








论文网址:PokeMQA: Programmable knowledge editing for Multi-hop Question Answering - ACL Anthology
英文是纯手打的!论文原文的summarizing and paraphrasing。可能会出现难以避免的拼写错误和语法错误,若有发现欢迎评论指正!文章偏向于笔记,谨慎食用
目录
2.3. Multi-hop Question Answering under Knowledge Editing
2.4. Programmable Editing in Memory of Multi-hop Question Answering
2.4.2. Programmable Scope Detector
2.4.3. Knowledge Prompt Generator
2.5.2. Baselines Methods & Language Models
1. 心得
(1)可能不是专门做这个方向的我,有些描述或许需要结合代码才能更清晰一点
2. 论文逐段精读
2.1. Abstract
①Existing problems: current cascading knowledge updating methods are mix-up prompt, including question decomposition, answer generation, and conflict checking via comparing with edited facts. However, the coupling nature of them might cause conflict
②So they proposed Programmable knowledge editing for Multi-hop Question Answering (PokeMQA)
2.2. Introduction
①Example of Multi-hop question answering (MQA):
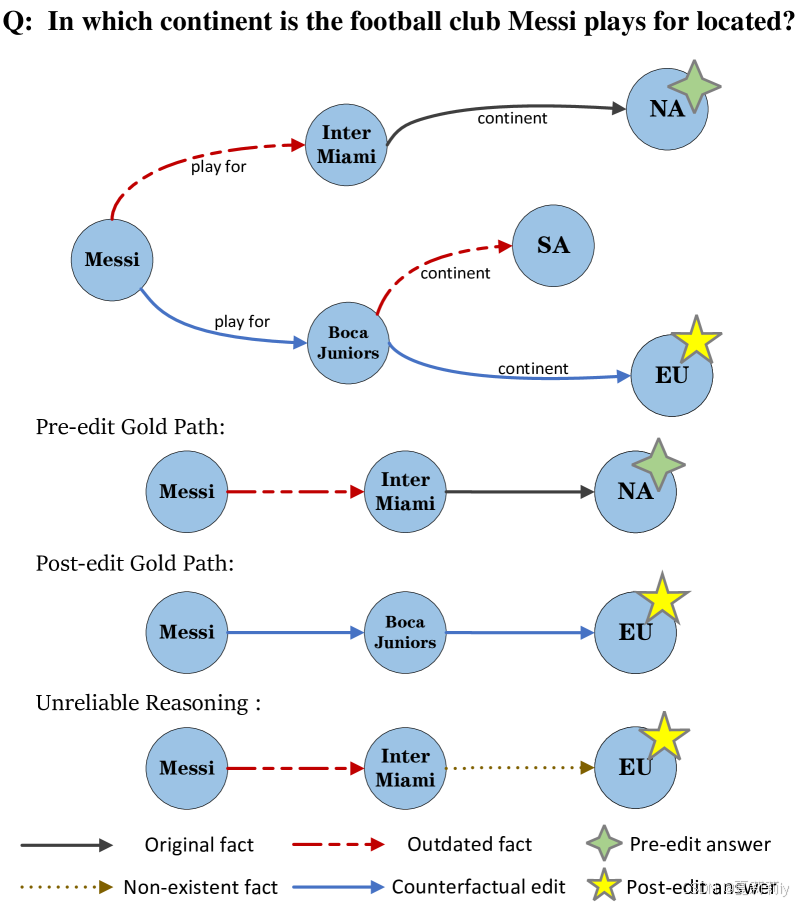
where blue lines are correct reasoning
②Methods for fine tune outdated knowledge (the authors used the second one):
| parameter-modification based editing | modifies the internal model weights according to edited facts through meta-learning, fine-tuning, or knowledge locating |
| memory-based editing | leverages an external memory to explicitly store the edited facts (or termed as edits) and reason over them, while leaving LLMs parameters unchanged |
③Existing challenges for MQA: a) conflict detection, b) the incorporation of knowledge editing instruction introduces noise
2.3. Multi-hop Question Answering under Knowledge Editing
(1)Notations
①A triplet with subject
, object
and relation
, such as:
②To update this fact:
③Multi hop question: , where the answer of
needs sequentially querying and retrieving multiple facts
④Chain of facts:
where ,
is the final answer
⑤The unique inter-entity path
⑥Except for , all other entities
will not allowed to appear in
⑦Edit facts: just one change of a fact such as from
causes cascaded changes consequently:
and the inter-entity path will be:
(2)MQA under knowledge editing
①A set of edits:
②A language model:
③Edited language model:
(3)Edit scope
①Scopes of edit means the similar questions which corresponding to the same answer
syntactic adj.句法的
2.4. Programmable Editing in Memory of Multi-hop Question Answering
2.4.1. Workflow of PokeMQA
①Illustration of PokeMQA:
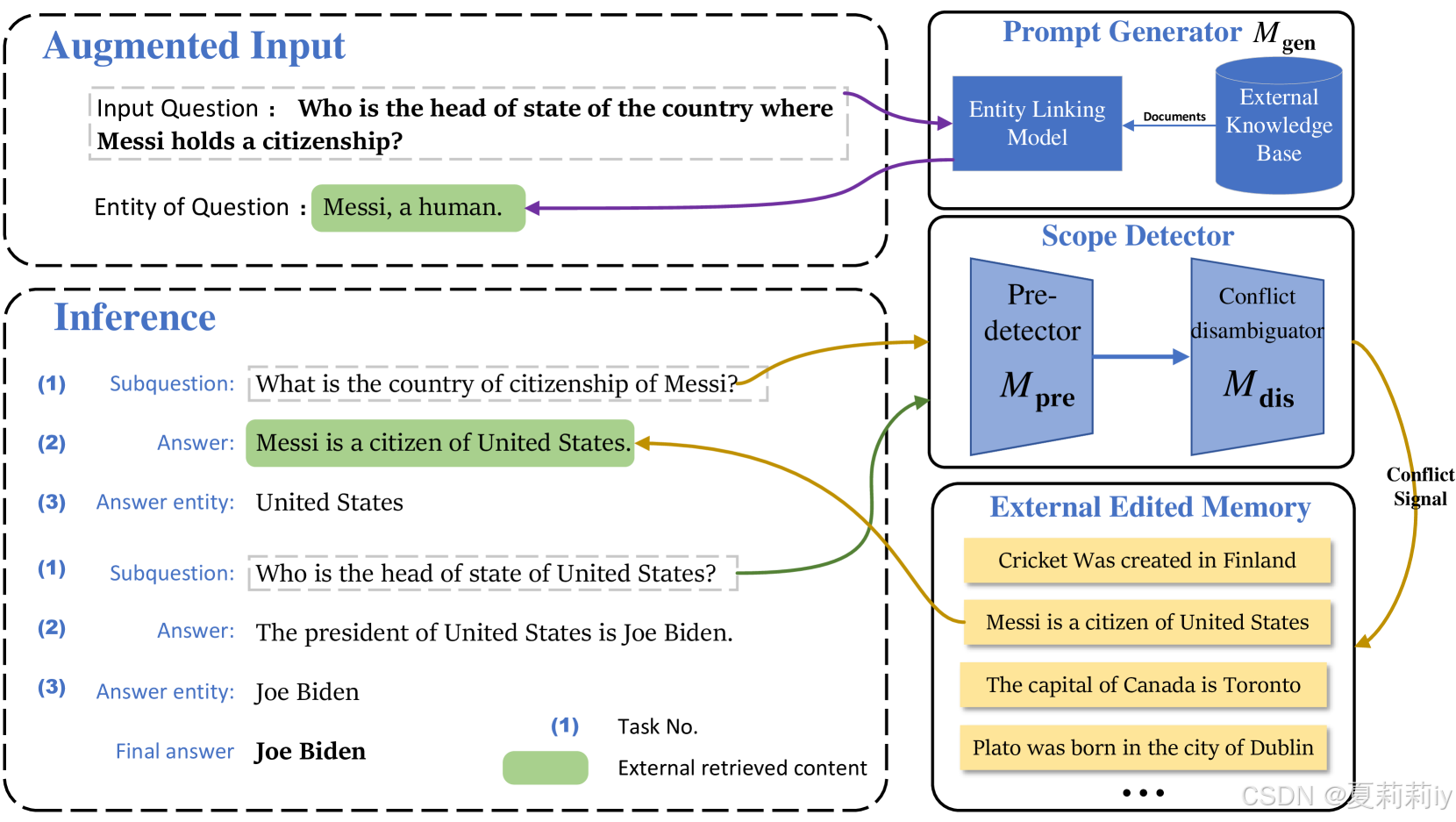
where Prompt Generator utilizes an external knowledge base to decomposite original , then use Scope Detector to further generate answers
②When receiving a set of edits , PokeMQA first uses manually-defined template to convert each edit triplet
into a natural language statement
(感觉在图中对应的就是把原句分解成俩子问题:
原句:Who is the head of state of the country where Messi () holds a citizenship?
子问题1():What is the country of citizenship (
) of Messi (
)?
答案1:United States ()
子问题2():Who is the head (
) of state of United States (
)?
答案2:Joe Biden ()
), then explicitly stores them in an external memory for query and retrieval.
③Models are taught to excute 3 tasks by few-shot prompt:
| 1 | Identify the next subquestion (i.e., atomic question) condi tioned on the input question and current inference state in LLMs |
| 2 | Detect whether this subquestion falls within the edit scope and generate answer |
| 3 | Extract the answer entity for this subquestion in LLMs |
④⭐Previous work always generated a tentative answer from model and retrieved edited facts for each question, but this was not realistic for few-shot prompts. So they change this to: retrieve subquestion in , then get answer from
otherwise generate by itself
⑤Key entity decomposite from the keeps helping to prompt due to the difficult of decompositing the input for the first subquetion
2.4.2. Programmable Scope Detector
(1)Architectures
①Scope detector: , which pre dicts the probability that an atomic question
falls into the scope of the edit statement
(in terms of the edit
)
②They employ 2 complementary models for expressiveness and computational efficiency: and
③ (predetector
) calculates the embeddings for
and
separately and models the log-likelihood by the negative squared Euclidean distance in the embedding space, which filters irrelevant edits
④ (conflict disambiguator
) con catenates
and
together as a unified input for the sequence classification task, which achieve accurate task classification
(2)Training scope detector
①Training set:
②BCE loss:
where denotes negative sampling distribution
③ and
are trained separately
(3)Model selection
①The authors design Success Rate and Block Rate to guide early stopping
②Success Rate measures the accuracy to retrieve the correct edit statement for a target question
from a set of candidates
where is indicator function,
denotes the size of validation set
,
is "and gate"
③Block Rate quantifies the extent of detector models to inhibit the unrelated edit statements for a target question:
where
2.4.3. Knowledge Prompt Generator
①They introduce knowledge prompt generator (ELQ model) to quickly link
to an entity from Wikidata
②Store triplets in Wikidata
③2 basic membership properties , where
,
(这个就是大图中最左上图Messi, a human的来源)
2.5. Experimental Setup
①Knowledge editing dataset: MQUAKE, which including MQUAKE-CF-3Kbasedoncoun terfactual edits, and MQUAKE-T with temporal knowledge updates
②Hop questions in dataset:
2.5.1. Evaluation Metrics
①Metrics: multi-hop accuracy and hop-wise answering accuracy (Hop-Acc)
2.5.2. Baselines Methods & Language Models
①Compared parameter updating methods: FT, ROME, MEMIT
②Compared memory-based method: MeLLo
③LLMs: LLaMa-2-7B, Vicuna-7B, GPT-3.5-turbo-instruct
2.5.3. Implementation Details
①Finetune and
by DistilBERT
②Sampling method: stratified sampling
2.6. Performance Analysis
2.6.1. Main Results
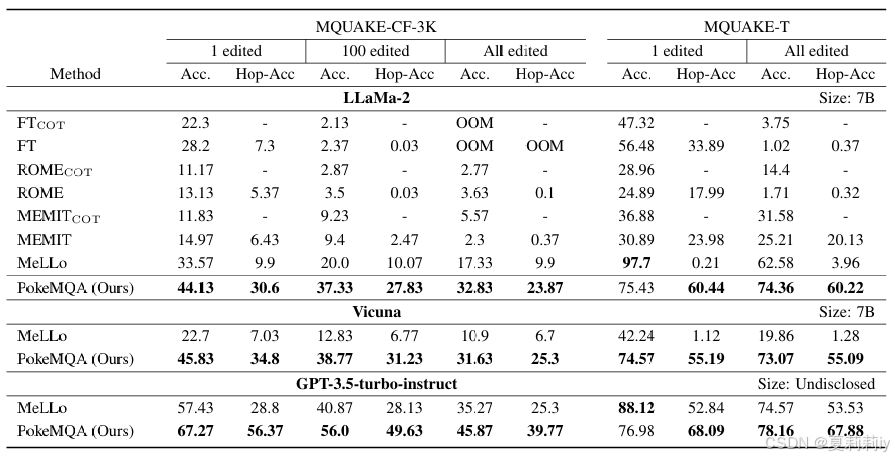
①Performance table:
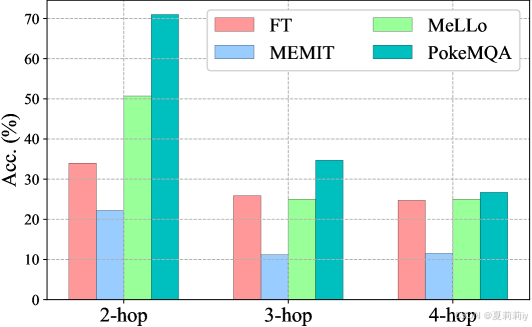
②Different acc and hop-acc of LLaMa-2-7B on MQUAKE-CF-3K:
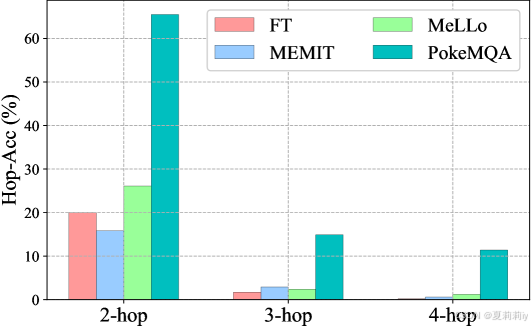
2.6.2. Ablation Study
①Module ablation in GPT-3.5-turbo-instruct on MQUAKE-CF-3K:
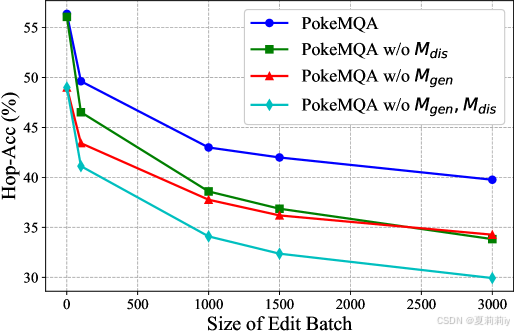
②Module ablation table:

2.7. Related Work
①Knowledge editing methods
2.8. Conclusion
①Limitations: a) accuracy of retrieval, b) safe technique required
3. 知识补充
3.1. Knowledge editing
(1)定义
Knowledge Editing(知识编辑) 是指对知识库(如知识图谱、知识库、模型的知识表示等)中的现有知识进行修改、更新、修正或增添的过程。这一过程不仅限于添加新的事实或知识,还包括修改、删除、纠正错误的知识,或者在已有的知识基础上引入新的上下文和关系。
在自然语言处理和知识图谱领域,知识编辑的目的是使得知识库或模型中的知识更加准确、一致和及时。这对于提升智能系统(如问答系统、推理系统等)的表现至关重要,尤其是在知识是动态变化的环境中。
(2)应用
①修正错误:如果知识库中的某个事实是错误的(例如,日期、地点、人物等信息错误),知识编辑可以帮助纠正这些错误。
②扩展和更新知识:随着新信息的到来,知识库需要不断更新。例如,新增的科学发现、新的社会事件等都需要通过知识编辑进行更新。
③对抗偏见:知识库中的偏见或不准确的信息(如刻板印象、政治偏见等)也可以通过知识编辑进行修正,以提高知识的公平性和准确性。
④自动化学习:一些系统可以通过从大量文本数据中自动提取新事实并编辑到已有的知识库中,从而让系统不断完善其知识。
(3)挑战
①复杂的推理:在编辑现有知识时,可能需要考虑其与其他事实之间的关系,确保新加入的知识不会破坏原有的知识一致性。
②知识验证:需要有效的方法来验证知识编辑的正确性,尤其是在知识图谱中,如何确认新添加的事实没有与已有的知识发生冲突是一个挑战。
③处理不同来源的知识:如何整合来自多个不同来源的信息并进行一致的知识编辑,尤其是当不同来源的事实不一致时,如何做出合理的编辑决策。
(4)技术实现
①基于规则的编辑:利用一系列手工编写的规则进行知识库更新。例如,可以通过手动规则检查和纠正日期、地点等事实的准确性。
②基于学习的编辑:使用机器学习方法(如文本分类、实体关系抽取等)来自动检测知识库中的错误或不一致,并进行自动化的知识编辑。
③人机协作:结合人工审核和自动化编辑来确保编辑的质量和准确性。例如,自动化系统可以检测潜在的错误,而人类专家可以做出最终决定。
④自然语言生成(NLG)和推理:使用语言模型(如GPT、BERT)自动生成或推理出新知识,以便对知识图谱进行有效的更新。例如,可以使用大型预训练语言模型从文本中提取出新的事实,并将其作为编辑后的事实插入知识库。
3.2. 用于对比学习和判别模型的BCE变体
(1)公式
(2)解释
这个公式涉及的是一个正样本和多个负样本(取平均)的对比学习,第一项是正样本对,第二项是负样本对。作者定义,即需要使得
趋近于1,得到高的匹配得分来最小化第一项。第二项
不匹配项则需要越小越好,这样第二项也能接近0。无论如何,这个损失应该都是大于0的,应该。
4. Reference
Gu, H. et al. (2024) PokeMQA: Programmable knowledge editing for Multi-hop Question Answering, ACL.


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









