








英文是纯手打的!论文原文的summarizing and paraphrasing。可能会出现难以避免的拼写错误和语法错误,若有发现欢迎评论指正!文章偏向于笔记,谨慎食用
目录
2.3. Related concepts and definitions
2.3.2. Graph convolutional neural network (GCN)
2.3.3. Graph attention convolutional neural network (GAT)
2.4.2. Spectral-spatial transformer module (STM)
2.4.3. Multi-features attention module (MFaM)
2.4.4. Multi-scale receptive fields construction module (MRcM)
2.4.5. Feature fusion and attention decision module (FaDM)
2.4.6. HSI classification using MRGAT
2.4.7. Computational complexity analysis
2.5.2. Dataset description and processing
2.5.4. Analysis of the parameter effect
2.5.5. The performances with limited labeled samples
2.5.7. Training time comparison
1. 心得
(1)接上篇
(2)感觉瞟一眼已经很相似了
(3)好奇怪的写作风格...读起来不是很友善...感觉把不是很难的东西写得好难...
(4)到底为什么非要把高光谱仪器放上来啊???是你们的吗就放?
2. 论文逐段精读
2.1. Abstract
①Existing problems: GNNs are time consuming, inefficient in information description, and poor in anti-noise robustness
②Thus, they proposed multi-scale receptive fields graph attention neural network (MRGAT)
2.2. Introduction
①Challenges in hyperspectral image (HSI) classification: label deficiency, high data dimension, spectrum similarity, pixel blending
②从传统的机器学习到CNN到GNN的应用介绍
③Weaknesses of existing GNNs on HSI classification: a) high computational complexity, b) only focus on local information, c) noise in nodes
2.3. Related concepts and definitions
2.3.1. Problem definition
①Labelled set of a graph is defined as, where
of
nodes are labelled,
denotes spectral vector of node
,
denotes the label of node
,
denotes the number of classes
②Mapping:
2.3.2. Graph convolutional neural network (GCN)
①Undirected graph: , where
denotes vertex set,
denotes edge set,
denotes adjacency matrix,
is node feature matrix
②Aggregation operation of GCN:
where denotes nonlinear activation function,
,
,
denotes degree matrix,
denotes learnable matrix at layer
2.3.3. Graph attention convolutional neural network (GAT)
①Implement linear transformation on node features:
②Importance score:
is parameter vector
③Apply Softmax on :
where denotes the number of neighbors of node
④Aggregation of GAT:
2.4. Proposed method
2.4.1. The overview of MRGAT
①Overall framework of MRGAT:

2.4.2. Spectral-spatial transformer module (STM)
①For a HSI cube with
spectral channels and
pixels,
denotes feature vector of pixel
,
denotes width, and
denotes height
②They apply PCA to reduce dimension and employ SLIC to segment image to superpixels:
where denotes superpixel
with
pixels,
is the total number of superpixels
③To remain more features in superpixels, they design Spectral transformer:

④They add location on the feature:
where is the pixel’s spectral value in
th spectral channel(为啥
完全没有再图里面体现出来,而且这个
的中介作用到底是啥?)
⑤The output of 1 × 1 Conv at channel :
⑥An association matrix for reflecting the relationship between pixels and superpixels:
⑦HSI feature:
⑧Reshape the spatial relations:
2.4.3. Multi-features attention module (MFaM)
①Pipeline of MFaM:

②The -th conv layer:
where denotes learned attention coefficients of neighbors
③Multilayer conv:
where denotes assignment symbol,
denotes the
th hop neighbors of node
,
denotes the total number of neighbors in the
-th hop of node
,
denotes the important coefficients of
④A Gaussian distance to represent node relationship:
where is empirical value which are set to 0.2
⑤The edge attention conv:
where denotes learned attention coefficients of edges
⑥The final :
⑦Feature fusion attention:
⑧The centroid node:
where and
are weight coefficient
2.4.4. Multi-scale receptive fields construction module (MRcM)
①The receptive field of the node :
where the subscript of denotes the hop number,
②Feature of centroid node:
③Vis of hop:

2.4.5. Feature fusion and attention decision module (FaDM)
①The output of MRcM:
②Softmax classification:
where denotes the number of classes
2.4.6. HSI classification using MRGAT
①Loss function:
where denotes label matrix,
denotes labeled example set
②Optimizer: Adam gradient descent
③Algorithm of MRGAT:

2.4.7. Computational complexity analysis
①我放个原文吧感觉这里也比较精简我就懒得再简化了:

2.5. Experimental results
2.5.1. Experimental Setup
①Hyperparameters setting:

②The architectural details of MRGAT:
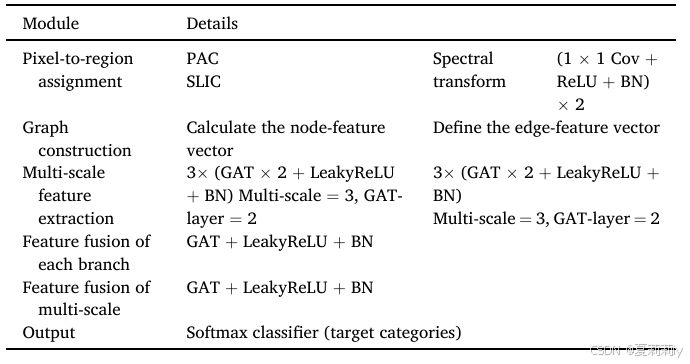
③Framework of MRGAT:

④Running times: 10
⑤Training samples per class: 30
2.5.2. Dataset description and processing
①Pavia University, with 103 of 115 bands after processing, 9 classes and size of 610*340:


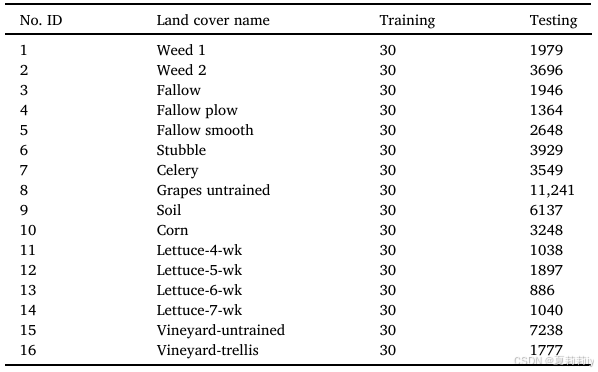
②Salinas, with 204 of 224 bands after removing water vapor absorption bands, 16 categories and size of 512*217:

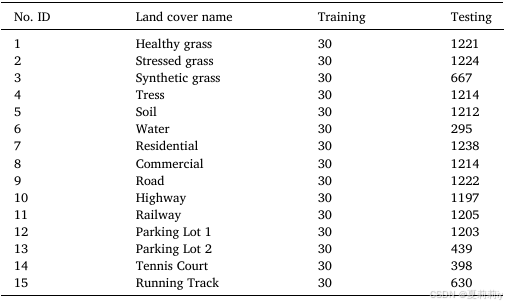
③Houston 2013, with 144 bands, 15 classes, size of 364-1046 nm:

④震撼人心的高光谱仪器,即便不知道是哪里来的,就没有一点版权问题吗??看作者也没有自己收集:

2.5.3. Classification results
①Performance on Pavia University:
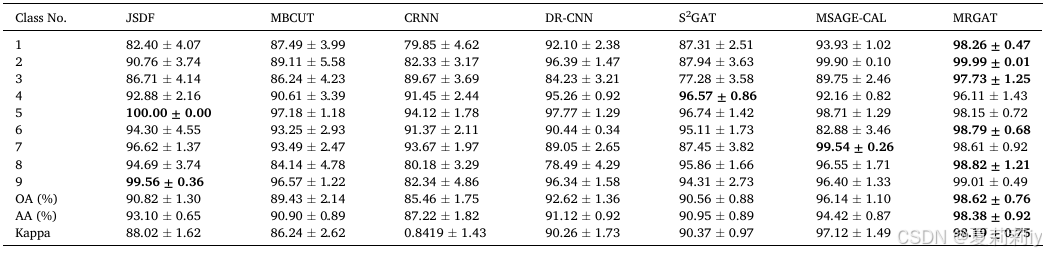

②Performance on Salinas:
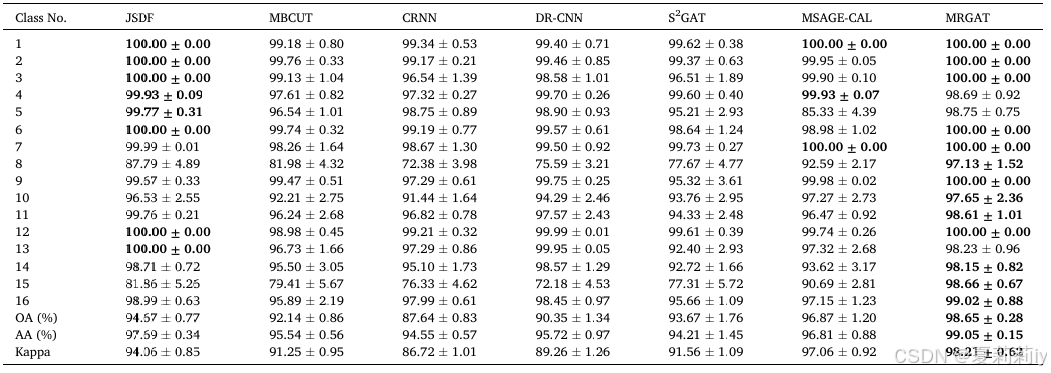

③Performance on Houston 2013:
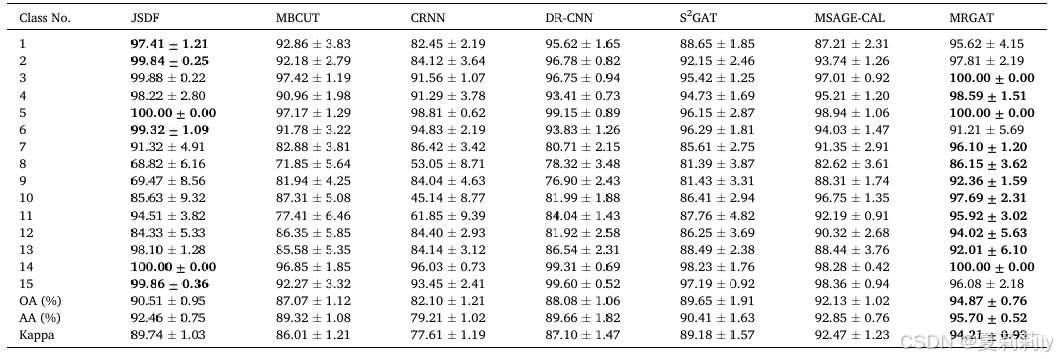

2.5.4. Analysis of the parameter effect
①Ablation of and
((a) Pavia University. (b) Salinas. (c) Houston 2013):

②Ablation of amd
((a) Pavia University. (b) Salinas. (c) Houston 2013):

2.5.5. The performances with limited labeled samples
①Performance at limited labelled data trained:

2.5.6. Ablation study
①Module ablation:

2.5.7. Training time comparison
①Training time:

2.6. Conclusion
~
3. Reference
Ding, Y. et al. (2023) Multi-scale receptive fields: Graph attention neural network for hyperspectral image classification, Expert Systems with Applications, 223. doi: Redirecting

















 303
303

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









