





📢 『A Beginner’s Guide to Prompt Design for Text-to-Image Generative Models』从文本到图像,生成模型的提示设计 · 入门指南
随着 Stable Diffusion、Midjourney 和 DALL·E2 的发布,使用文字提示生成图像成为新的潮流。如何使用尽可能少的提示文字来获得喜欢的图像呢?这里有一份通用的入门指南。
指南以『a cat wearing a pair of sunglasses (一只猫戴着一副太阳镜)』为基本提示文字,在 DreamStudio 中尝试改进文字以生成满意的图像。总结起来的基本技巧有:定义细粒度的艺术形式、添加风格或艺术家、添加增强形容词等。

将文章建议的候选描述词整理如下
| ◉ 基础设置 | |
|---|---|
| 提示长度应相对较短 | Midjourney 在60个单词以内,DALL·E2 在 400 个单词以内 |
| 提示文字的语言 | 使用英语 |
| 一个不错的文字模板 | [艺术形式] of [主题] by [艺术家], [细节 1], …, [细节 n] |
| ◉ 艺术形式 | |
| 摄影(photography) | studio photography, polaroid, camera phone |
| 绘画(paintings) | oil paintings, portraits, watercolor paintings |
| 插图(illustrations) | pencil drawing, charcoal sketch, etching, cartoon, concept art, posters, |
| 数字艺术(digital art) | 3D renders, vector illustrations, low poly art, pixel art, scan |
| 电影剧照(film stills) | movies, CCTV |
| ◉ 风格或艺术家 | |
| 建议1 | 混合两个或更多艺术家 |
| 建议2 | 使用虚构艺术家 |
| ◉ 细节:形容词和质量提升器 | |
| 取景 | close up, landscape, portrait, wide shot |
| 配色方案 | dark, pastel |
| 照明 | cinematic lighting, natural light |
| 其他 | epic, beautiful, awesome |
工具&框架
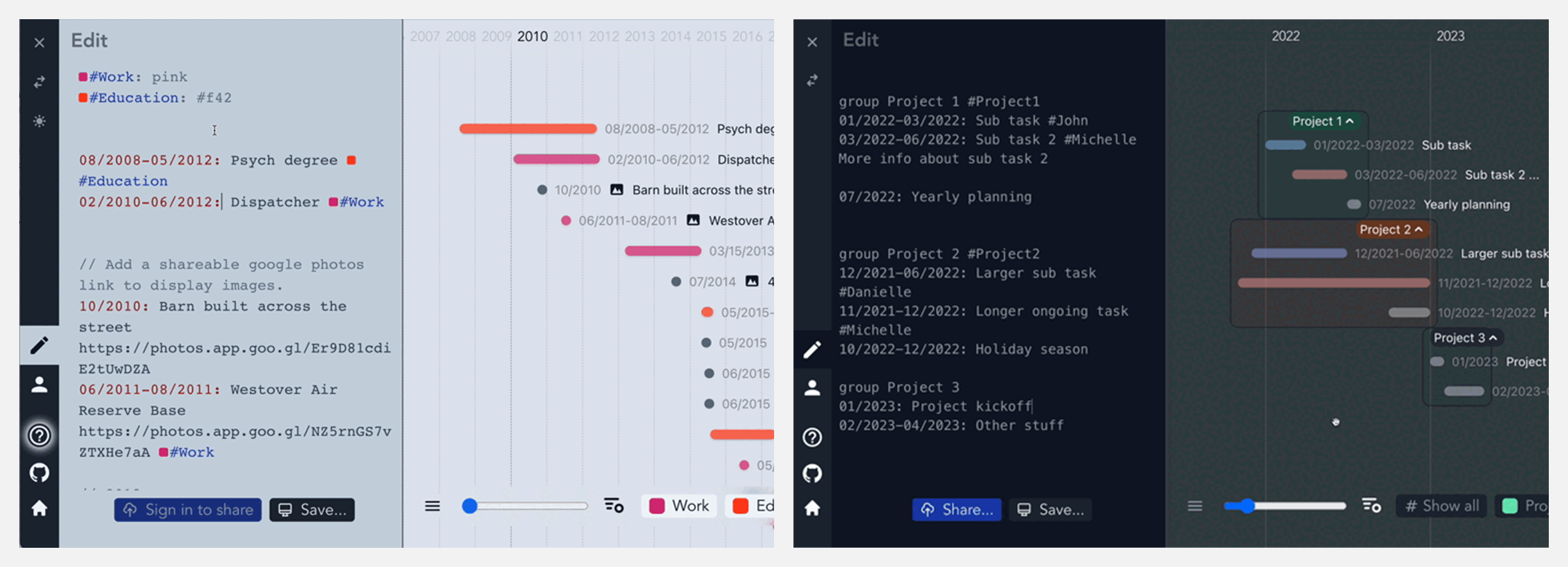
🚧 『Markwhen』将文本创建为漂亮的级联时间线
https://github.com/kochrt/markwhen
Markwhen是一个文本到时间线处理工具,它可以将类似 Markdown 的文本创建为漂亮的级联时间线。大家可以在上放第二个链接的在线网站体验它的功能效果。

🚧 『Go Recipes』Go 语言工具集锦
https://github.com/nikolaydubina/go-recipes
这个项目汇集了 Go 语言会用到的工具,知名的或鲜为人知的宝藏,包括测试、依赖、代码可视化、静态分析、代码生成、编译、执行等相关的工具。
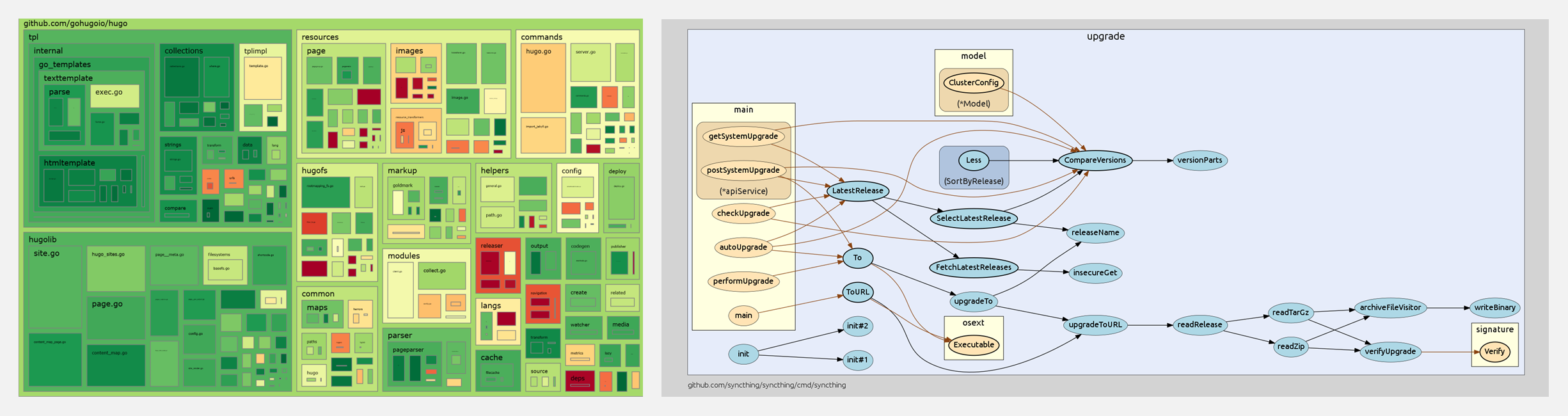
⬆ 测试 · 制作代码覆盖率树状图 & 代码可视化·制作包中的函数调用图

⬆ 代码可视化·制作 Go 代码库的 3D 图表 & 编译·以交互方式查看 Go 程序集
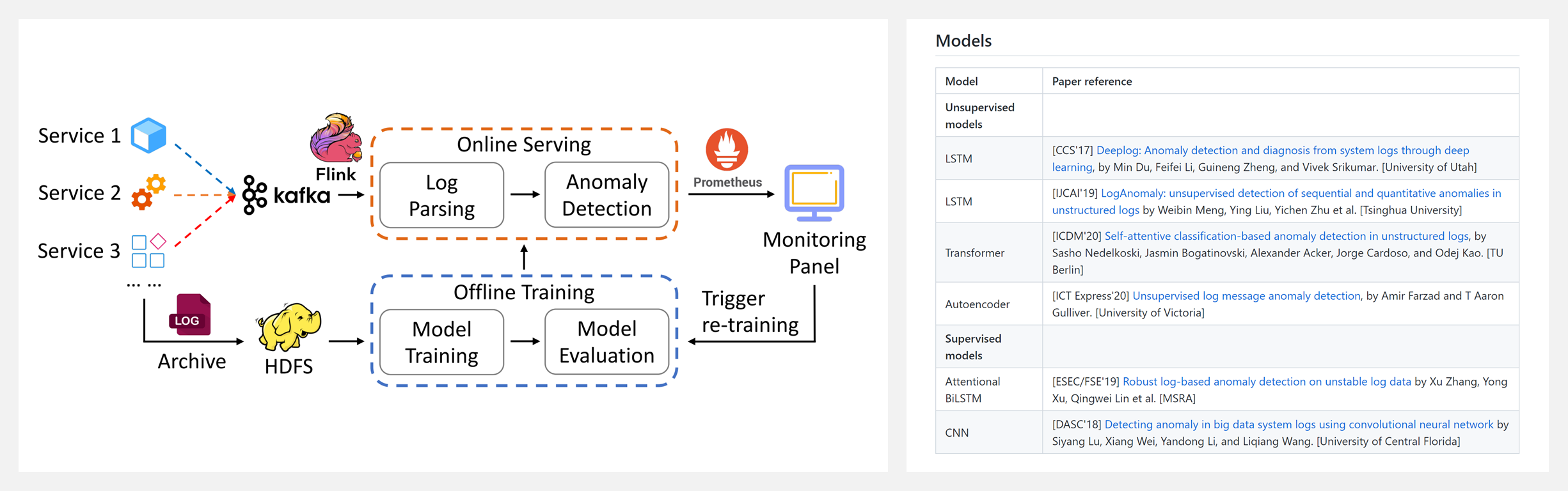
🚧 『Deep-loglizer』基于深度学习的日志分析异常检测工具包
https://github.com/logpai/deep-loglizer
https://arxiv.org/abs/2107.05908
Deep-loglizer是一个基于深度学习的日志分析工具包,用于自动异常检测。支持的模型包括:LSTM,Transformer,Autoencoder,Supervised models,Attentional BiLSTM,CNN。
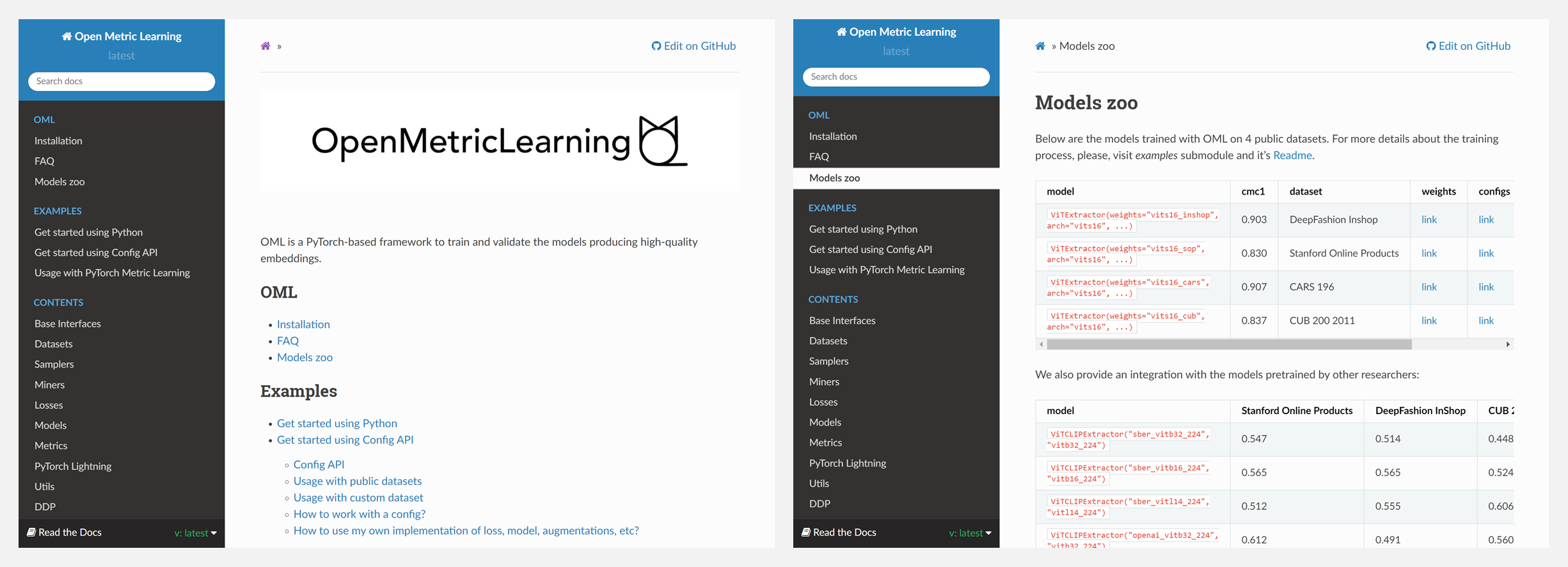
🚧 『OML』训练和验证产生高质量嵌入的模型
https://github.com/OML-Team/open-metric-learning
OML是一个基于 PyTorch 的框架,用于训练和验证产生高质量嵌入的模型。它针对以下场景和问题进行了调整,提供很好的支撑,你可以简单地使用OML来达到你的目的:
- 使用嵌入进行搜索时,需要计算它们之间的一些距离(例如余弦或L2)。
- 在搜索设置中,关心前N个输出与查询的关系如何。
- 自己实现一个度量学习管道/流水线。
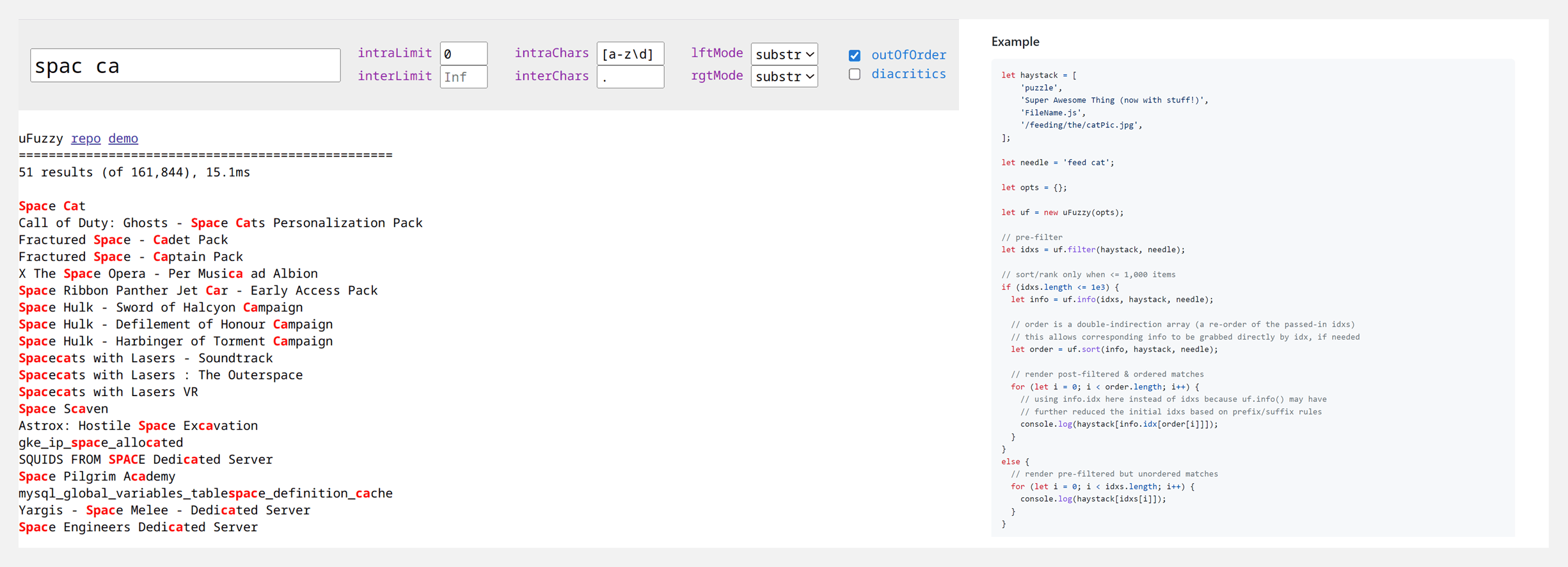
🚧 『uFuzzy』微小高效的Javascript模糊搜索引擎
https://github.com/leeoniya/uFuzzy
uFuzzy 是一个模糊搜索库,旨在将一个相对较短的搜索短语与一大批中短语相匹配。它常见的应用场景是列表过滤、自动补全/建议、以及标题/名称/描述/文件名/功能搜索。
博文&分享
👍『Full Stack Deep Learning』Berkeley伯克利(FSDL) · 全栈深度学习训练营课程
https://www.showmeai.tech/article-detail/356
UC Berkeley 开放了这门全栈深度学习训练营课程,以实战为主,讲解了不同场景下应用深度学习解决问题的工具、过程和方法:从问题理解,方法选择、数据管理、选择 GPU 到 Web 部署、监控和再训练。

FSDL 课程包含了典型的自然语言处理与计算机视觉中,对文本和图像的处理建模方法,也包括AI应用生态的其他工序与操作,比如数据标注与管理、模型测试、模型部署等。完整的课程学习可以帮助我们了解 AI 解决问题的全链条技能,更好地把控AI落地应用的能力。
ShowMeAI 对课程资料进行了梳理,整理成这份完备且清晰的资料包(点击 这里 获取这份资料包):
- 📚课件。PDF文件。覆盖Lecture 1~13的全部章节。
- 📚代码。.ip文件。覆盖Lab 1~10的全部内容
- 📚笔记。PDF文件。课程学习的辅助资料,图文并茂,细节丰富。
👍 『Database System』CMU卡内基梅隆(14-455) · 数据库系统导论课程
https://www.showmeai.tech/article-detail/357
CMU 14-455 是 CMU 卡内基梅隆大学开放的数据库方向的专业课程,详尽介绍了数据库的基本知识、底层原理、效率优化、查询优化、新数据库等,是数据库管理系统设计与实施方向的权威好课。

课程内容覆盖SQL、数据库、索引构建与优化、内存管理、并发控制、排序、分组聚合、查询规划、冲突与锁定、分布式数据库、内存数据库、Facebook Scuba、MongoDB、CockroachDB等内容,可以帮助构建系统的数据库原理与应用知识。
ShowMeAI 对课程资料进行了梳理,整理成这份完备且清晰的资料包(点击 这里 获取这份资料包):
- 📚课件。PDF版本,覆盖Lecture 1~26全部章节。
- 📚笔记。PDF版本,覆盖Lecture 1~22章节。
- 📚作业。PDF版本,覆盖Homework 2~5。
👍 『Advanced Database Systems』CMU卡内基梅隆(15-721) · 数据库系统进阶课程
https://www.showmeai.tech/article-detail/358
CMU 15-721 是 CMU 卡内基梅隆大学开放的数据库方向进阶课程,讨论了很多数据库方向新的技术研究方向与话题,适合有数据库基础又想在该方向有深入研究的同学学习。

课程是对现代数据库管理系统内部结构的综合研究,涵盖 OLTP 和 OLAP 中使用组件的核心概念与基础知识,讲解其实现的效率与准确率,并将在一个真实内存、多核数据库系统中完成实现。所以,课程学习前需要具备一定编程技能。
ShowMeAI 对课程资料进行了梳理,整理成这份完备且清晰的资料包(点击 这里 获取这份资料包):
- 📚课件。PDF版本。覆盖Lecture 1~25所有章节。
- 📚笔记。PDF版本。5份Notes,辅助课程学习。
- 📚作业。Markdown文件。7份作业文件。
- 📚拓展阅读资料。PDF文件。100+相关论文。
数据&资源
🔥 『Light Field Salient Object Detection: A Review and Benchmark』光场显著物体检测相关文献资源列表
https://github.com/kerenfu/LFSOD-Survey
http://www.kerenfu.top/sources/2021cvmlfsurvey-cn.pdf
- Light Field
- i. Multi-view Images and Focal Stacks
- Light Field SOD
- i. Traditional Models
- ii. Deep Learning-based Models
- iii. Other Review Works
- Light Field SOD Datasets
- Benchmarking Results
- i. RGB-D SOD Models in Our Tests
- ii. Quantitative Comparison
- iii. All Models’ Saliency Maps
- iv. Qualitative Comparison
- Citation


研究&论文

可以点击 这里 回复关键字 日报,免费获取整理好的论文合辑。
科研进展
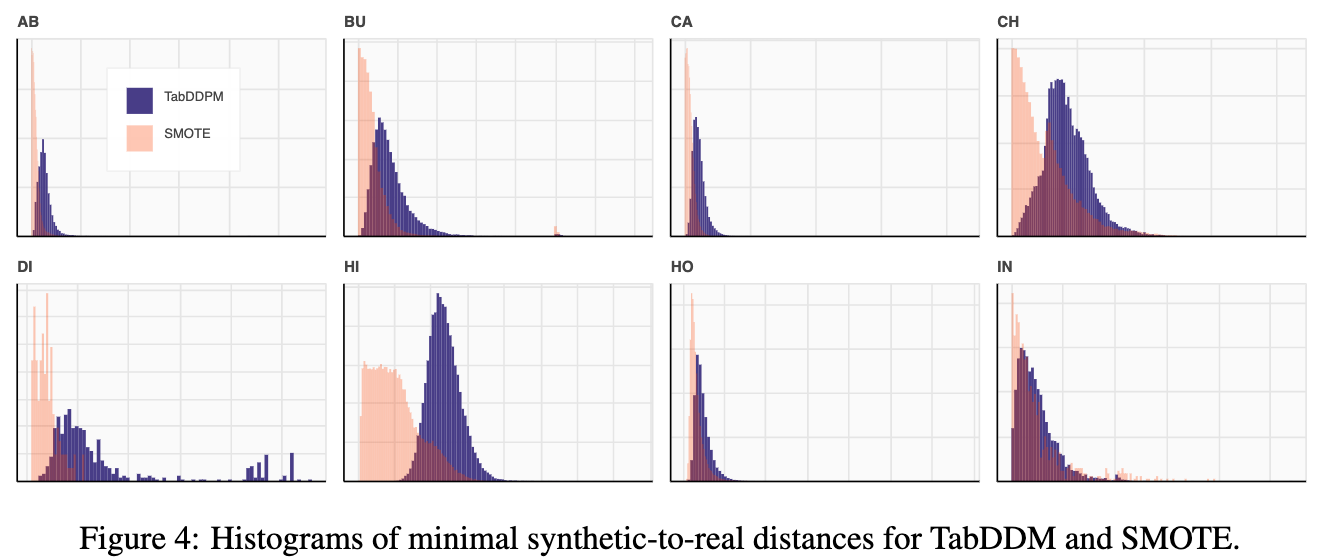
- 2022.09.30 『降噪』 TabDDPM: Modelling Tabular Data with Diffusion Models
- 2022.10.03 『语言模型』 SpeechCLIP: Integrating Speech with Pre-Trained Vision and Language Model
- 2022.09.29 『图像分类』 Dilated Neighborhood Attention Transformer
⚡ 论文:TabDDPM: Modelling Tabular Data with Diffusion Models
论文时间:30 Sep 2022
领域任务:Denoising,降噪
论文地址:https://arxiv.org/abs/2209.15421
代码实现:https://github.com/rotot0/tab-ddpm
论文作者:Akim Kotelnikov, Dmitry Baranchuk, Ivan Rubachev, Artem Babenko
论文简介:Denoising diffusion probabilistic models are currently becoming the leading paradigm of generative modeling for many important data modalities./去噪扩散概率模型目前正成为许多重要数据模式的生成建模的领先范式。
论文摘要:去噪扩散概率模型目前正成为许多重要数据模式的生成模型的领先范式。作为计算机视觉界最普遍的模型,扩散模型最近在其他领域也获得了一些关注,包括语音、NLP和类图数据。在这项工作中,我们研究了扩散模型的框架是否对一般的表格问题有利,其中数据点通常由异质特征的向量表示。表格数据固有的异质性使其对精确建模具有相当大的挑战性,因为各个特征的性质可能完全不同,即有些是连续的,有些是离散的。为了解决这样的数据类型,我们引入了TabDDPM–一个可以普遍适用于任何表格数据集和处理任何类型特征的扩散模型。我们在一组广泛的基准上对TabDDPM进行了广泛的评估,并证明它比现有的GAN/VAE替代品更有优势,这与扩散模型在其他领域的优势是一致的。此外,我们表明TabDDPM可以用于面向隐私的设置,其中原始数据点不能被公开共享。
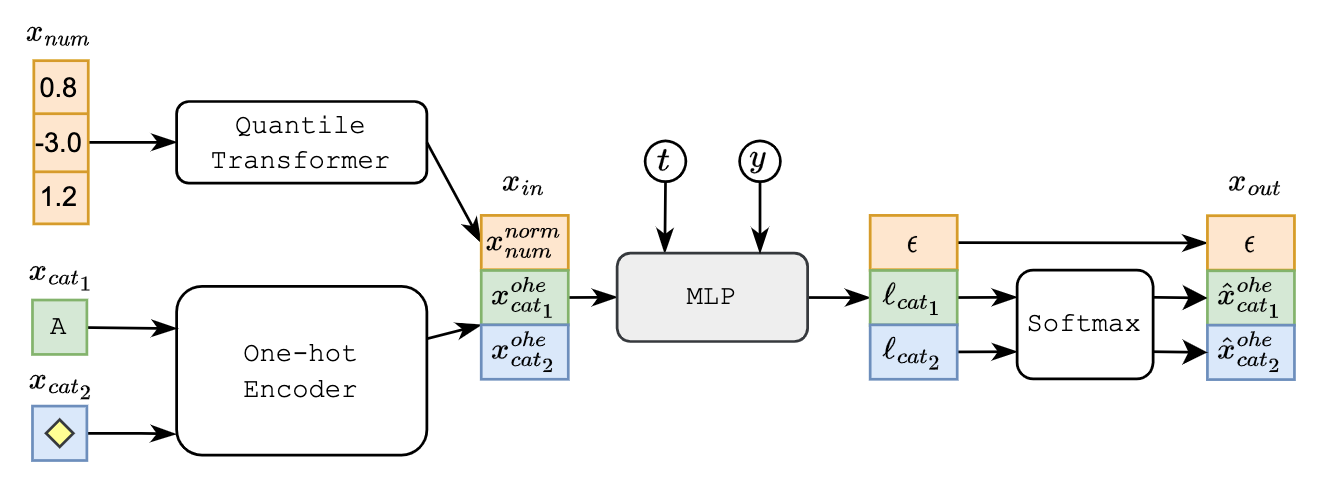
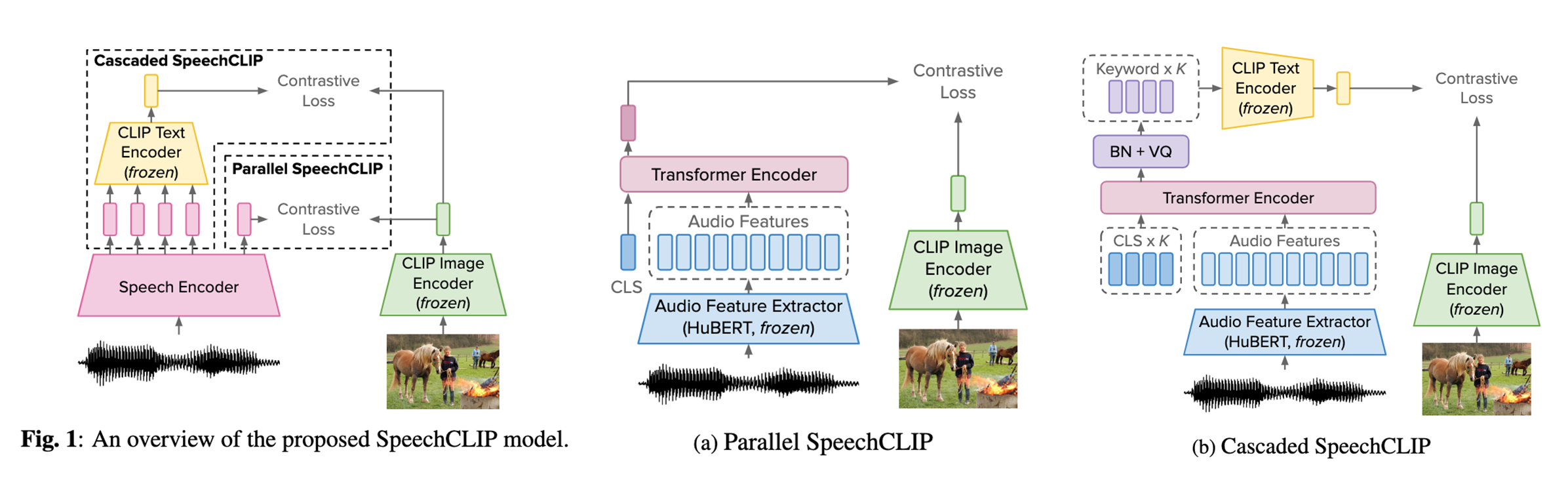
⚡ 论文:SpeechCLIP: Integrating Speech with Pre-Trained Vision and Language Model
论文时间:3 Oct 2022
领域任务:Language Modelling,语言模型
论文地址:https://arxiv.org/abs/2210.00705
代码实现:https://github.com/atosystem/speechclip
论文作者:Yi-Jen Shih, Hsuan-Fu Wang, Heng-Jui Chang, Layne Berry, Hung-Yi Lee, David Harwath
论文简介:Data-driven speech processing models usually perform well with a large amount of text supervision, but collecting transcribed speech data is costly./数据驱动的语音处理模型通常在大量的文本监督下表现良好,但收集转录的语音数据成本很高。
论文摘要:数据驱动的语音处理模型通常在大量的文本监督下表现良好,但收集转录的语音数据成本很高。因此,我们提出了SpeechCLIP,一个通过图像连接语音和文本的新型框架,以增强语音模型而不需要转录。我们利用最先进的预训练的HuBERT和CLIP,通过成对的图像和口语说明,以最小的微调将它们对齐。SpeechCLIP在图像-语音检索方面的表现优于先前的最先进水平,并在没有转录的直接监督下进行零样本的语音-文本检索。此外,SpeechCLIP可以直接从语音中检索出语义相关的关键词。
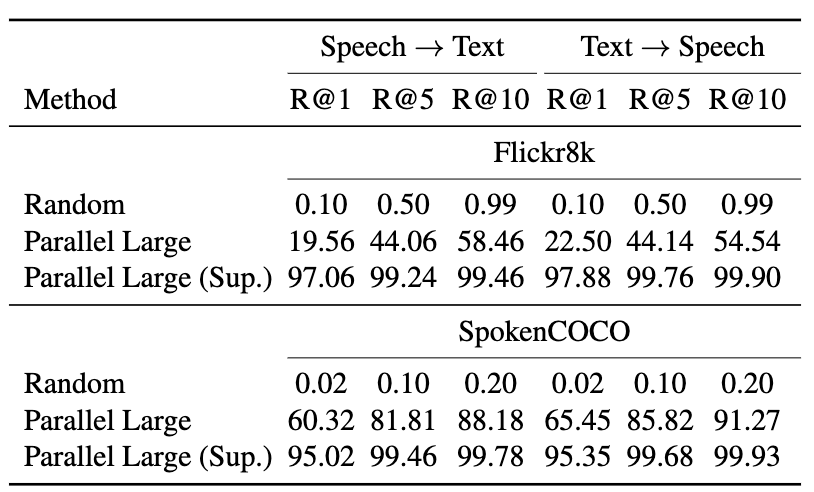
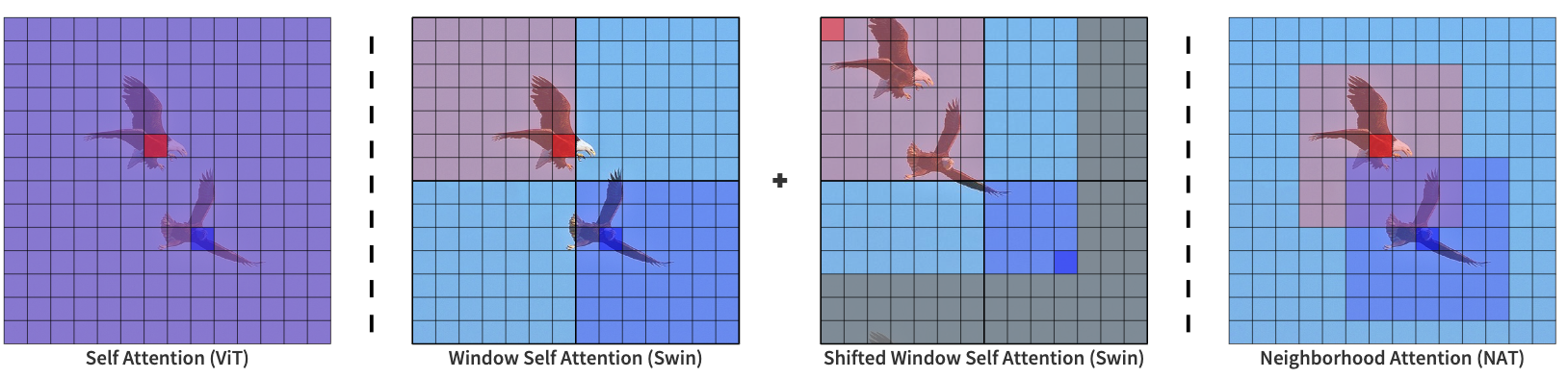
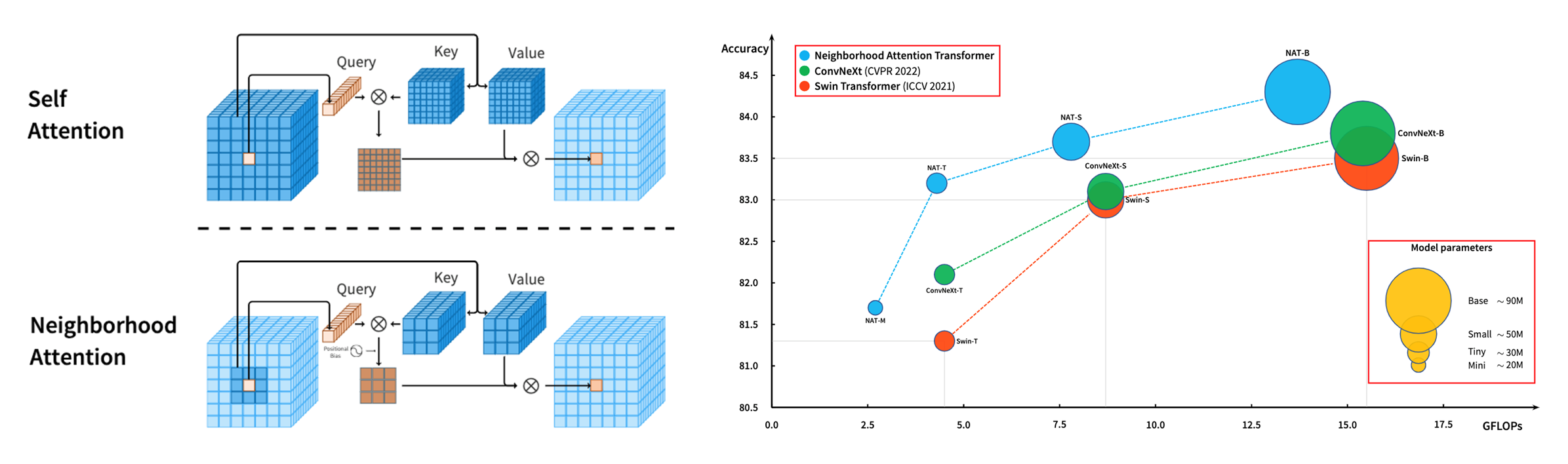
⚡ 论文:Dilated Neighborhood Attention Transformer
论文时间:29 Sep 2022
领域任务:Image Classification, Instance Segmentation, 图像分类,实例分割
论文地址:https://arxiv.org/abs/2209.15001
代码实现:https://github.com/SHI-Labs/Neighborhood-Attention-Transformer
论文作者:Ali Hassani, Humphrey Shi
论文简介:These models typically employ localized attention mechanisms, such as the sliding-window Neighborhood Attention (NA) or Swin Transformer’s Shifted Window Self Attention./这些模型通常采用局部注意机制,如滑动窗口的邻域注意(NA)或Swin Transformer的移位窗口自我注意。
论文摘要:Transformers正迅速成为跨模式、领域和任务的最大量应用的深度学习架构之一。在视觉领域,除了正在进行的普通转化器的研究之外,分层transformer也获得了极大的关注,这要归功于它们的性能和易于集成到现有框架中。这些模型通常采用局部注意机制,如滑动窗口邻里注意(NA)或Swin transformer的移位窗口自我注意。虽然有效地降低了自我注意的四次方复杂性,但局部注意削弱了自我注意的两个最理想的特性:长距离的相互依赖模型和全局接受场。在本文中,我们介绍了扩张的邻域注意(DiNA),它是对NA的自然、灵活和有效的扩展,可以捕捉更多的全局背景,并在不增加成本的情况下成倍地扩大感受野。NA的局部注意和DiNA的稀疏全局注意相辅相成,因此我们引入了扩张邻域注意transformer(DiNAT),一个建立在两者基础上的新的分层视觉transformer。DiNAT变体比基于注意力的基线,如NAT和Swin,以及现代卷积基线ConvNeXt,享有明显的改进。我们的Large模型在COCO物体检测中比Swin模型领先1.5%的盒式AP,在COCO实例分割中领先1.3%的掩码AP,在ADE20K语义分割中领先1.1%的mIoU,并且在吞吐量上更快。我们相信,NA和DiNA的组合有可能赋予本文所介绍的任务以外的各种任务。为了支持和鼓励这个方向的研究,在视觉和其他方面,我们把项目开源到:https://github.com/SHI-Labs/Neighborhood-Attention-Transformer
我们是 ShowMeAI,致力于传播AI优质内容,分享行业解决方案,用知识加速每一次技术成长!
◉ 点击 日报合辑,在公众号内订阅话题 #ShowMeAI资讯日报,可接收每日最新推送。
◉ 点击 电子月刊,快速浏览月度合辑。
◉ 点击 这里 ,回复关键字 日报 免费获取AI电子月刊与论文 / 电子书等资料包。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












{kind=link}