




 本文详细介绍了一次基于吴恩达课程的线性回归实践,包括数据预处理、特征值归一化、添加x0项、梯度下降算法实现及预测过程。
本文详细介绍了一次基于吴恩达课程的线性回归实践,包括数据预处理、特征值归一化、添加x0项、梯度下降算法实现及预测过程。
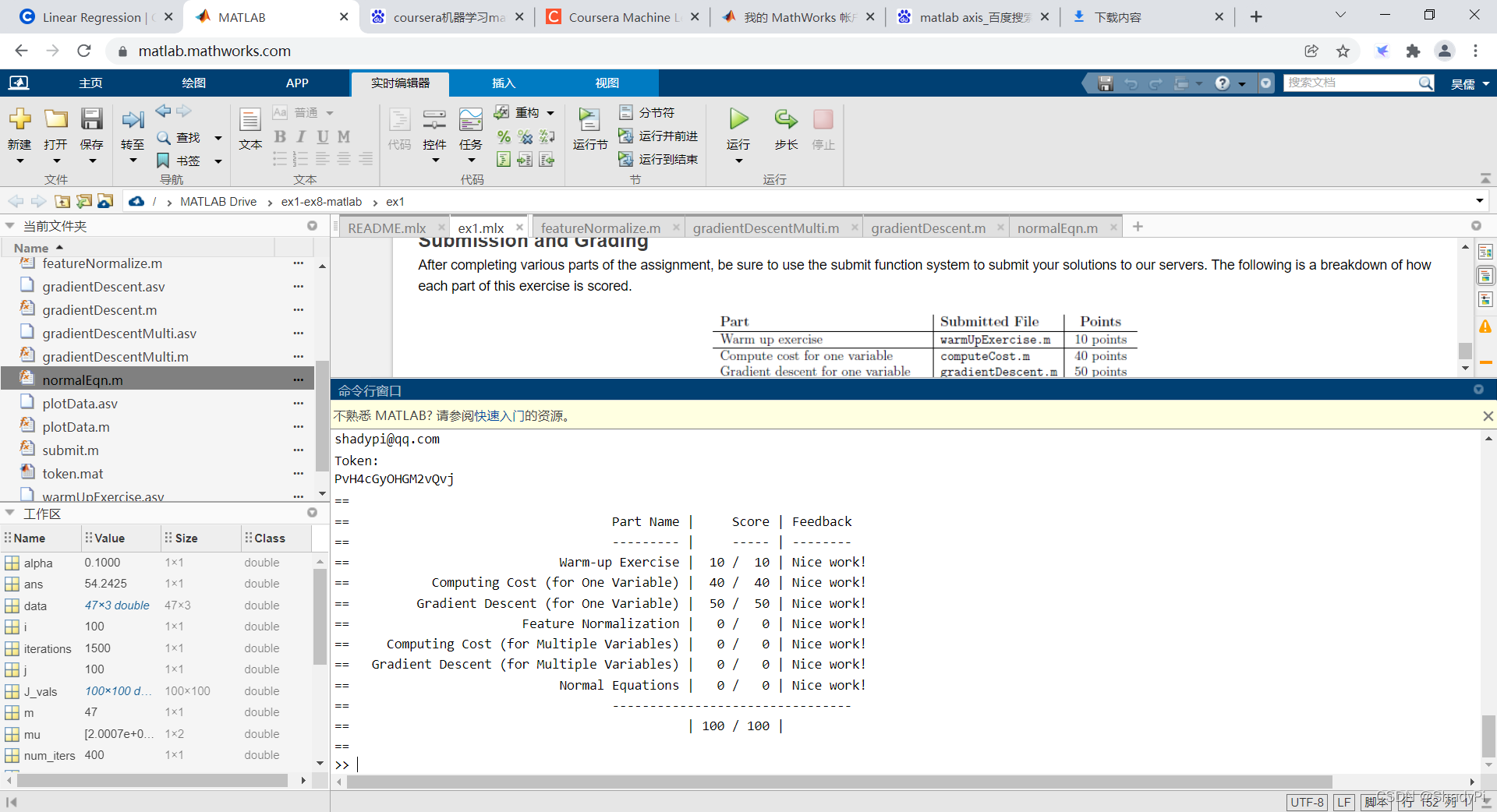
刚做完吴恩达的作业,毕竟是第一个机器学习算法,不发一下对不起自己😀
数据导入
% Load Data
data = load('ex1data2.txt');
X = data(:, 1:2);
y = data(:, 3);
m = length(y);
% Print out some data points
% First 10 examples from the dataset
fprintf(' x = [%.0f %.0f], y = %.0f \n', [X(1:10,:) y(1:10,:)]');
吴恩达写的代码,data = load('ex1data2.txt');将数据先读进来,然后用X = data(:, 1:2);y = data(:, 3);将数据中的一二列取出来放到X作为特征值,把第三列取出来放到y作为解,顺便用m = length(y);把样本数求出来。
特征值归一化
function [X_norm, mu, sigma] = featureNormalize(X)
%FEATURENORMALIZE Normalizes the features in X
% FEATURENORMALIZE(X) returns a normalized version of X where
% the mean value of each feature is 0 and the standard deviation
% is 1. This is often a good preprocessing step to do when
% working with learning algorithms.
% You need to set these values correctly
X_norm = X;
mu = zeros(1, size(X, 2));
sigma = zeros(1, size(X, 2));
% ====================== YOUR CODE HERE ======================
% Instructions: First, for each feature dimension, compute the mean
% of the feature and subtract it from the dataset,
% storing the mean value in mu. Next, compute the
% standard deviation of each feature and divide
% each feature by it's standard deviation, storing
% the standard deviation in sigma.
%
% Note that X is a matrix where each column is a
% feature and each row is an example. You need
% to perform the normalization separately for
% each feature.
%
% Hint: You might find the 'mean' and 'std' functions useful.
%
mu=mean(X);
sigma=std(X);
X_norm=(X-mu)./sigma;
% ============================================================
end
上面为特征值归一化函数,用mean()和std()函数把矩阵每一列的均值mu和标准差sigma求出来,之后X_norm=(X-mu)./sigma;把所有数据归一化,使其取值范围大致相等。
需要注意,这里求出来的mu和sigma数组也是要保留的,因为我们根据归一化数据求出来的线性回归在使用的时候要求待预测的变量同样进行了归一化。
调用归一化:
% Scale features and set them to zero mean
[X, mu, sigma] = featureNormalize(X);
添加 x 0 x_0 x0项
众所周知,因为线性回归里假设方程为
h
θ
=
θ
0
+
θ
1
x
1
+
θ
2
x
2
+
⋯
+
θ
n
x
n
h_\theta=\theta_0+\theta_1x_1+\theta_2x_2+\cdots+\theta_nx_n
hθ=θ0+θ1x1+θ2x2+⋯+θnxn
为了让这个方程更整齐,补一位
x
0
=
1
x_0=1
x0=1,就有
h
θ
=
θ
0
x
0
+
θ
1
x
1
+
θ
2
x
2
+
⋯
+
θ
n
x
n
=
[
x
0
x
1
⋯
x
n
]
[
θ
0
θ
1
⋮
θ
n
]
h_\theta=\theta_0x_0+\theta_1x_1+\theta_2x_2+\cdots+\theta_nx_n= \left[\begin{matrix} x_0&x_1&\cdots&x_n \end{matrix}\right] \left[\begin{matrix} \theta_0\\ \theta_1\\ \vdots\\ \theta_n \end{matrix}\right]
hθ=θ0x0+θ1x1+θ2x2+⋯+θnxn=[x0x1⋯xn]⎣⎢⎢⎢⎡θ0θ1⋮θn⎦⎥⎥⎥⎤
对于整个线性回归问题而言,令
X
=
[
x
0
(
1
)
x
1
(
1
)
⋯
x
n
(
1
)
x
0
(
2
)
x
1
(
2
)
⋯
x
n
(
2
)
⋮
⋮
⋱
⋮
x
0
(
m
)
x
1
(
m
)
⋯
x
n
(
m
)
]
,
Θ
=
[
θ
0
θ
1
⋮
θ
n
]
,
Y
=
[
y
1
y
2
⋮
y
m
]
X= \left[\begin{matrix} x_0^{(1)}&x_1^{(1)}&\cdots&x_n^{(1)}\\ x_0^{(2)}&x_1^{(2)}&\cdots&x_n^{(2)}\\ \vdots & \vdots & \ddots &\vdots\\ x_0^{(m)}&x_1^{(m)}&\cdots&x_n^{(m)}\\ \end{matrix}\right] ,\Theta=\left[\begin{matrix} \theta_0\\ \theta_1\\ \vdots \\ \theta_n\\ \end{matrix}\right], Y=\left[\begin{matrix} y_1\\ y_2\\ \vdots \\ y_m\\ \end{matrix}\right]
X=⎣⎢⎢⎢⎢⎡x0(1)x0(2)⋮x0(m)x1(1)x1(2)⋮x1(m)⋯⋯⋱⋯xn(1)xn(2)⋮xn(m)⎦⎥⎥⎥⎥⎤,Θ=⎣⎢⎢⎢⎡θ0θ1⋮θn⎦⎥⎥⎥⎤,Y=⎣⎢⎢⎢⎡y1y2⋮ym⎦⎥⎥⎥⎤
就有
H
θ
=
X
Θ
H_\theta=X\Theta\\
Hθ=XΘ
从而方便计算,所以我们要在特征矩阵X的左边加一列1:
% Add intercept term to X
X = [ones(m, 1) X];
梯度下降
梯度下降公式为
θ
j
:
=
θ
j
−
α
∂
J
(
θ
)
∂
θ
j
\theta_j:=\theta_j-\alpha\frac{\partial J(\theta)}{\partial\theta_j}
θj:=θj−α∂θj∂J(θ)
其中
J
(
θ
)
=
1
2
m
∑
i
=
1
m
(
θ
0
x
0
(
i
)
+
θ
1
x
1
(
i
)
+
⋯
+
θ
n
x
n
(
i
)
−
y
(
i
)
)
2
J(\theta)=\frac{1}{2m}\sum_{i=1}^m(\theta_0x_0^{(i)}+\theta_1x_1^{(i)}+\cdots+\theta_nx_n^{(i)}-y^{(i)})^2
J(θ)=2m1i=1∑m(θ0x0(i)+θ1x1(i)+⋯+θnxn(i)−y(i))2
求偏导为
∂
J
(
θ
)
∂
θ
j
=
1
m
∑
i
=
1
m
x
j
(
i
)
(
θ
0
x
0
(
i
)
+
θ
1
x
1
(
i
)
+
⋯
+
θ
n
x
n
(
i
)
−
y
(
i
)
)
\frac{\partial J(\theta)}{\partial \theta_j}=\frac{1}{m}\sum_{i=1}^m x_j^{(i)}(\theta_0x_0^{(i)}+\theta_1x_1^{(i)}+\cdots+\theta_nx_n^{(i)}-y^{(i)})
∂θj∂J(θ)=m1i=1∑mxj(i)(θ0x0(i)+θ1x1(i)+⋯+θnxn(i)−y(i))
后面的求和部分可以化成矩阵形式
[
x
j
(
1
)
x
j
(
2
)
⋯
x
j
(
m
)
]
(
[
x
0
(
1
)
x
1
(
1
)
⋯
x
n
(
1
)
x
0
(
2
)
x
1
(
2
)
⋯
x
n
(
2
)
⋮
⋮
⋱
⋮
x
0
(
m
)
x
1
(
m
)
⋯
x
n
(
m
)
]
[
θ
0
θ
1
⋮
θ
n
]
−
[
y
1
y
2
⋮
y
m
]
)
\left[\begin{matrix} x_j^{(1)}&x_j^{(2)}&\cdots&x_j^{(m)} \end{matrix}\right] \left( \left[\begin{matrix} x_0^{(1)}&x_1^{(1)}&\cdots&x_n^{(1)}\\ x_0^{(2)}&x_1^{(2)}&\cdots&x_n^{(2)}\\ \vdots & \vdots & \ddots &\vdots\\ x_0^{(m)}&x_1^{(m)}&\cdots&x_n^{(m)}\\ \end{matrix}\right] \left[\begin{matrix} \theta_0\\ \theta_1\\ \vdots \\ \theta_n\\ \end{matrix}\right]- \left[\begin{matrix} y_1\\ y_2\\ \vdots \\ y_m\\ \end{matrix}\right] \right)
[xj(1)xj(2)⋯xj(m)]⎝⎜⎜⎜⎜⎛⎣⎢⎢⎢⎢⎡x0(1)x0(2)⋮x0(m)x1(1)x1(2)⋮x1(m)⋯⋯⋱⋯xn(1)xn(2)⋮xn(m)⎦⎥⎥⎥⎥⎤⎣⎢⎢⎢⎡θ0θ1⋮θn⎦⎥⎥⎥⎤−⎣⎢⎢⎢⎡y1y2⋮ym⎦⎥⎥⎥⎤⎠⎟⎟⎟⎟⎞
故参数矩阵theta的运算为
Θ
:
=
Θ
−
α
m
X
T
(
X
Θ
−
Y
)
\Theta:=\Theta-\frac{\alpha}{m}X^T(X\Theta-Y)
Θ:=Θ−mαXT(XΘ−Y)
得益于matlab强大的向量运算,这玩意儿实现起来很容易:
function [theta, J_history] = gradientDescentMulti(X, y, theta, alpha, num_iters)
%GRADIENTDESCENTMULTI Performs gradient descent to learn theta
% theta = GRADIENTDESCENTMULTI(x, y, theta, alpha, num_iters) updates theta by
% taking num_iters gradient steps with learning rate alpha
% Initialize some useful values
m = length(y); % number of training examples
J_history = zeros(num_iters, 1);
for iter = 1:num_iters
% ====================== YOUR CODE HERE ======================
% Instructions: Perform a single gradient step on the parameter vector
% theta.
%
% Hint: While debugging, it can be useful to print out the values
% of the cost function (computeCostMulti) and gradient here.
%
theta=theta-(alpha/m).*X'*(X*theta-y);
% ============================================================
% Save the cost J in every iteration
J_history(iter) = computeCostMulti(X, y, theta);
end
end
之后调用该函数多次迭代就可以完成梯度下降算法了。
% Run gradient descent
% Choose some alpha value
alpha = 0.1;
num_iters = 400;
% Init Theta and Run Gradient Descent
theta = zeros(3, 1);
[theta, ~] = gradientDescentMulti(X, y, theta, alpha, num_iters);
% Display gradient descent's result
fprintf('Theta computed from gradient descent:\n%f\n%f\n%f',theta(1),theta(2),theta(3))
预测
要预测一个特征值为1650 3的数据,只需要把他归一化带进方程即可:
% Estimate the price of a 1650 sq-ft, 3 br house
% ====================== YOUR CODE HERE ======================
price = theta(1,1)+theta(2,1)*(1650-mu(1))/sigma(1)+theta(3,1)*(3-mu(2))/sigma(2); % Enter your price formula here
% ============================================================
fprintf('Predicted price of a 1650 sq-ft, 3 br house (using gradient descent):\n $%f', price);


















 9990
9990

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











