 表格解析全流程实战详解
表格解析全流程实战详解




在当今数据驱动的时代,表格数据作为信息承载的重要形式,广泛存在于各类商业场景中。从财务报表到保险理赔单,从销售记录到客户信息,表格无处不在。表格不仅仅是文本的堆砌,它包含着复杂的空间逻辑关系。如何让机器真正理解表格数据?这是金融、财务、保险等领域智能化转型的关键挑战。
本文将深入探讨表格解析的数据准备和模型训练全流程,为读者呈现一套完整可行的解决方案。
数据准备:质量决定上限
数据准备是整个表格解析流程的基石,数据质量直接决定了模型性能的上限。一个高质量的表格解析数据集需要兼顾多样性和准确性。
数据获取
表格数据的获取通常有三个主要来源:
-
开源数据集:入门和基准测试的首选,如PubTabNet等大型公开数据集,提供了多样化的表格样本,适合初步模型训练;
-
业务数据:提升模型领域适应性的关键,例如财务报表、保险理赔单等真实业务场景中的表格。这类数据往往包含行业特有的表格结构和专业术语;
-
抓取数据:通过对网络PDF、图片等格式的表格进行采集和初步处理,可以有效扩大数据规模。在金融领域,经常需要从历史报表文档中提取表格数据用于训练。
数据标注
数据标注是表格解析中最耗时的环节,合理的标注策略可以事半功倍:
-
预标注:利用现有模型对未标注数据进行初步标注,人工仅需修正错误,可显著提升效率。在表格解析中,可以先用通用模型检测表格区域和基本结构;
-
模型修正:通过迭代训练逐步提升标注质量,每次训练后的模型可以用于标注下一批数据,形成正向循环。也可以通过大模型进一步提升预标注数据的精度;
-
规则辅助修正:通过对特定表格(如全线表具有明显的线段表示)制定专门的规则来提升标注的效率;
-
人工修正:确保标注准确性,特别是对于复杂表格结构(如合并单元格、嵌套表头等),需专业标注人员介入。
数据合成
在真实数据稀缺的场景下,数据合成技术通过生成高质量的仿真样本,能有效突破训练数据规模的瓶颈,为模型提供更充分的学习材料。
构建一个适用于表格解析的合成数据框架,需高度模拟真实表格的视觉布局与语义内容,包括表格线、单元格结构、文本元素及其空间逻辑关系。其合成流程可系统划分为三个核心阶段:
1️⃣HTML结构生成:动态生成表格的底层 HTML 结构,模拟表格的逻辑结构。包括随机确定行数与列数、生成合并单元格,并填充文本内容。此过程确保了表格结构组合的多样性。
2️⃣图像渲染:利用浏览器等渲染引擎,对生成的HTML字符串进行精确渲染,将其转换为高保真的表格图像。这一步将表格的逻辑结构转化为像素级的视觉呈现。
3️⃣图像后处理与真值生成:对渲染出的完整页面图像进行精准裁剪,仅保留表格区域,排除无关干扰。同时,生成并保存与合成图像精确对应的标注文件(Ground Truth),其格式需与下游模型训练的要求相匹配。
合成数据的质量关键在于其多样性与丰富性。
-
多样性:旨在避免模型过拟合。通过变化表格样式(边框、线型)、文本字体、大小、风格,以及添加背景噪声、模拟印刷瑕疵等来实现。例如,在合成金融报表时,必须模拟不同机构特有的报表格式和可能出现的印刷质量差异。
-
丰富性:要求覆盖不同行业领域(财务、医疗等)以及各种复杂度的表格类型,从基础表格到包含多层表头、多级合并单元格的复杂结构表格,以确保模型训练的全面性。
通过上述系统性的合成框架,可以高效生成大规模、高质量且贴合实际应用场景的表格图像数据,为提升表格解析模型的准确性和鲁棒性奠定坚实基础。
模型训练:技巧与策略
模型设计
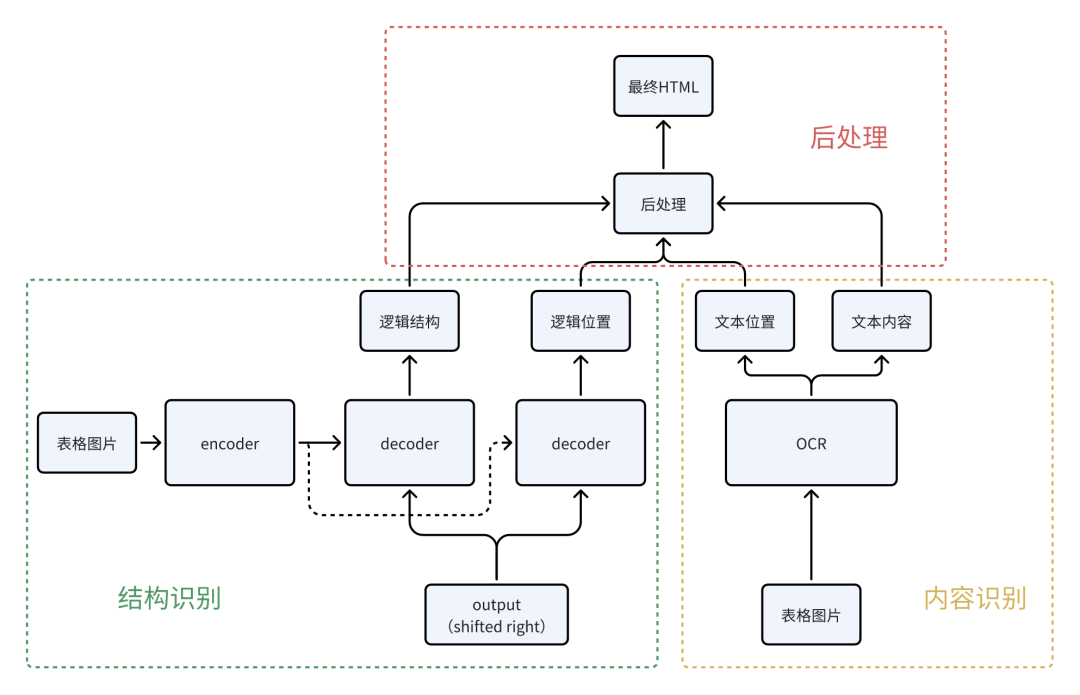
表格解析模型通常采用分而治之的策略,即将表格结构识别与内容识别分离。这种设计降低了单一模型的复杂度,便于优化,提高了识别的准确性。
1️⃣表格结构识别同时考虑逻辑结构和物理结构:
-
逻辑结构关注单元格之间的层级和关联关系,如行列结构、表头关系等;
-
物理结构聚焦表格的视觉布局,如单元格的位置、大小和边框信息等。
2️⃣表格内容识别主要负责文字提取:
-
文字识别使用OCR技术识别单元格内的文本内容;
-
内容框定位每个文字块的位置,为后续与单元格匹配提供依据。
3️⃣后处理是关键的最后一步:
-
通过物理结构和内容框的匹配,将识别出的文字精准嵌入到逻辑结构中,形成完整的表格解析结果。这一步骤需要精细的对齐算法和错误纠正机制。
训练策略
-
数据增强:是提升模型泛化能力的重要手段,包括旋转、缩放、模糊、噪声注入等图像增强技术,以及表格结构和内容的语义增强。
-
两阶段训练方式:
⚒️预训练阶段:使用大规模开源数据集(如PubTabNet),让模型初步掌握表格的基本特征和结构规律。这一阶段的数据量较大但质量不一,目标是建立基础解析能力;
⚒️后训练阶段:使用高质量、高难度的业务数据(如特定行业的复杂报表),精细调整模型参数,提升其在特定场景下的解析精度。这个阶段数据量较少但质量更高,标注更精确。
小结
表格解析的技术链条较长,从数据准备到模型训练,每个环节都需要精心设计和优化。数据质量是基础,决定了模型性能的上限;模型设计是关键,影响着解析的准确性和效率;训练策略是保障,确保了模型的泛化和实用能力。
未来,随着大语言模型在表格理解方面的进步,以及多模态技术的融合发展,表格解析技术将更加统一、智能和鲁棒,为各行各业的数字化转型提供更强支撑。我们需要持续优化数据质量、改进模型架构、探索更有效的训练范式,让机器真正理解并善用表格中蕴含的宝贵信息。
更多技术讨论,欢迎移步“万象开发者”gzh!

















 22万+
22万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









