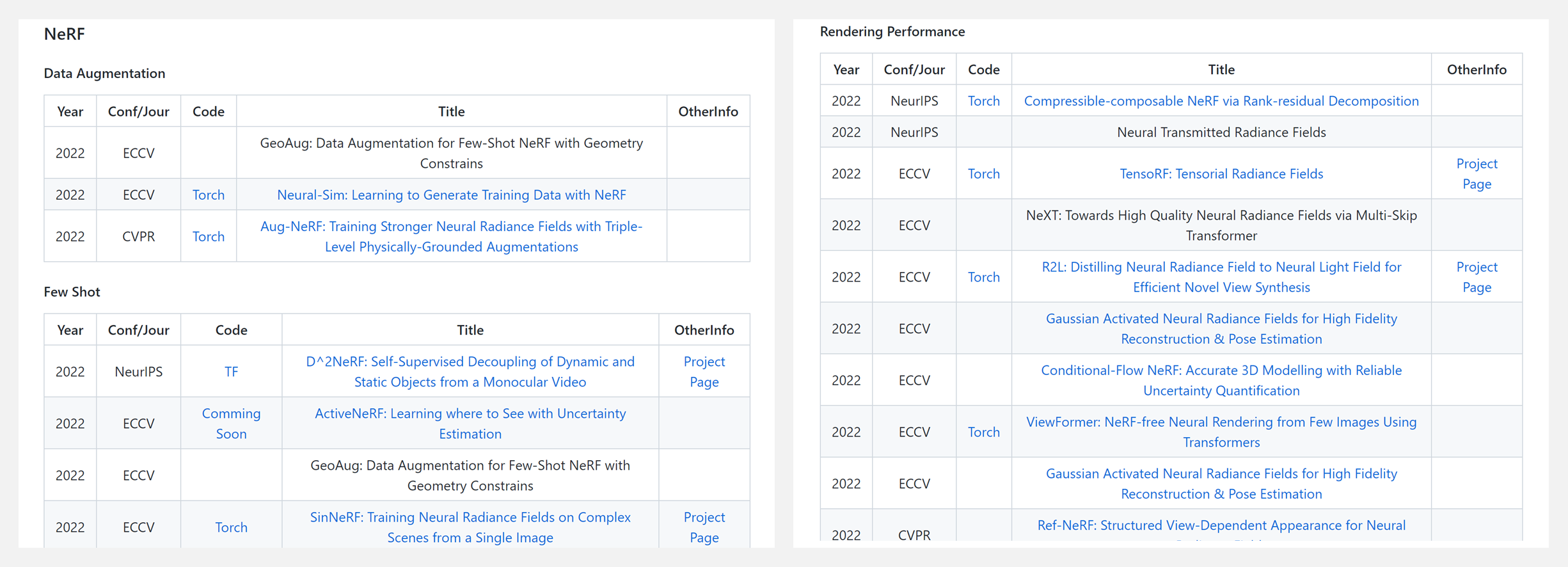
🔥 『Awesome Neural Radiance Fields (NeRF) 』神经辐射场(NeRF)相关文献资源列表
https://github.com/koolo233/awesome-NeRF
这是一份精选的神经辐射场 (NeRF) 论文列表。所有论文都根据关键字/任务分组,并按年份排序。汇总包含以下主题,希望这篇可以帮助有兴趣进行 NeRF 相关研究的同行:
- NeRF
- Data Augmentation
- Few shot
- Rendering Performance
- Theory
- Training & Inference Efficiency
- NeRF Related Tasks
- Deblur & Denoise
- Depth Estimation
- Editing
- Face
- High Dynamic Range (HDR)
- Human
- Image Generation
- Image Generation
- Text & Image Guided Generation
- Large Scale Scene
- Pose Misalignment
- Reinforcement Learning
- Relighting
- Segmentation
- Stylized
- Surface Reconstruction
- Video
- View Synthesis Extrapolation
研究&论文

科研进展
- 2022.10.11 『点云分类』 Point Transformer V2: Grouped Vector Attention and Partition-based Pooling
- 2022.10.13 『语言建模』 M2D2: A Massively Multi-domain Language Modeling Dataset
- 2022.10.0 『问答』 Towards a Unified Multi-Dimensional Evaluator for Text Generation
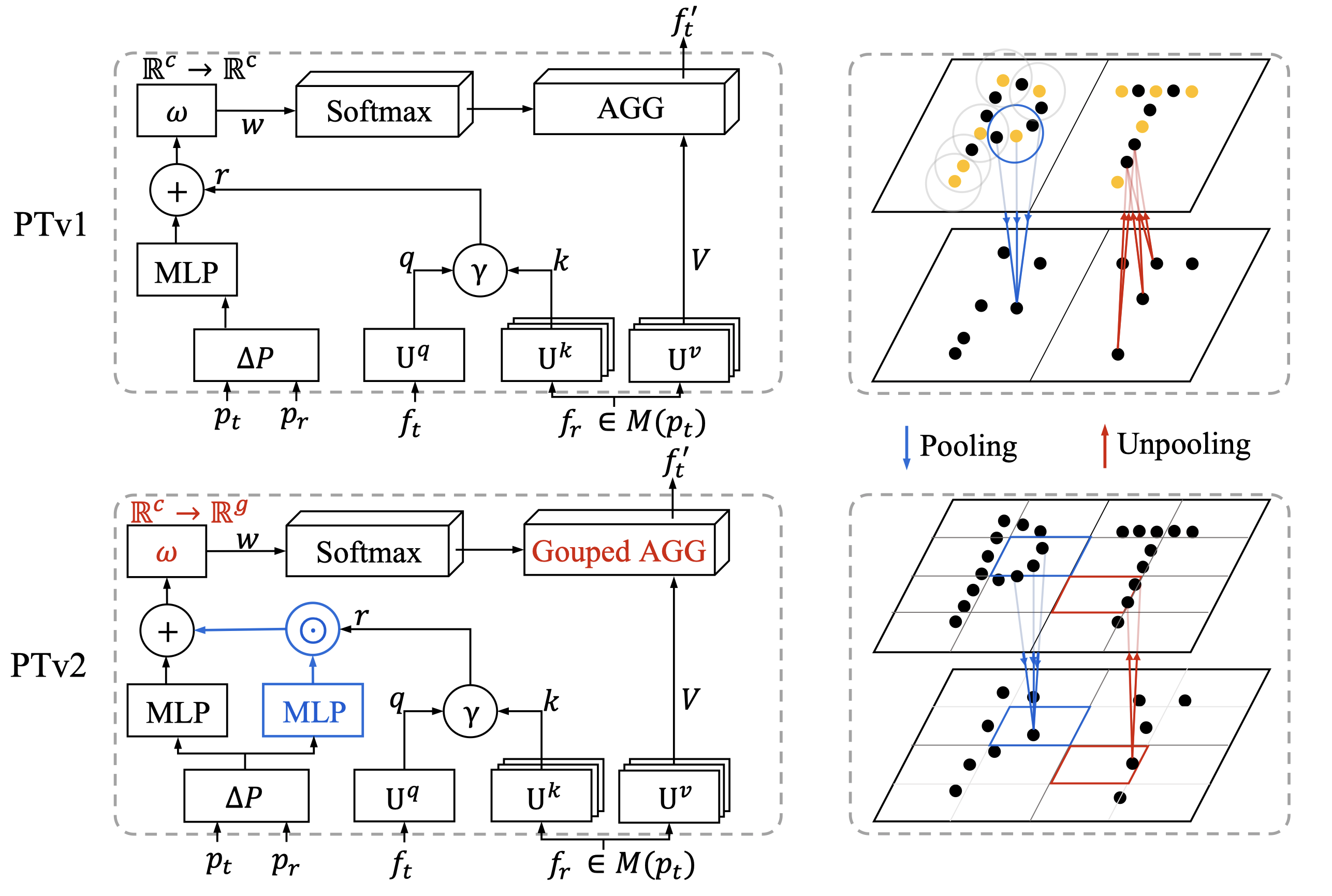
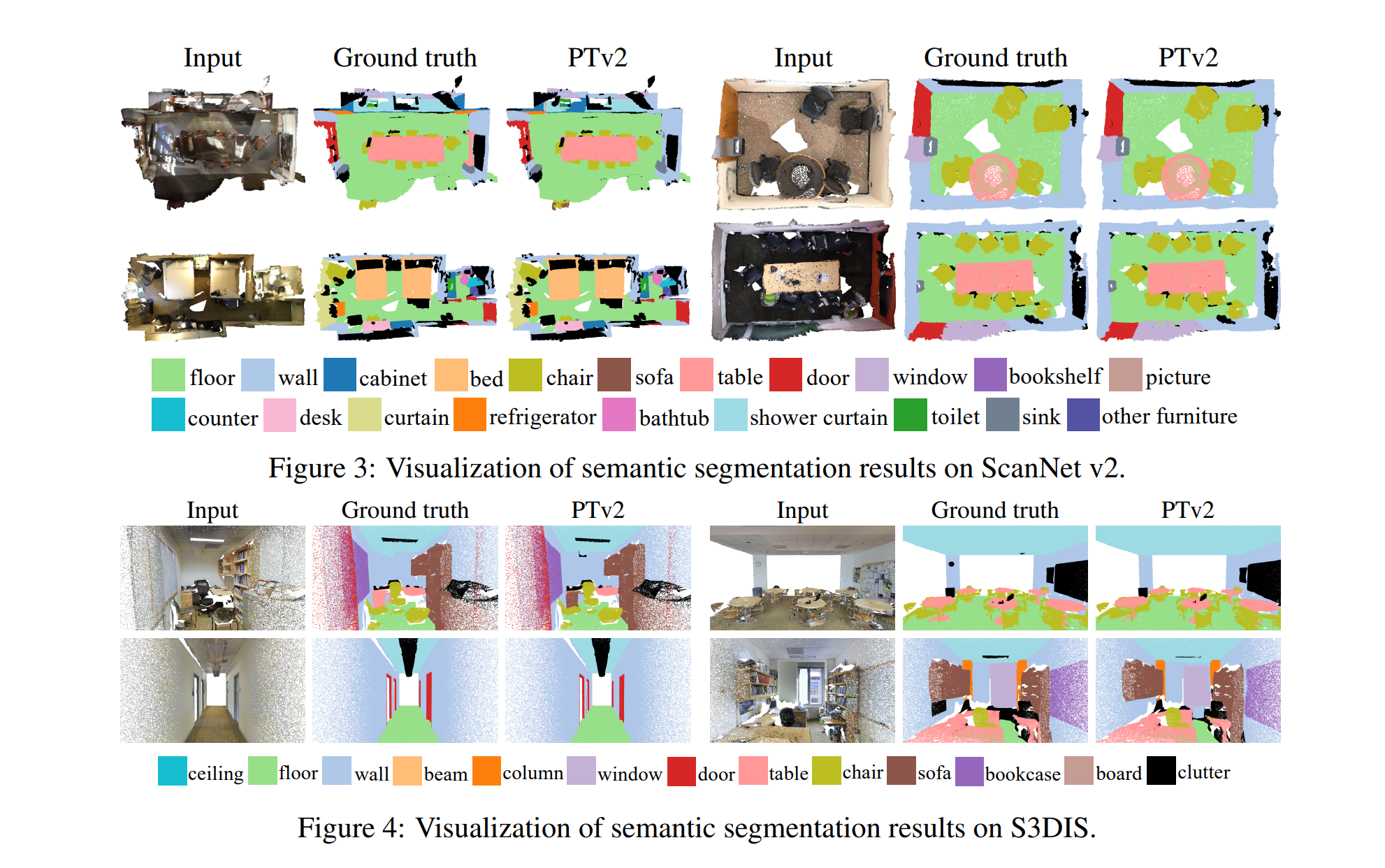
⚡ 论文:Point Transformer V2: Grouped Vector Attention and Partition-based Pooling
论文时间:11 Oct 2022
领域任务:3D Point Cloud Classification, Point Cloud Classification, 3D点云分类,点云分类
论文地址:https://arxiv.org/abs/2210.05666
代码实现:https://github.com/gofinge/pointtransformerv2
论文作者:Xiaoyang Wu, Yixing Lao, Li Jiang, Xihui Liu, Hengshuang Zhao
论文简介:In this work, we analyze the limitations of the Point Transformer and propose our powerful and efficient Point Transformer V2 model with novel designs that overcome the limitations of previous work.
论文摘要:作为探索 3D 点云理解的变压器架构的开创性工作,Point Transformer 在多个竞争激烈的基准测试中取得了令人印象深刻的结果。在这项工作中,我们分析了 Point Transformer 的局限性,并提出了我们强大而高效的 Point Transformer V2 模型,其新颖的设计克服了以前工作的局限性。特别是,我们首先提出了组向量注意力,它比之前版本的向量注意力更有效。继承了可学习的权重编码和多头注意力的优点,我们提出了一种高效的分组向量注意力的实现,它带有一个新的分组权重编码层。我们还通过一个额外的位置编码乘数来加强位置信息以引起注意。此外,我们设计了新颖且轻量级的基于分区的池化方法,可实现更好的空间对齐和更有效的采样。大量实验表明,我们的模型比其前身实现了更好的性能,并在几个具有挑战性的 3D 点云理解基准测试中达到了最先进的水平,包括 ScanNet v2 和 S3DIS 上的 3D 点云分割以及 ModelNet40 上的 3D 点云分类。我们的代码将在 https://github.com/Gofinge/PointTransformerV2 上提供。
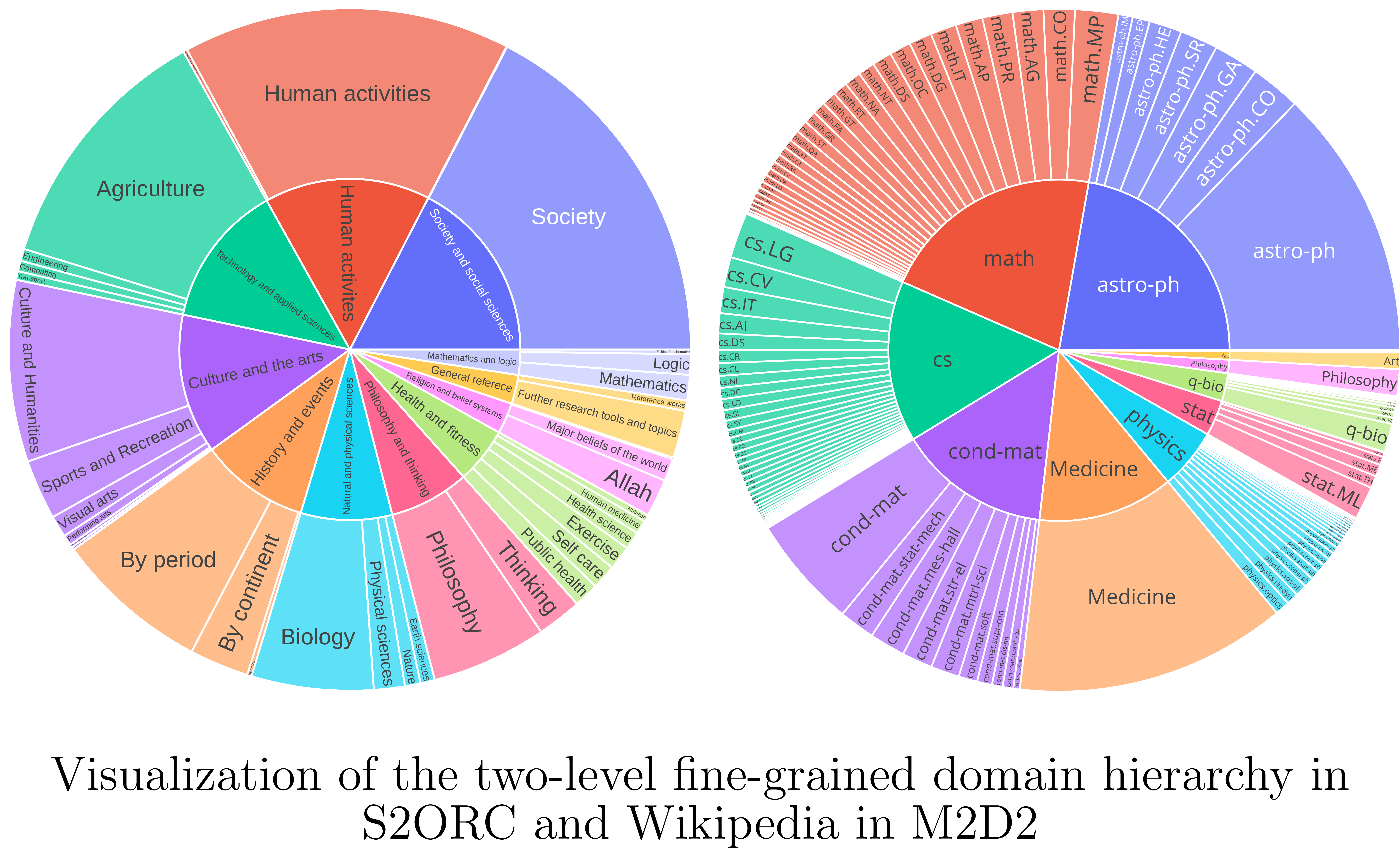
⚡ 论文:M2D2: A Massively Multi-domain Language Modeling Dataset
论文时间:13 Oct 2022
领域任务:Domain Generalization, Language Modelling,领域泛化,语言建模
论文地址:https://arxiv.org/abs/2210.07370
代码实现:https://github.com/machelreid/m2d2
论文作者:Machel Reid, Victor Zhong, Suchin Gururangan, Luke Zettlemoyer
论文简介:We present M2D2, a fine-grained, massively multi-domain corpus for studying domain adaptation in language models (LMs).
论文摘要:我们提出了 M2D2,这是一个细粒度、大规模的多领域语料库,用于研究语言模型 (LM) 中的领域适应。 M2D2 由 8.5B 个令牌组成,跨越从 Wikipedia 和 Semantic Scholar 提取的 145 个域。使用源自 Wikipedia 和 ArXiv 类别的本体,我们将每个数据源中的域组织成 22 个组。这种两级层次结构可以研究域之间的关系及其对适应后域内和域外性能的影响。作为 M2D2 支持的新型研究的示例,我们还对 LMs 中有效领域适应的性质提出了一些见解。为了提高域内性能,我们展示了沿域层次结构调整 LM 的好处;与大量弱相关数据相比,适应更少量的细粒度特定领域数据可以带来更大的域内性能增益。我们进一步证明了本体内部和跨本体的域内专业化和域外泛化之间的权衡,以及域外性能和域之间的词汇重叠之间的强相关性。
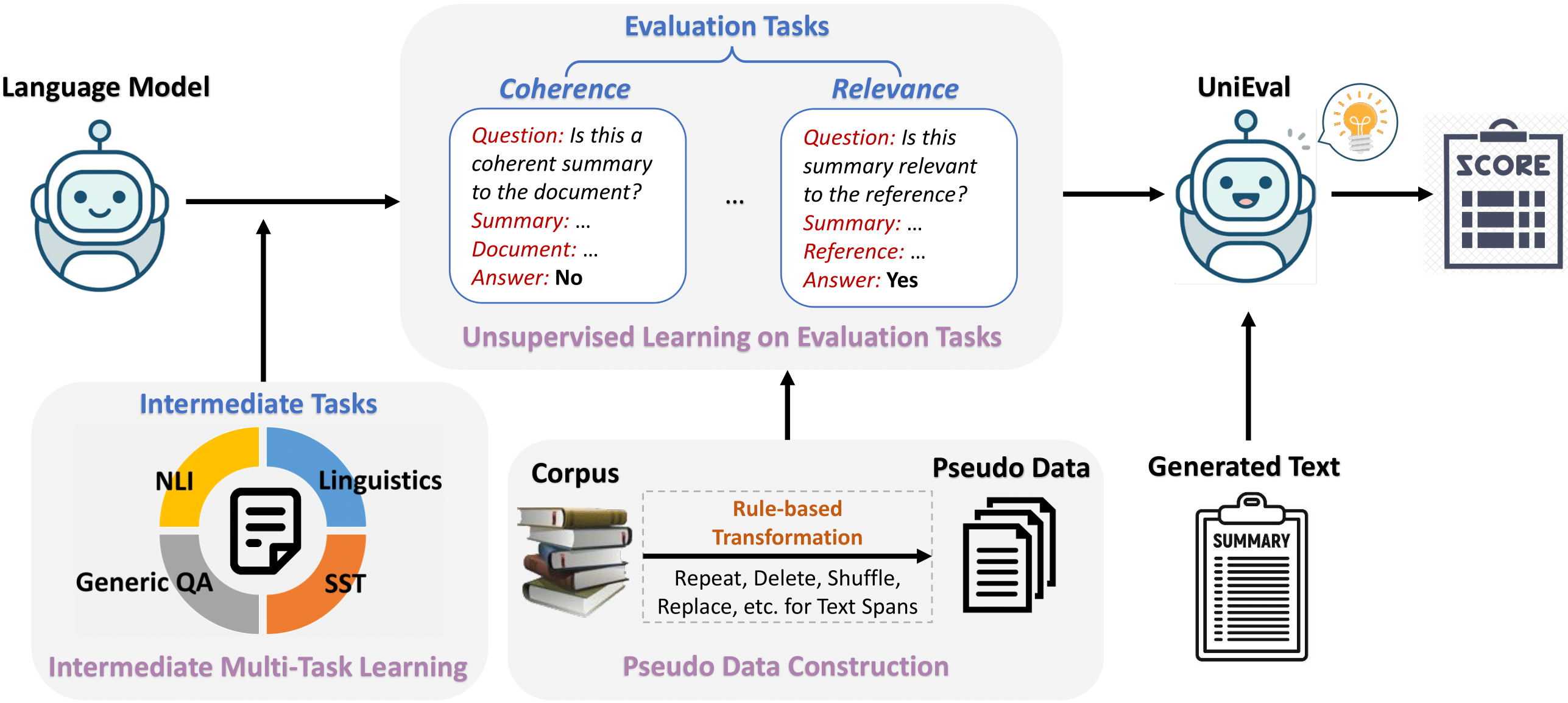
⚡ 论文:Towards a Unified Multi-Dimensional Evaluator for Text Generation
论文时间:13 Oct 2022
领域任务:Question Answering, Response Generation, 问答
论文地址:https://arxiv.org/abs/2210.07197
代码实现:https://github.com/maszhongming/unieval
论文作者:Ming Zhong, Yang Liu, Da Yin, Yuning Mao, Yizhu Jiao, PengFei Liu, Chenguang Zhu, Heng Ji, Jiawei Han
论文简介:We re-frame NLG evaluation as a Boolean Question Answering (QA) task, and by guiding the model with different questions, we can use one evaluator to evaluate from multiple dimensions.
论文摘要:多维评估是自然语言生成(NLG)中人类评估的主要范式,即从多个可解释的维度(例如连贯性和流畅性)评估生成的文本。然而,NLG 中的自动评估仍然以基于相似性的指标为主,我们缺乏可靠的框架来更全面地评估高级模型。在本文中,我们为 NLG 提出了一个统一的多维评估器 UniEval。我们将 NLG 评估重新定义为布尔问答 (QA) 任务,并通过用不同的问题指导模型,我们可以使用一个评估器从多个维度进行评估。此外,由于统一的布尔 QA 格式,我们能够引入中间学习阶段,使 UniEval 能够整合来自多个相关任务的外部知识并获得进一步改进。对三个典型 NLG 任务的实验表明,与现有指标相比,UniEval 与人类判断的相关性要好得多。具体来说,与表现最好的统一评估者相比,UniEval 在文本摘要方面的相关性高出 23%,在对话响应生成方面的相关性超过 43%。此外,UniEval 对看不见的评估维度和任务展示了强大的零样本学习能力。源代码、数据和所有预训练的评估器都可以在我们的 GitHub 存储库 (https://github.com/maszhongming/UniEval) 上找到。



















 28万+
28万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











