






DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Introduction
DeepSeek-R1-Zero is a model that applies RL directly to the base model without any SFT data, exhibiting super performance on reasoning benchmarks.
DeepSeek-R1, which applies RL starting from a checkpoint fine-tuned with thousands of long Chain-of-Thought (CoT) examples, gaining comparable performance with the most outstanding closed-source model, OpenAI-o1-1217.
Approach
DeepSeek-R1-Zero
Reinforcement Learning Algorithm
Group Relative Policy Optimization (GRPO) is a variant of GRPO, which forgoes Value Model in PPO to reduce the cost of training. The objective of GRPO is
J
G
R
P
O
(
θ
)
=
E
q
∼
P
(
Q
)
,
{
o
i
}
i
=
1
G
∼
π
θ
o
l
d
(
O
∣
q
)
[
1
G
∑
i
=
1
G
{
min
[
π
θ
(
o
i
∣
q
)
π
θ
o
l
d
(
o
i
∣
q
)
A
i
,
clip
(
π
θ
(
o
i
∣
q
)
π
θ
o
l
d
(
o
i
∣
q
)
,
1
−
ϵ
,
1
+
ϵ
)
A
i
]
−
β
D
K
L
[
π
θ
∥
π
r
e
f
]
}
]
,
D
K
L
[
π
θ
∥
π
r
e
f
]
=
π
r
e
f
(
o
i
∣
q
)
π
θ
(
o
i
∣
q
)
−
log
π
r
e
f
(
o
i
∣
q
)
π
θ
(
o
i
∣
q
)
−
1
,
A
i
=
r
i
−
mean
(
{
r
1
,
r
2
,
⋯
,
r
G
}
)
std
(
{
r
1
,
r
2
,
⋯
,
r
G
}
)
.
\mathcal{J}_{GRPO}(\theta) = \mathbb{E}_{q\sim P(Q),\{o_i\}_{i=1}^G\sim\pi_{\theta_{old}}(O|q)}\\ \left[ \frac{1}{G}\sum_{i=1}^G \left\{ \min \left[ \frac{\pi_\theta(o_{i}|q)}{\pi_{\theta_{old}}(o_{i}|q)}{A}_{i}, \text{clip}\left( \frac{\pi_\theta(o_{i}|q)}{\pi_{\theta_{old}}(o_{i}|q)}, 1-\epsilon, 1+\epsilon \right){A}_{i} \right] - \beta\mathbb{D}_{KL}[\pi_\theta\Vert\pi_{ref}] \right\} \right],\\ \mathbb{D}_{KL}[\pi_\theta\Vert\pi_{ref}] = \frac{\pi_{ref}(o_{i}|q)}{\pi_\theta(o_{i}|q)}-\log\frac{\pi_{ref}(o_{i}|q)}{\pi_\theta(o_{i}|q)}-1,\\ {A}_{i}=\frac{r_{i}-\text{mean}(\{r_{1},r_{2},\cdots,r_{G}\})}{\text{std}(\{r_{1},r_{2},\cdots,r_{G}\})}.
JGRPO(θ)=Eq∼P(Q),{oi}i=1G∼πθold(O∣q)[G1i=1∑G{min[πθold(oi∣q)πθ(oi∣q)Ai,clip(πθold(oi∣q)πθ(oi∣q),1−ϵ,1+ϵ)Ai]−βDKL[πθ∥πref]}],DKL[πθ∥πref]=πθ(oi∣q)πref(oi∣q)−logπθ(oi∣q)πref(oi∣q)−1,Ai=std({r1,r2,⋯,rG})ri−mean({r1,r2,⋯,rG}).
where
{
o
i
}
i
=
1
G
\{o_i\}_{i=1}^G
{oi}i=1G is a group of outputs sampled from the same question
q
q
q.
Compare the formula with its initial form in DeepSeekMath, we can find variable t t t, representing the index of token, disappeared, because the Reward Model in GRPO only gives reward based on entire output, not each token. So, in GRPO there is only once reward for each sampled output.
Reward Modeling
The reward of GRPO is also relatively simple, mainly consisting of two parts: Accuracy rewards and Format rewards.
- Accuracy rewards: Evaluate whether the answer is correct. It is easy for problems with deterministic answer like math or coding, but it is not clear how DeepSeek evaluate uncertain answer.
- Format rewards: Enforces the model to put its thinking process between ‘’ and ‘’ tags.
There is no neural reward model in developing DeepSeek-R1-Zero, because we find that the neural reward model may suffer from reward hacking in the large-scale reinforcement learning process, making the training complicated.
Prompt Template

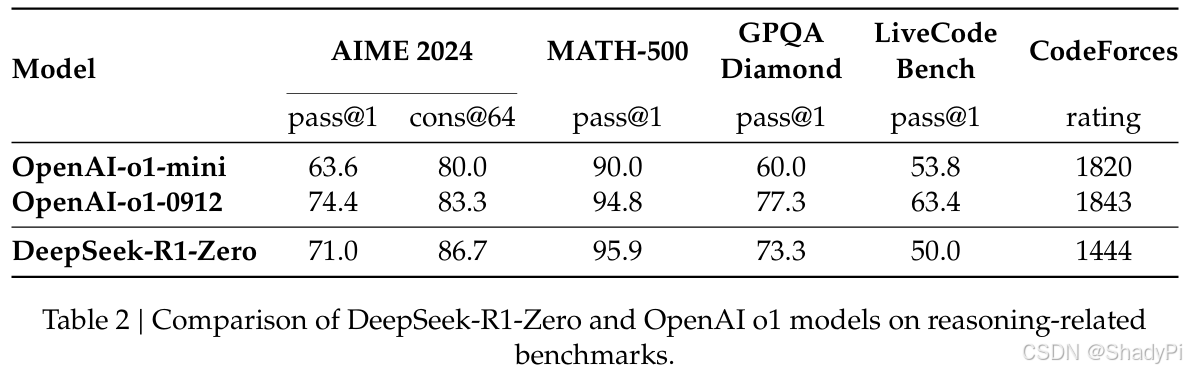
Results
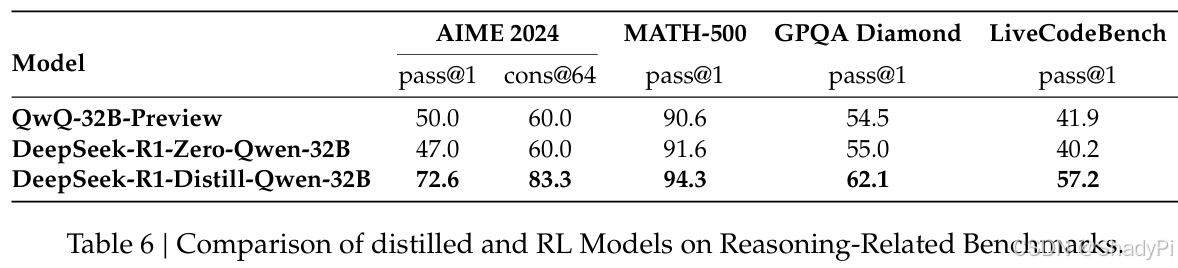
performance
DeepSeek-R1-Zero to attain robust reasoning capabilities without the need for any supervised fine-tuning data, gaining comparable performance with OpenAI-o1-0912 on math and coding tasks.
Self-evolution
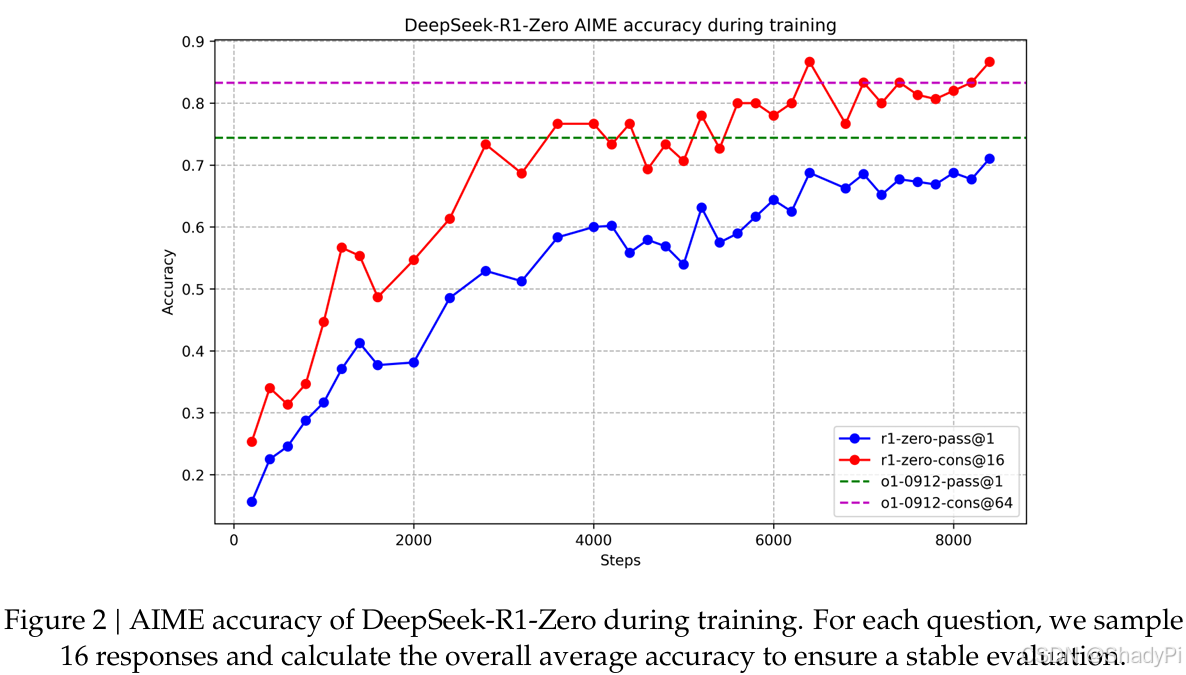
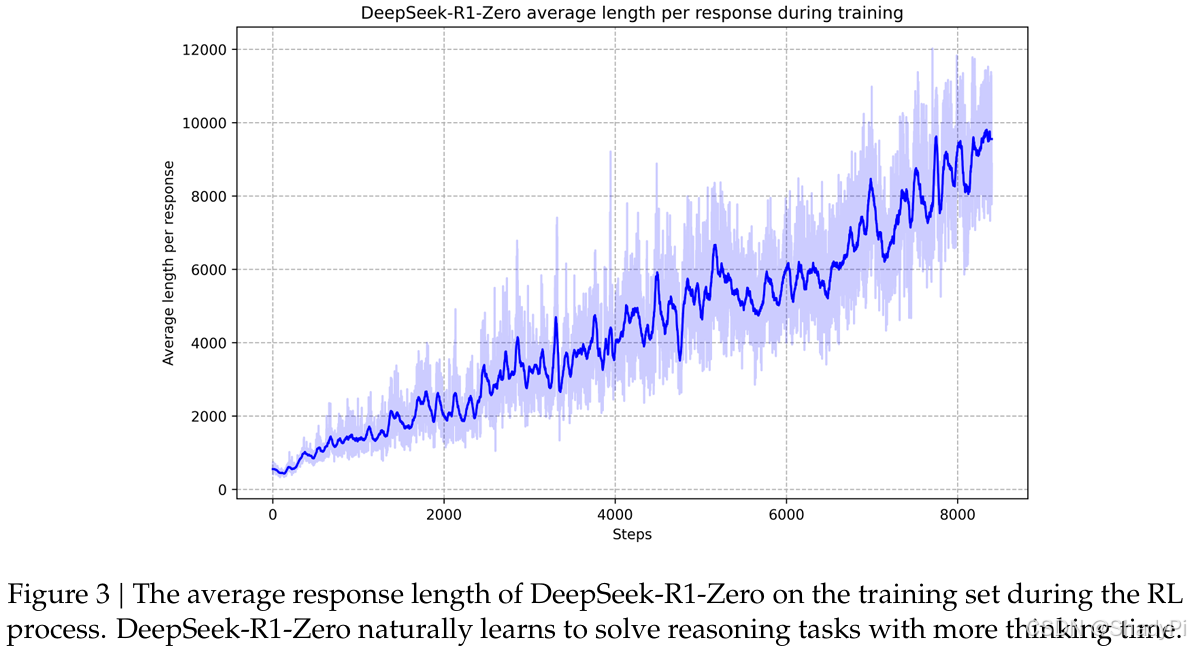
By looking at the accuracy-steps and response length-steps curve during RL, we can find that the model gradually generates more accurate response with longer length. It shows that the model naturally learns to handle difficult reasoning problems with more thinking steps.
Aha Moment
In an intermediate version of the model presents the behavior that it will re-evaluate its previous thinking and revise it. Which is very unexpected and impossible in SFT.

Drawbacks: poor readability and language mixing.
DeepSeek-R1
To further improve the ability of model and overcome the drawbacks above, SFT is stilled applied.
Cold Start
The authors add a small, long-CoT SFT before RL, named Cold Start. The used data is collected from few-shot prompting with human refines, resulting in thousands of long-CoT cold start data. Cold start increases the readability and potential in subsequent training.
Reasoning-oriented RL
The same dataset as DeepSeek-R1-Zero, in reasoning-intensive tasks such as coding, mathematics, science, and logic reasoning, is used to do GRPO fine-tuning. A language consistency reward, calculated by the portion of target language, is added into the final reward to overcome mixing language issue.
Rejection Sampling and SFT
Because the data above are all focused on reasoning, it is needed to collect some general task data to enhance the model’s generalizability. The authors perform rejection sampling to collect high-quality samples from the generation of DeepSeek-R1 (after reasoning RL version). In this stage, they also include questions that need a generative model, like DeepSeek-V3, to give reward. For non-reasoning data, they use DeepSeek-V3 to generate a potential CoT before answer. In total, they collect 600K reasoning data and 200K non-reasoning data.
The authors fine-tune DeepSeek-V3-Base for two epochs using the above curated dataset of about 800k samples.
RL for all
Using data collected above, the model goes under RL again. For reasoning data, the reward aligns with DeepSeek-R1-Zero, only evaluates the final result. For general data, they build a DeepSeek-V3 pipeline to evaluate the final summary, and minimizing the interference with reasoning process. (but harmfulness evaluation is applied on the whole generation)
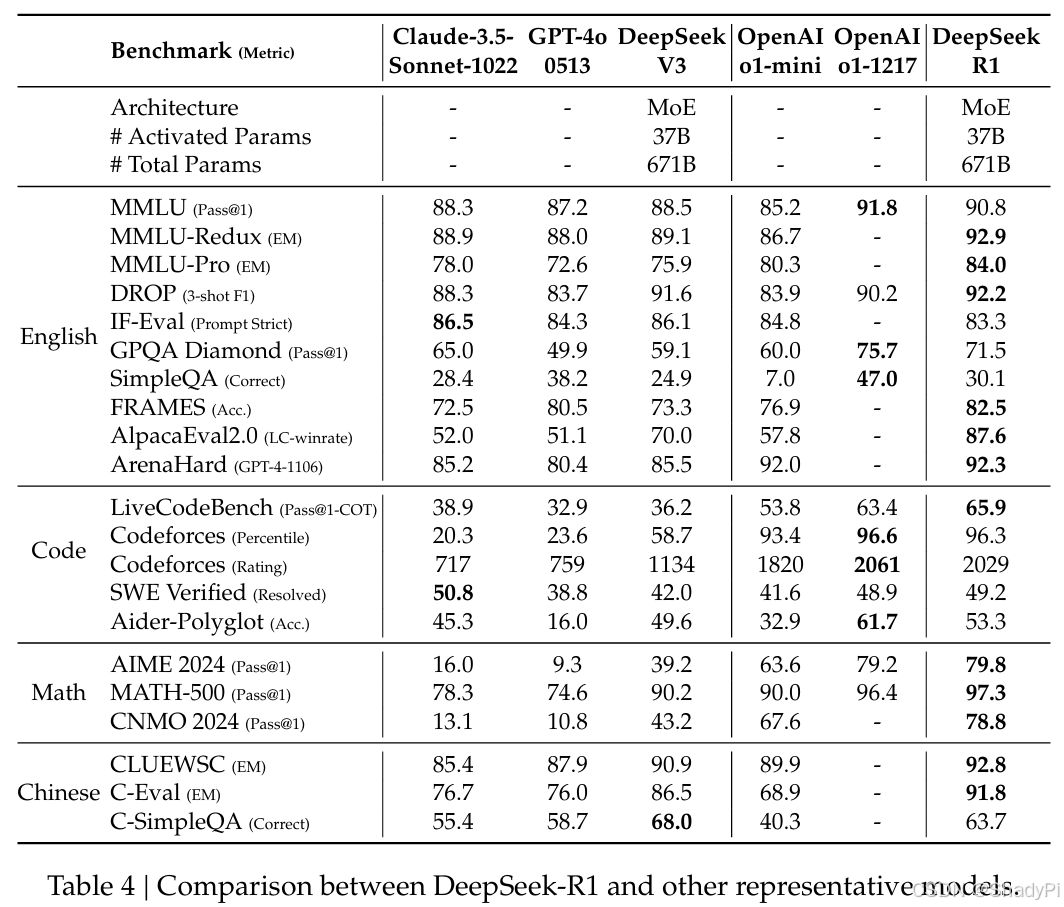
Distillation
Using 800K samples curated with DeepSeek-R1, only SFT is applied to distill knowledge to smaller models.
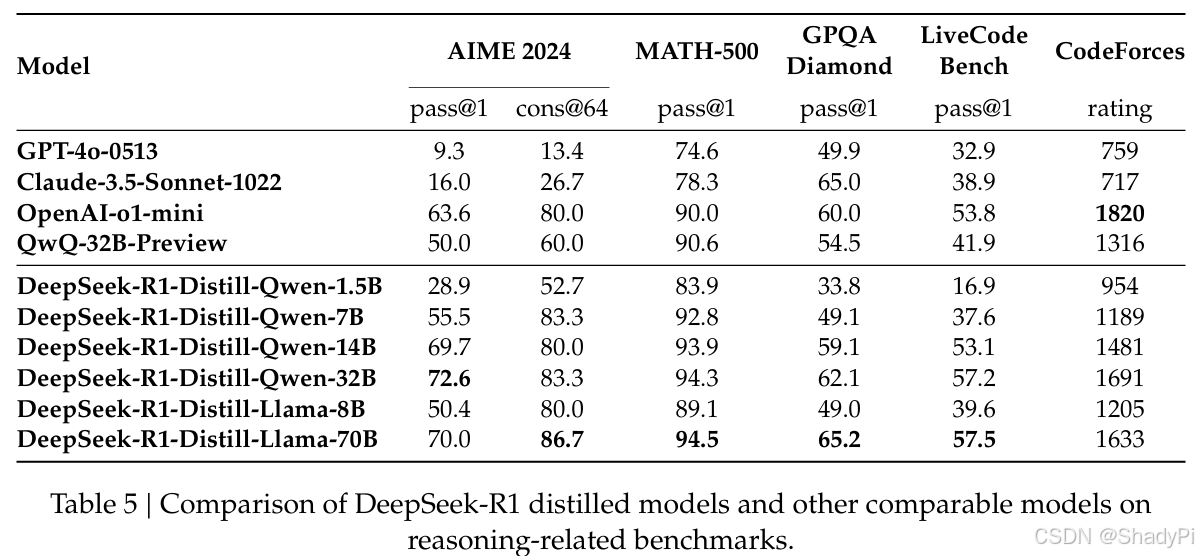
Simply distilling DeepSeek-R1’s outputs enables the efficient DeepSeek-R1-7B. The smaller model learns and improves a lot. However, conducting large-scale RL training on smaller models, like Qwen-32B-Base, does not work well. The model does not gain any benefits from directly RL training.
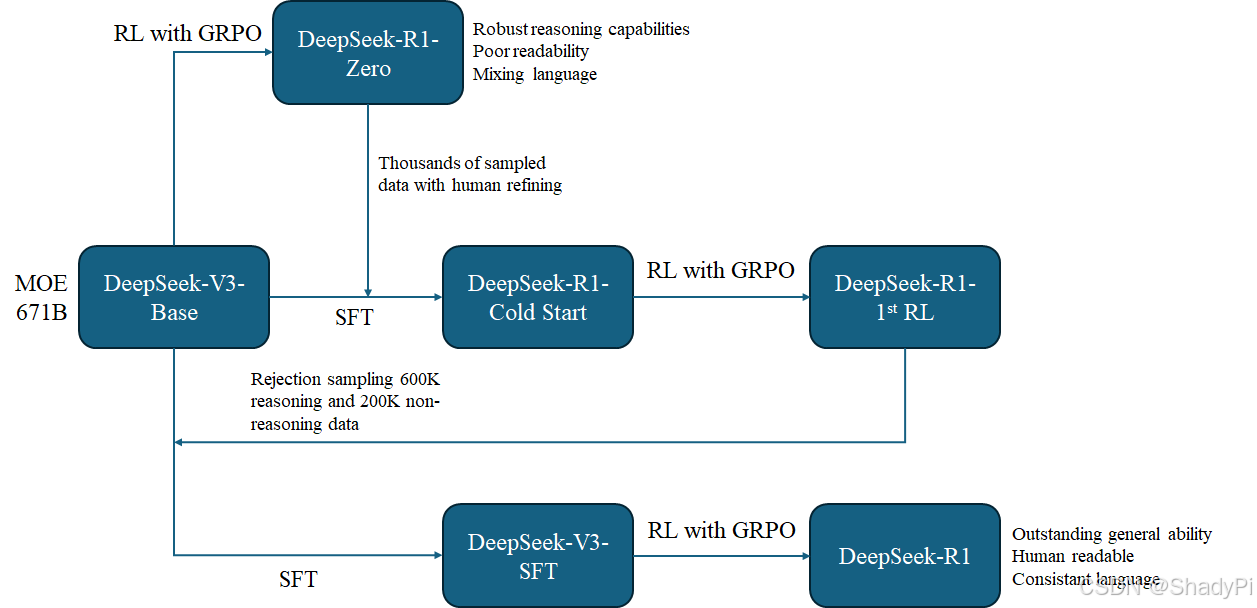
Workflow
There are a lot of models appearing in this paper. According to my understanding, I drew a flow chart to summarize the whole process. There are 3 branches coming out from the DeepSeek-V3 and obtained different models.


















 162
162

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











