



如果你想快速增强模型的特征提取能力,提高准确性,亦或是降低模型计算复杂度,强烈建议你试试这个热门方法:小波变换+注意力机制!
近期其连中多篇顶会!模型MAWNO,更是通过将自注意力与小波变换结合,实现预测误差降低10倍,刷新多项SOTA的效果!
这主要是因为,小波变换能够对信号进行多尺度分解,捕捉到信号在不同尺度上的细节信息。而注意力机制的动态权重分配能力,可以突出小波变换分解后的重要特征,减少噪声和无关信息的干扰,从而既能提高模型性能,也能降低计算成本!
为让大家对该思路有全面深入的了解,快速涨点,我给大家准备了9种创新方法,原文和源码都有。大家可以结合自己的场景,灵活选择不同的注意力机制和小波基函数类型。
扫描下方二维码
免费获取全部论文合集及项目代码

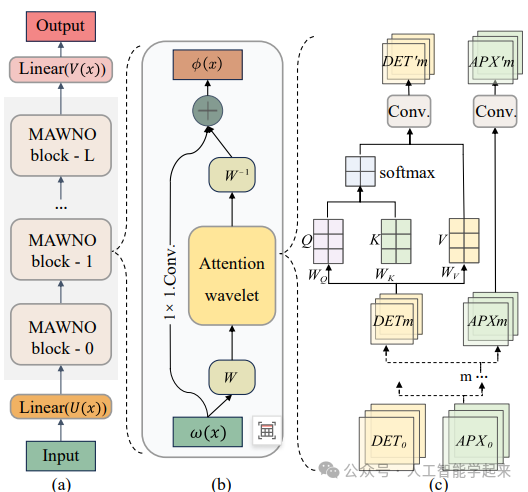
Multiscale Attention Wavelet Neural Operator for Capturing Steep Trajectories in Biochemical Systems
方法:论文提出了一种名为多尺度注意力小波神经算子的创新方法,该方法综合了注意力机制和小波变换技术,以有效捕捉生化系统中的急剧变化轨迹。MAWNO通过在多个小波尺度上分解输入数据来提取信号的特征,并引入自注意力机制来增强高频信号中的小波系数,从而更好地表征突然的切换。
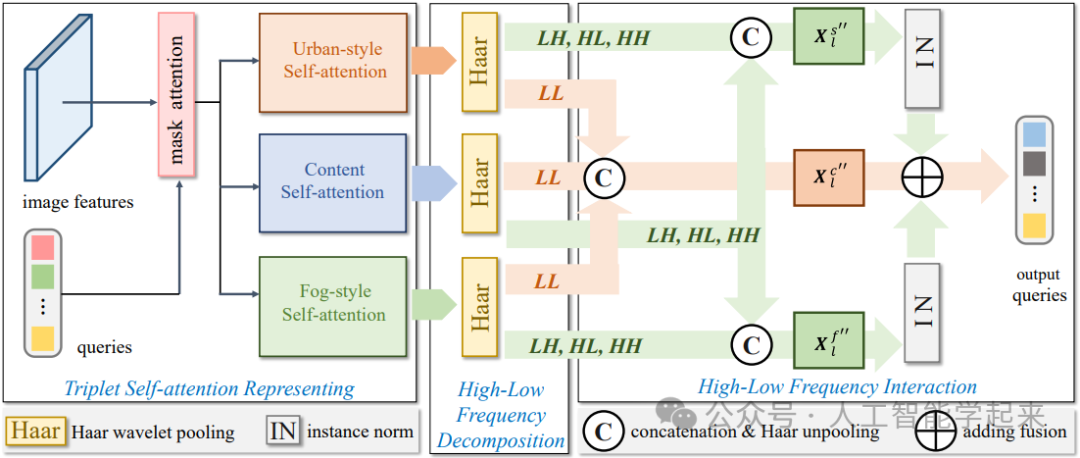
Learning Generalized Segmentation for Foggy-Scenes by Bi-directional Wavelet Guidance
方法:论文提出了一种新颖的双向小波引导机制,用于学习能够良好泛化到雾天场景的语义分割。该方法在训练阶段不涉及任何雾天图像,目的是泛化到任意未见过的雾天场景。BWG机制利用Haar小波变换将图像内容与风格(包括城市景观风格和雾风格)分离,通过独立处理低频和高频特征来增强内容、解耦城市风格和解耦雾风格。
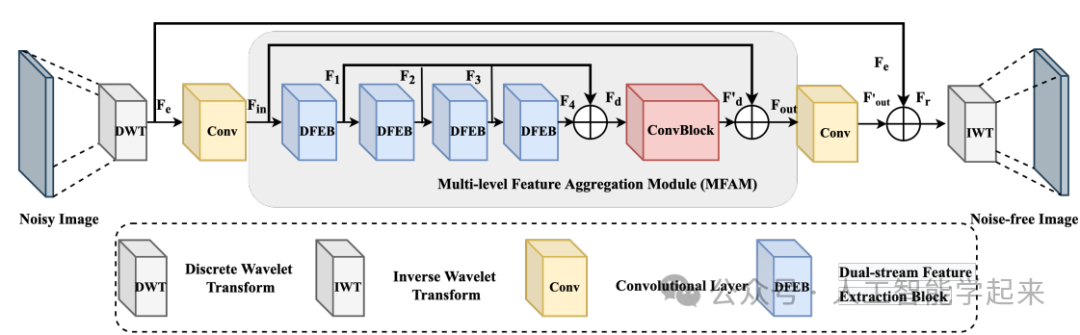
EWT: Efficient Wavelet-Transformer for Single Image Denoising
方法:论文提出了一种名为高效小波变换器的图像去噪方法。该方法通过离散小波变换和逆小波变换进行下采样和上采样,以降低图像分辨率并减少GPU存储消耗,同时保留图像特征。EWT还引入了一个新颖的双流特征提取块,用于在不同层次提取图像特征,进一步减少模型推理时间。
扫描下方二维码
免费获取全部论文合集及项目代码
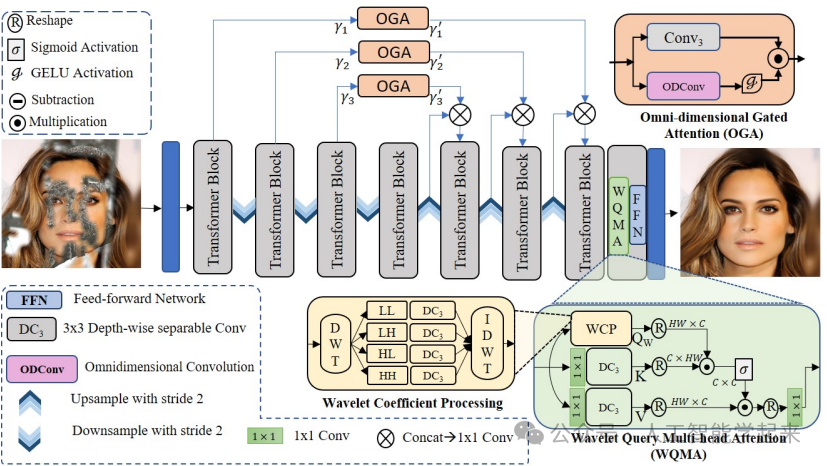
Blind Image Inpainting via Omni-dimensional Gated Attention and Wavelet Queries
方法:论文提出了一种用于盲图像修复的端到端变换器架构,该架构包含小波查询多头注意力变换器块和全维门控注意力机制。通过小波变换处理图像并将其作为查询传递给多头注意力机制,以减少噪声的影响,并利用全维门控注意力机制将编码器特征有效地传递给解码器,从而实现对图像中损坏区域的有效修复。
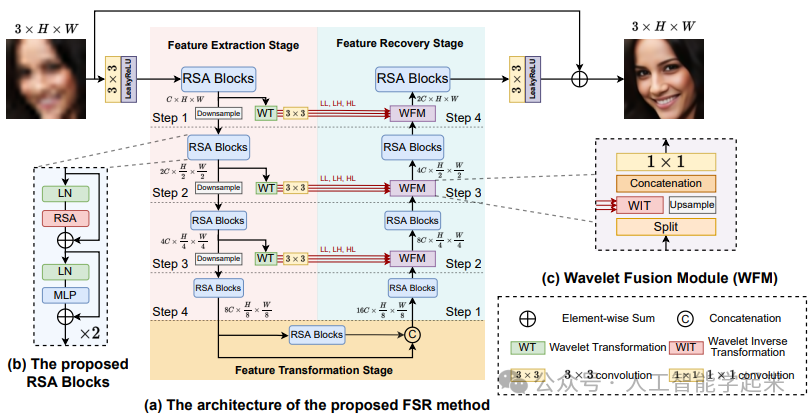
Learning Attention from Attention: Efficient Self-Refinement Transformer for Face Super-Resolution
方法:论文提出了一种用于人脸超分辨率任务的高效自精炼变换器架构,称为区域选择注意力。该方法首先通过粗粒度自注意力重建粗纹理,并检测需要进一步补偿的细粒度区域,然后执行区域选择注意力以精细化关键区域的纹理。为了在特征提取中考虑通道信息的重要性,论文还引入了双分支特征集成模块,并设计了小波融合模块,通过频率域的分解和重组来调制浅层和深层的特征图,以实现更真实人脸图像的恢复。
扫描下方二维码
免费获取全部论文合集及项目代码



















 408
408

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









