







 博客介绍了两种信息技术相关操作,一是使用matplotlib.pyplot,二是使用PIL Image里的blend函数,并都展示了效果图。
博客介绍了两种信息技术相关操作,一是使用matplotlib.pyplot,二是使用PIL Image里的blend函数,并都展示了效果图。
一 使用matplotlib.pyplot
# 将分割图和原图合在一起
from PIL import Image
import matplotlib.pyplot as plt
#image1 原图
#image2 分割图
image1 = Image.open("1.jpg")
image2 = Image.open("1.png")
plt.figure()
plt.subplot(221)
plt.imshow(image1)
plt.subplot(222)
plt.imshow(image2)
plt.subplot(223)
plt.imshow(image1)
plt.imshow(image2,alpha=0.5)
plt.show()
效果图:
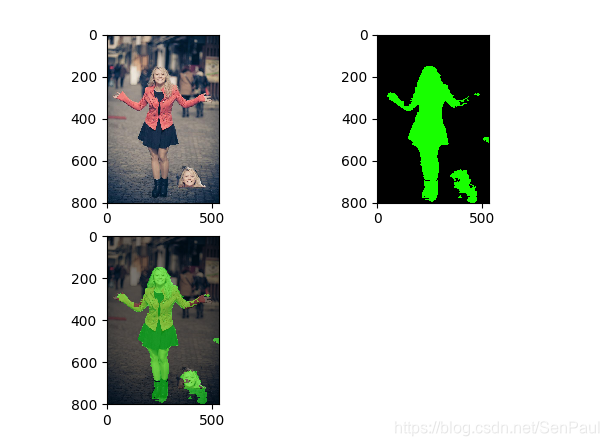
二 使用 PIL Image 里面的blend函数
# 将分割图和原图合在一起
from PIL import Image
import matplotlib.pyplot as plt
#image1 原图
#image2 分割图
image1 = Image.open("1.jpg")
image2 = Image.open("1.png")
image1 = image1.convert('RGBA')
image2 = image2.convert('RGBA')
#两幅图像进行合并时,按公式:blended_img = img1 * (1 – alpha) + img2* alpha 进行
image = Image.blend(image1,image2,0.3)
image.save("test.png")
image.show()
效果图:


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









