






🥂(❁´◡`❁)您的点赞👍➕评论📝➕收藏⭐➕关注👀是作者创作的最大动力🤞
💖📕🎉🔥 支持我:点赞👍+收藏⭐️+留言📝+关注👀欢迎留言讨论
🔥🔥🔥(源码获取 + 调试运行 + 问题答疑)🔥🔥🔥 有兴趣可以联系我
🔥🔥🔥 文末有往期免费源码,直接领取获取(无删减,无套路)
我们常常在当下感到时间慢,觉得未来遥远,但一旦回头看,时间已经悄然流逝。对于未来,尽管如此,也应该保持一种从容的态度,相信未来仍有许多可能性等待着我们。
🔥🔥🔥(免费,无删减,无套路):java swing管理系统源码 程序 代码 图形界面(11套)」
链接:https://pan.quark.cn/s/784a0d377810
提取码:见文章末尾
🔥🔥🔥(免费,无删减,无套路): Python源代码+开发文档说明(23套)」
链接:https://pan.quark.cn/s/1d351abbd11c
提取码:见文章末尾
🔥🔥🔥(免费,无删减,无套路):计算机专业精选源码+论文(26套)」
链接:https://pan.quark.cn/s/8682a41d0097
提取码:见文章末尾
🔥🔥🔥(免费,无删减,无套路):Java web项目源码整合开发ssm(30套)
链接:https://pan.quark.cn/s/1c6e0826cbfd
提取码:见文章末尾
🔥🔥🔥(免费,无删减,无套路):「在线考试系统源码(含搭建教程)」
链接:https://pan.quark.cn/s/96c4f00fdb43
提取码:见文章末尾
ForkJoinTask源码深度解析:RecursiveTask与RecursiveAction的设计哲学
-
《深入ForkJoinTask源码:剖析fork()、join()和compute()的协作机制》
-
《RecursiveTask vs RecursiveAction:如何选择正确的Fork/Join任务类型》
-
《Java并行编程精髓:ForkJoinTask核心方法源码深度解读》
-
《从源码看设计:ForkJoinTask如何优雅地处理任务分解与结果合并》
-
《fork()、join()、invoke()的微妙区别:掌握Fork/Join框架的正确用法》
引言:并行任务的抽象基石
在Java并发编程的世界中,ForkJoinTask扮演着承上启下的关键角色。作为Fork/Join框架中所有任务的抽象基类,它定义了并行任务的基本行为规范。理解ForkJoinTask的设计,不仅有助于我们编写高效的并行代码,更能让我们深入理解现代并行计算框架的设计思想。
今天,我们将深入ForkJoinTask的源码,剖析其核心方法的工作原理,并对比分析它的两个直接子类:RecursiveTask(有返回值)和RecursiveAction(无返回值)。通过这次源码之旅,你将彻底理解fork()、join()、invoke()这些看似简单的方法背后复杂的协作机制。
ForkJoinTask:抽象但功能完整的任务基类
核心状态机设计
在深入具体方法之前,我们先要理解ForkJoinTask的核心设计哲学。每个ForkJoinTask实例都维护着一个状态变量,这个状态机控制了任务的整个生命周期:
状态位(低16位):
- DONE_MASK : 任务完成标志
- NORMAL : 正常完成
- CANCELLED : 被取消
- EXCEPTIONAL : 异常完成
- SIGNAL : 等待信号这种状态机设计使得任务可以高效地表达复杂的执行状态,同时支持轻量级的通知机制。状态位的操作都使用原子操作,保证了线程安全。
fork()方法:异步执行的启动器
fork()方法是任务并行化的起点。让我们深入它的源码实现:
public final ForkJoinTask<V> fork() {
Thread t;
if ((t = Thread.currentThread()) instanceof ForkJoinWorkerThread)
((ForkJoinWorkerThread)t).workQueue.push(this);
else
ForkJoinPool.common.externalPush(this);
return this;
}关键洞察:
-
智能线程检测:fork()方法首先检查当前线程是否是ForkJoinWorkerThread。这是典型的"线程感知"设计——框架知道谁在执行它。
-
双路径执行:
-
如果是工作线程:将任务推入该线程自己的工作队列(双端队列的头部)
-
如果是外部线程:使用common池的externalPush方法
-
-
设计哲学:这种设计确保了框架在不同使用场景下的灵活性
fork()的返回值是任务本身,这支持了方法链式调用:left.fork().right.fork()。
join()方法:结果的同步等待
join()方法是fork()的对称操作,用于等待任务完成并获取结果:
public final V join() {
int s;
if ((s = doJoin() & DONE_MASK) != NORMAL)
reportException(s);
return getRawResult();
}关键实现细节:
-
doJoin()的核心逻辑:
-
检查任务状态,如果已完成则直接返回
-
如果任务在等待队列中,尝试帮助完成它(工作窃取的体现)
-
否则,阻塞等待直到任务完成
-
-
异常处理机制:通过reportException()方法统一处理取消和异常情况
-
阻塞优化:使用
Thread.yield()和自旋等待,避免昂贵的线程切换
join()方法的巧妙之处在于它不仅仅是简单的等待——在工作线程中,它可能会"帮助"执行等待的任务,这体现了工作窃取的思想。
invoke()方法:同步执行的快捷方式
invoke()方法提供了同步执行任务的便捷方式:
public final V invoke() {
int s;
if ((s = doInvoke() & DONE_MASK) != NORMAL)
reportException(s);
return getRawResult();
}invoke() vs fork()+join()的关键区别:
-
invoke()是同步的:当前线程直接执行任务 -
fork()+join()是异步的:任务可能在其他线程执行 -
在外部线程调用时,两者行为类似
-
在工作线程中,invoke()可能避免不必要的队列操作
RecursiveTask与RecursiveAction:面向用户的任务抽象
RecursiveTask:有返回值的递归任务
RecursiveTask用于需要返回结果的计算任务。它的核心抽象方法是compute():
protected abstract V compute();设计模式分析:
-
模板方法模式:ForkJoinTask定义了任务执行的整体框架,RecursiveTask的子类实现具体的计算逻辑
-
递归分解模式:在compute()方法中实现任务的分治策略
典型使用模式:
class SumTask extends RecursiveTask<Long> {
private final long[] array;
private final int start, end;
protected Long compute() {
if (任务足够小) {
return 直接计算();
} else {
int mid = (start + end) / 2;
SumTask left = new SumTask(array, start, mid);
SumTask right = new SumTask(array, mid, end);
left.fork(); // 异步执行左子任务
Long rightResult = right.compute(); // 同步执行右子任务
Long leftResult = left.join(); // 等待左子任务完成
return leftResult + rightResult;
}
}
}RecursiveAction:无返回值的递归任务
RecursiveAction适用于不需要返回结果的任务,比如数据转换、筛选等:
protected abstract void compute();使用场景对比:
-
RecursiveTask:需要聚合结果的场景,如求和、统计、搜索等
-
RecursiveAction:纯副作用操作,如数组排序、数据转换、批量更新等
compute()方法中的调度策略选择
fork()+join() vs invokeAll()
在compute()方法中,我们有多种调度子任务的方式:
方式一:经典的fork()+join()组合
left.fork();
rightResult = right.compute();
leftResult = left.join();这种模式的优点:
-
流水线优化:当前线程在等待left结果时,可以继续执行right
-
资源利用率高:充分利用了线程的计算能力
方式二:invokeAll()批量调用
invokeAll(left, right);
leftResult = left.join();
rightResult = right.join();invokeAll()的内部实现:
public static void invokeAll(ForkJoinTask<?>... tasks) {
// 将除了最后一个任务外的所有任务fork()
// 直接执行最后一个任务
// 然后join()所有任务
}invokeAll()的优势:
-
代码简洁:减少重复代码
-
异常传播:统一处理异常
-
优化执行:避免不必要的线程切换
直接invoke()的使用场景
在某些情况下,直接调用子任务的invoke()可能是更好的选择:
// 当子任务很小或已经是最后一级分解时
if (子任务足够小) {
result = 子任务.invoke(); // 直接同步执行
} else {
子任务.fork();
// ... 其他逻辑
}选择策略总结:
-
任务较大且可并行:使用fork()+join()或invokeAll()
-
任务很小或递归最后一级:考虑直接invoke()
-
需要精细控制执行顺序:使用显式的fork()和join()
-
批量处理多个子任务:使用invokeAll()
源码中的性能优化技巧
任务窃取的实现细节
深入ForkJoinTask源码,我们可以看到工作窃取的具体实现:
-
状态位操作:使用Unsafe类进行原子操作,避免锁开销
-
自旋等待:在join()等待时使用有限次数的自旋,减少上下文切换
-
队列操作优化:使用双端队列减少竞争
内存布局与伪共享避免
现代ForkJoinTask实现考虑了CPU缓存行的影响:
-
频繁访问的字段被分组在一起
-
使用填充避免伪共享
-
状态变量单独对齐
实战:设计高性能的RecursiveTask
阈值选择的科学
阈值的合理选择是RecursiveTask性能的关键:
// 动态阈值计算
private static final int THRESHOLD =
Runtime.getRuntime().availableProcessors() > 1 ?
1000 : 10000; // 单核时使用更大的阈值阈值选择考虑因素:
-
任务计算密度:每个元素的计算成本
-
数据局部性:缓存友好的数据访问模式
-
递归深度:避免过深的递归调用栈
结果合并的优化
对于复杂的聚合操作,结果合并可能成为性能瓶颈:
// 优化前:每次创建新对象
protected Long compute() {
return leftResult + rightResult; // 创建新的Long对象
}
// 优化后:使用可变结果
protected Result compute() {
Result result = new MutableResult();
// ... 计算逻辑
return result.merge(leftResult, rightResult);
}错误处理与调试技巧
异常处理机制
ForkJoinTask提供了完善的异常处理:
try {
result = task.join();
} catch (CancellationException e) {
// 任务被取消
} catch (ExecutionException e) {
// 任务执行异常
Throwable cause = e.getCause();
}调试与监控
-
任务状态检查:
task.isDone() // 是否完成 task.isCancelled() // 是否被取消 task.isCompletedNormally() // 是否正常完成 -
性能监控:
-
使用JMX监控ForkJoinPool状态
-
记录任务分解深度和执行时间
-
分析工作窃取的频率
-
最佳实践总结
通过深入分析ForkJoinTask的源码,我们可以总结出以下最佳实践:
-
任务粒度控制:
-
每个任务至少执行1000-5000个CPU周期
-
避免创建过多的小任务
-
-
调度策略选择:
-
对于计算密集的任务,使用fork()+join()
-
对于I/O混合的任务,考虑其他并发模型
-
-
资源管理:
-
合理设置线程池大小(通常等于CPU核心数)
-
监控任务队列深度,避免内存溢出
-
-
代码组织:
-
保持compute()方法简洁
-
将任务分解逻辑与业务逻辑分离
-
思考与展望
ForkJoinTask的设计展示了几个重要的软件工程原则:
-
关注点分离:任务定义与任务执行分离
-
策略模式:支持不同的任务分解策略
-
模板方法:固定算法骨架,灵活变化实现
随着硬件的发展(更多核心、异构计算),ForkJoinTask可能会进一步演化:
-
支持GPU计算任务
-
更智能的任务粒度调整
-
能耗感知的任务调度
结语:从源码中学习设计智慧
深入ForkJoinTask源码不仅让我们理解了如何正确使用Fork/Join框架,更重要的是,它展示了优秀并发库的设计原则:
-
简单性与复杂性的平衡:对外提供简单的API,内部处理复杂的并发问题
-
性能与可读性的权衡:在关键路径上优化性能,同时保持代码的可维护性
-
通用性与特殊性的结合:既支持通用的任务模型,又提供专门化的子类
正如计算机科学家Alan Kay所说:"Simple things should be simple, complex things should be possible." ForkJoinTask的设计完美体现了这一理念——它让简单的并行任务变得简单,同时让复杂的并行算法成为可能。
掌握ForkJoinTask不仅是为了编写更快的代码,更是为了理解现代并行计算的思想。在日益并行的计算世界中,这种理解将成为每个开发者的宝贵财富。
图1:ForkJoinTask状态机
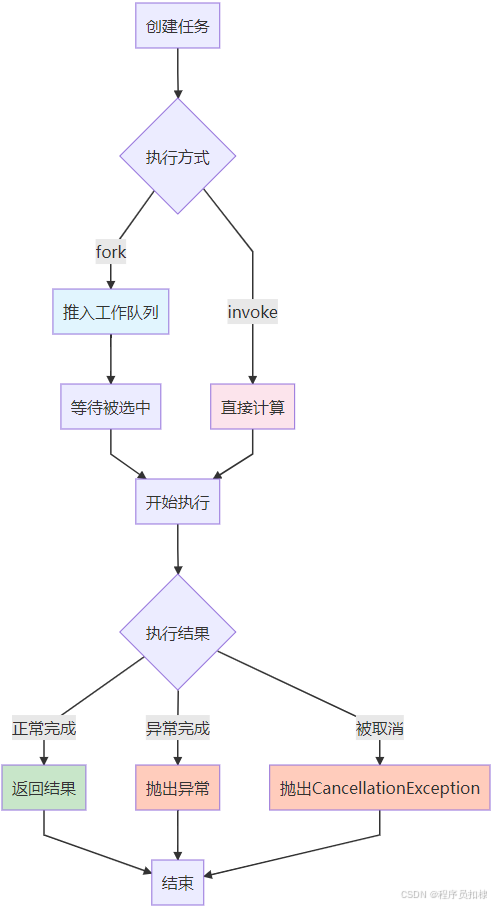
图2:fork()与join()协作流程
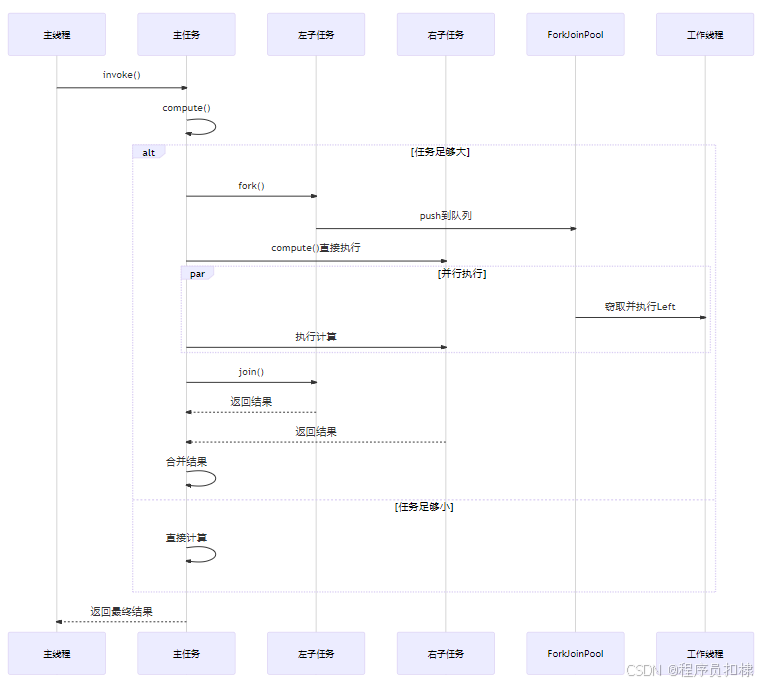
图3:RecursiveTask与RecursiveAction类结构
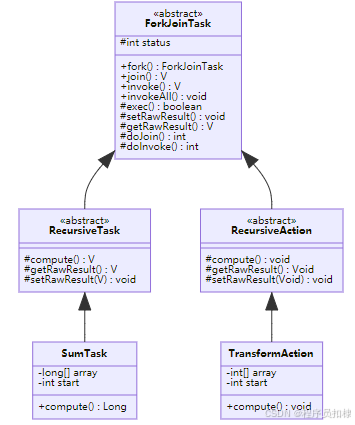
图4:任务调度策略对比
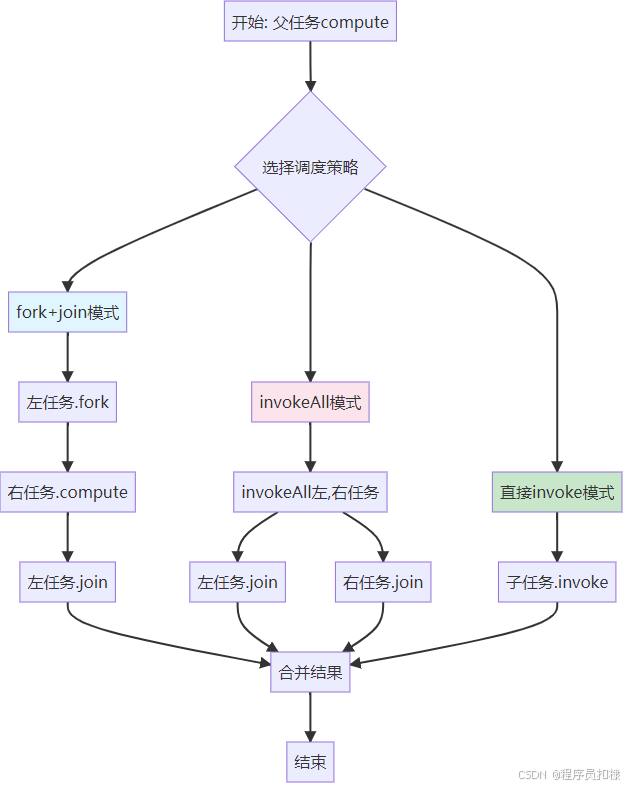
往期免费源码对应视频:
免费获取--SpringBoot+Vue宠物商城网站系统
🥂(❁´◡`❁)您的点赞👍➕评论📝➕收藏⭐➕关注👀是作者创作的最大动力🤞
💖📕🎉🔥 支持我:点赞👍+收藏⭐️+留言📝+关注👀欢迎留言讨论
🔥🔥🔥(源码 + 调试运行 + 问题答疑)
🔥🔥🔥 有兴趣可以联系我
💖学习知识需费心,
📕整理归纳更费神。
🎉源码免费人人喜,
🔥码农福利等你领!💖常来我家多看看,
📕网址:扣棣编程,
🎉感谢支持常陪伴,
🔥点赞关注别忘记!💖山高路远坑又深,
📕大军纵横任驰奔,
🎉谁敢横刀立马行?
🔥唯有点赞+关注成!
⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇点击此处获取源码⬇⬇⬇⬇⬇⬇⬇⬇⬇

















 186
186

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









