








论文网址:[2402.02370] AutoTimes: Autoregressive Time Series Forecasters via Large Language Models
英文是纯手打的!论文原文的summarizing and paraphrasing。可能会出现难以避免的拼写错误和语法错误,若有发现欢迎评论指正!文章偏向于笔记,谨慎食用
目录
2.3.2. Large Language Models for Time Series
2.3.3. Multimodal Language Models
2.5.1. Time Series Forecasting
1. 心得
(1)大模型的图都可可爱爱捏,都是小登,真好
2. 论文逐段精读
2.1. Abstract
①Time series analysis by LLM ignores inherent autoregressive property and decoder-only architecture of LLMs
corpora n. 任何事物之主体;全集
revitalize v. 使恢复生机,使复兴(=revitalise)
2.2. Introduction
①Existing approaches:
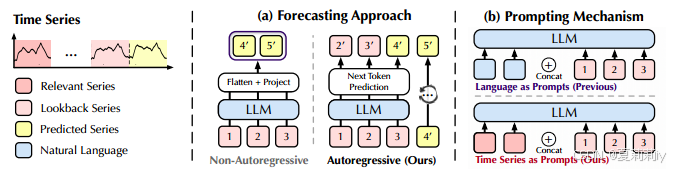
where non-autoregressive causes inconsistencies in data structure, so they aim to obtain a consistent representation
2.3. Related Work
2.3.1. Autoregressive Models
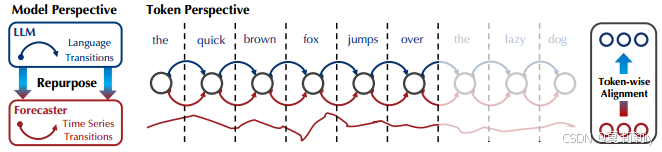
①现有的LLM本质上是自回归模型
②Autoregressive models excell at multi-step generation
2.3.2. Large Language Models for Time Series
①Lists LLMs for time series prediction
②Functions of each model:

2.3.3. Multimodal Language Models
①For avoiding the separation betweem time series and text prompt, they utilize time itself as embedding
2.4. Method
①Lookback observations: , where
denotes time steps and
is variates
②Task: predict future time steps
③Timestamps (e.g.
) are also add for enchancing prediction ability:
2.4.1. Modality Alignment
(1)Time series token
①Pipeline of time prediction:
②For signal variate at time point
and context length
, the
-th segment of length
is:
③They align time series tokens and language tokens by:
where dimension is for aligning with LLM
(2)Position embedding
①Begin of sequence <bos> and end of sequence <eos> design:
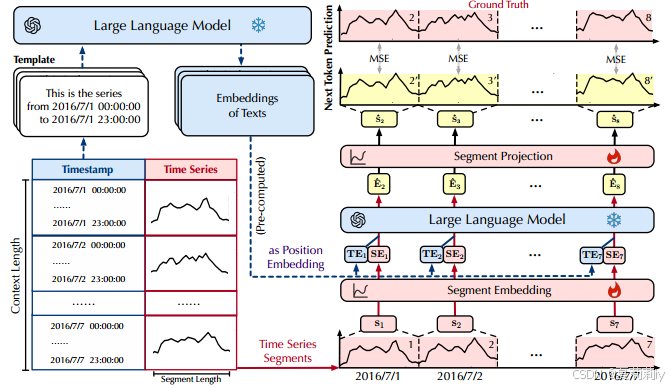
where (这个selectlast是啥啊?)
②The final embedding is:
2.4.2. Next Token Prediction
①对于每一个嵌入,作者要分别预测其下一秒的序列:
②To futher project this by:
③Loss:
④Multi-steps prediction:
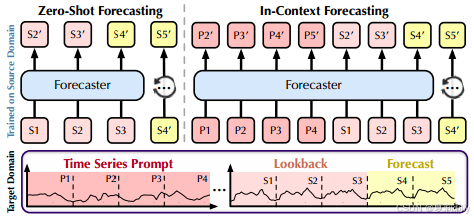
2.4.3. In-Context Forecasting
①Task demonstrations in LLM is paired questions and answers:
where denotes the template that transforms each question and answer into natural language
②For extended context with
time series prompts
:
③In-context forecasting process:
2.5. Experiments
2.5.1. Time Series Forecasting
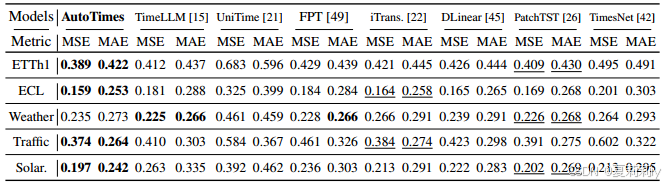
①Datasets: ETTh1, ECL, Traffic, Weather, and Solar-Energy for long term forecasting, M4 competition for short term forecasting
②Baselines: LLM4TS methods: TimeLLM, UniTime, and FPT; deep forecasters: iTransformer, DLinear, PatchTST, and TimesNet; short-term forecasters: Koopa, N-HiTS and N-BEATS
③Backbone: LLaMA-7B
④Short term performance:

⑤Long term performance table:
2.5.2. Zero-Shot Forecasting
①Zero shot performance:

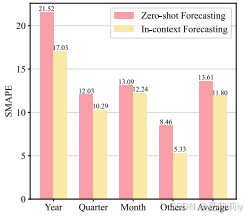
2.5.3. In-Context Forecasting
①In-context forecasting fomular:
②In-context performance:
2.5.4. Method Analysis
①Backbone ablation:
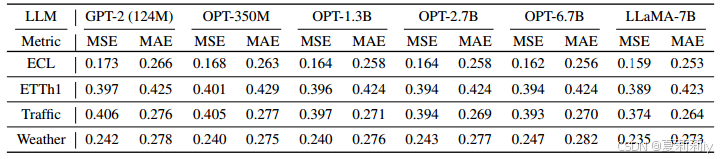
②Efficiency of LLMs:
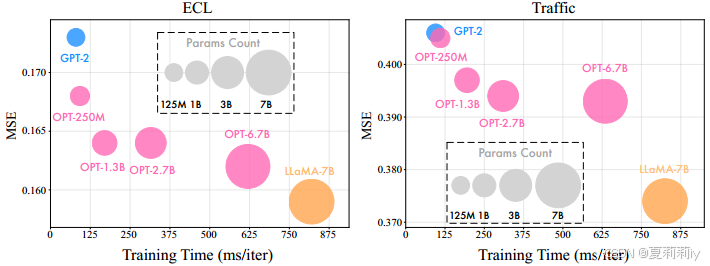
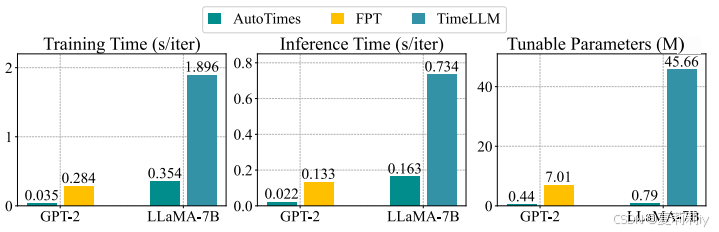
③Training and inference time:
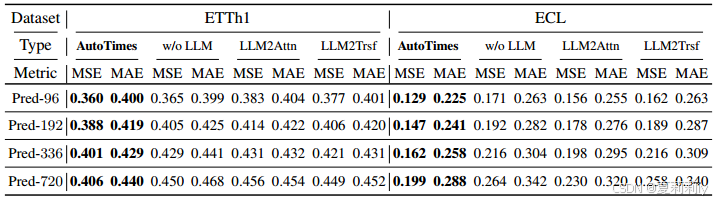
④LLM4TS ablation:
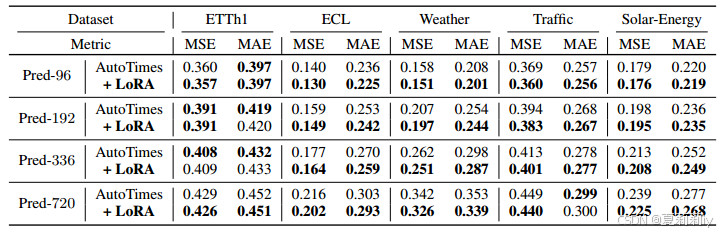
⑤LoRA combined performance:
2.6. Conclusion
~

















 406
406

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









