




SelectDB 是由飞轮科技基于 Apache Doris 内核打造的现代化数据仓库,支持大规模实时数据上的极速查询分析。 通过实时、统一、弹性、开放的核心能力,能够为企业提供高性价比、简单易用、安全稳定、低成本的实时大数据分析支持。SelectDB 具备世界领先的实时分析能力,能够实现秒级的数据实时导入与同步,在宽表、复杂多表关联、高并发点查等不同场景下,提供超越一众国际知名的同类产品的优秀性能,多次登顶 ClickBench 全球数据库分析性能排行榜。
阿里云 DataWorks 是基于大数据引擎,为数据仓库、数据湖、湖仓一体等解决方案提供统一的全链路大数据开发治理平台。 用户可通过 DataWorks 进行海量数据的离线加工分析,并能完成数据的汇聚集成、开发、生产调度与运维、离线与实时分析、数据质量治理与资产管理、安全审计、数据共享与服务、机器学习、应用搭建等工作。让数据从采集到展现、从分析到驱动应用得以解决,实现数据业务化、业务数据化。
近日,阿里云 DataWorks 正式支持 MySQL 整库实时同步至 SelectDB 或 Apache Doris。

详情参考:DataWorks 官方产品公告
当用户面临 MySQL 源库数据量大、查询分析速度慢的问题时,可以通过 DataWorks 将单表或整库同步至 SelectDB 或 Apache Doris,该方案便捷易用、成本低、数据同步延迟可达秒级,源库 MySQL 的数据变化(包括 DML、DDL 记录)都能实时同步。** 目前,DataWorks 对 SelectDB 和 Apache Doris 数据源的支持情况如下表所示,** 用户可通过 DataWorks 配置数据源,连接源库 MySQL 和目标库 SelectDB 或 Apache Doris ,利用 DataWorks 资源组实现 MySQL 单表或整库的全量和增量数据实时同步至 SelectDB 或 Apache Doris。

本文将以 SelectDB Cloud 为例, 为您全面介绍同步流程与步骤,助您快速使用 DataWorks 将 MySQL 整库数据同步至 SelectDB (由于 SelectDB 基于 Apache Doris 内核打造,两者在使用以及同步任务配置上几乎无差异,因此您也可以参考此方法将数据同步至 Apache Doris),轻松实现事务数据的实时同步与分析。
准备环境
准备数据库
本文将以阿里云数据库 RDS MySQL 版实例作为源端数据库。若您尚未创建,请点击如何创建阿里云数据库 RDS MySQL 实例参考完成具体设置。
本文将以 SelectDB Cloud 数据仓库作为目标端数据库,若您尚未创建,请点击如何创建 SelectDB Cloud 数仓参考完成具体设置。
准备 DataWorks 工作空间
您需要准备阿里云 DataWorks 空间以完成后续步骤,若您尚未创建,请点击如何创建阿里云 DataWorks 工作空间参考完成具体设置。
准备资源组
在使用 DataWorks 前,您需要新建 Serverless 资源组,为 MySQL 整库实时同步至 SelectDB Cloud 提供计算资源以及周期调度资源。若您已创建 Serverless 资源组,或拥有独享数据集成资源组,即可跳过准备资源组环节。
-
登录 DataWorks 控制台,切换至目标地域后,单击左侧导航栏的资源组,进入资源组列表页面。
-
在资源组列表页面,单击左上角的新建资源组,新建 Serverless 通用型资源组,具体步骤请点击如何新建阿里云 DataWorks Serverless 资源组完成创建。
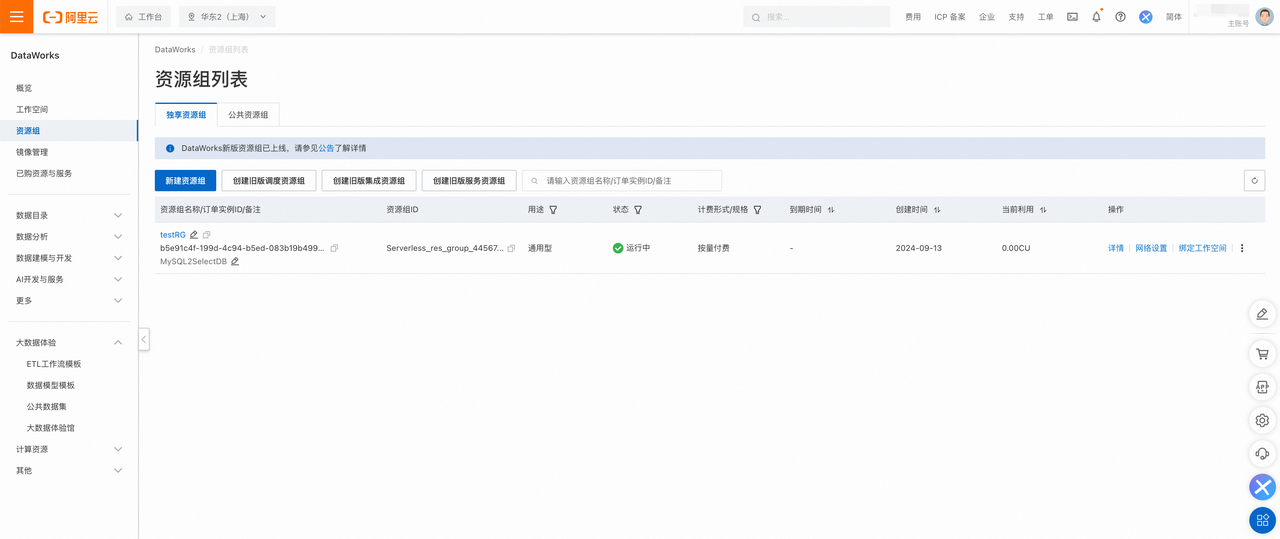
3.资源组创建完成后,您需要返回资源组列表页面,找到创建完毕的资源组,单击操作列内的绑定工作空间按钮,将新建的资源组与已有的 DataWorks 工作空间进行绑定。
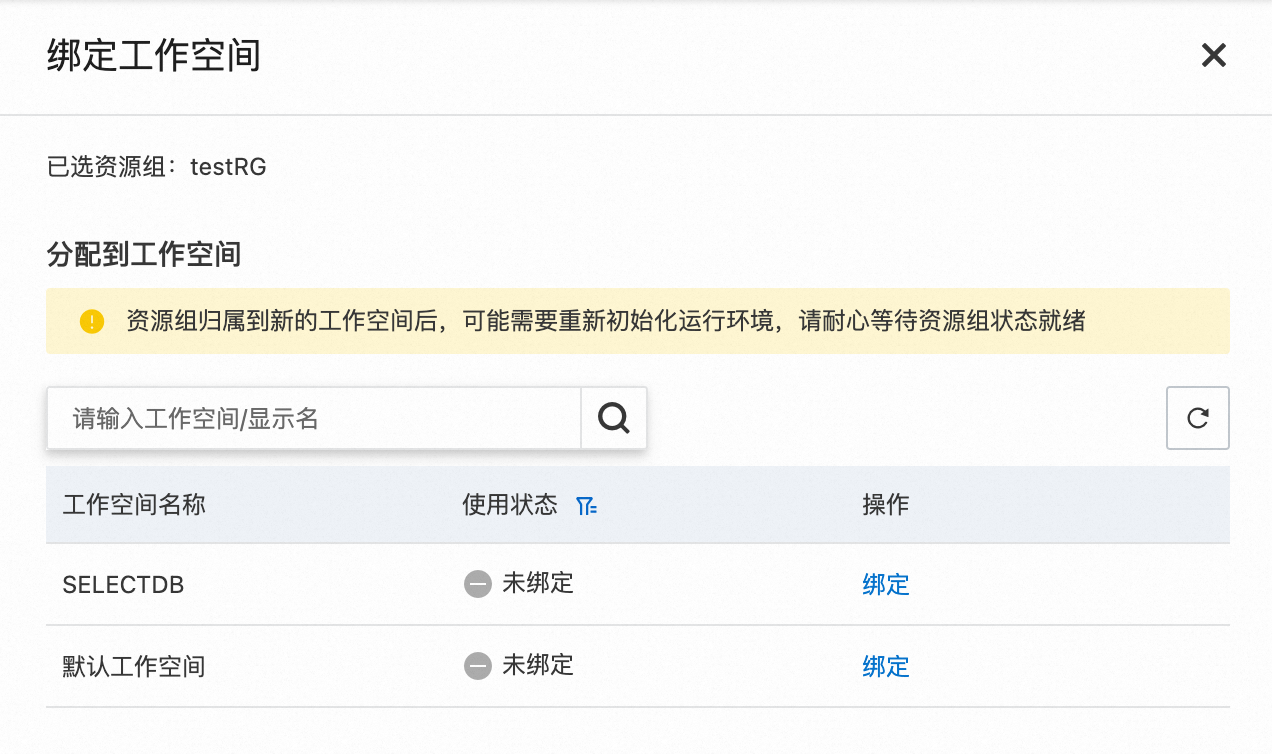
提醒 对于数据源存在白名单访问控制的情况,您需要将 Serverless 资源组绑定的交换机网段或者绑定 VPC 配置的 EIP 添加至其白名单中。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











