



第一种:串行,将多个神经网络模块按顺序连接起来,形成一个统一的网络结构,它提供了一种相对简单直接的方法来整合多个网络模块,有助于提升模型的性能,同时保持了一定的灵活性,有串行连接、串行注意力机制、串行Transformer融合等等,是一种直接、粗暴的方法(典型案例:ResNet、DenseNet)

除了这四种方法,还给大家分享80多个即插即用的深度学习模块,能快速组合出各种设计好的模块,搭建出我们需要的模型,不仅让建模速度提升,还保证了模型的创新性和有效性,以及2024年各大顶会的最新优质论文合集,包含了整整1500篇,可以了解到AI最新发展以及热门方向。

章中所有的数据和资料,可添加小助手无偿分享~
扫码添加小助手即可无偿获取~
也可以关注“AI技术星球”公众号,关注后回复“221C”获取。

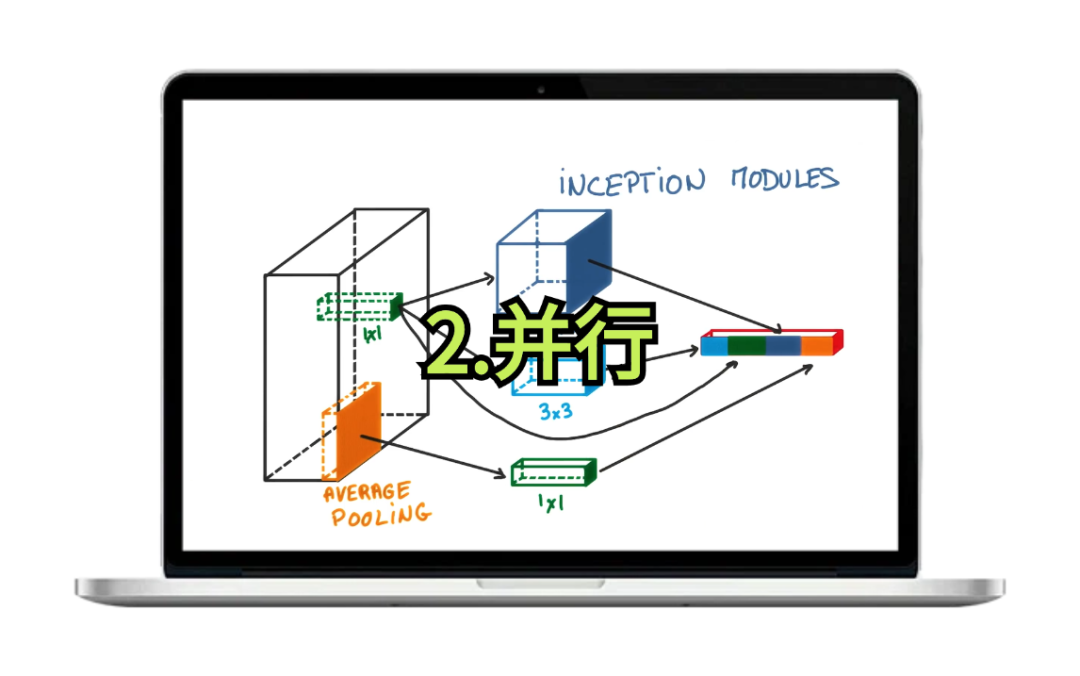
第二种:并行,将不同的网络模块同时运行,然后合并它们输出的方法,主要思想是利用多个网络模块的计算能力,通过同时处理数据来提高效率和性能,常见的有并行注意力机制和特征拼接、并行特征金字塔网络、并行卷积块等等(典型案例:GoogLeNet、ResNeXt)
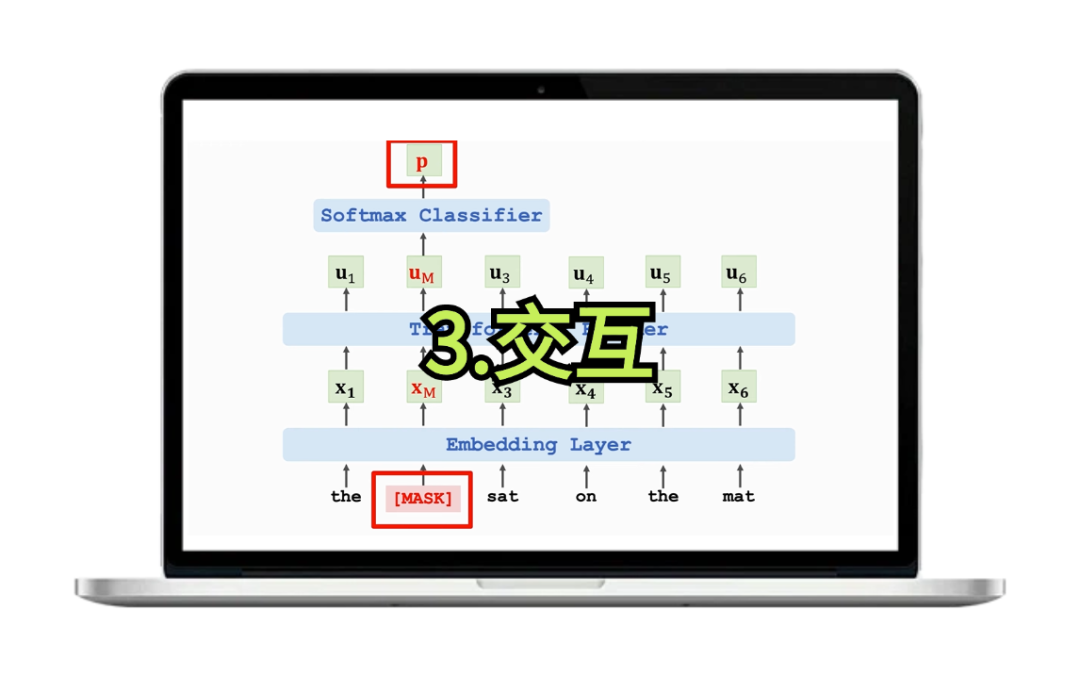
第三种:交互,将不同的网络模块以交互的方式进行组合的方法,它通常涉及模型架构的创新和模块的整合,其核心在于不同网络模块之间的相互作用和信息交换,常见的有特征交叉网络、自注意力交互、多模态交互等等(典型案例:BERT、U-Net)
第四种:多尺度融合,用于结合来自不同尺度的特征信息,优势在于能够同时捕捉到图像的细节信息和全局上下文信息,这对于许多视觉任务来说是非常重要,常见的有金字塔池化、金字塔注意力机制等等(典型案例:FPN、PAN)

灵活运用这些方法能帮助你快速搭建出自己想要的模型,提高学习的效率,分享到这就结束了,我们下期再见!
章中所有的数据和资料,可添加小助手无偿分享~
扫码添加小助手即可无偿获取~
也可以关注“AI技术星球”公众号,关注后回复“221C”获取。


















 2344
2344

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









