







习题
9-1 完整的优势演员-评论员算法的工作流程是怎样的?
如果采用Q网络和V网络,估测不准的风险会变成两倍。所以我们在进行实现的时候只估测网络V。可以用V的值来表示Q的值,
Q
π
(
s
t
n
,
a
t
n
)
=
E
[
r
t
n
+
V
π
(
s
t
+
1
n
)
]
Q^\pi(s^n_t, a^n_t)=E[r^n_t + V^\pi(s^n_{t+1})]
Qπ(stn,atn)=E[rtn+Vπ(st+1n)],去掉期望即,
Q
π
(
s
t
n
,
a
t
n
)
=
r
t
n
+
V
π
(
s
t
+
1
n
)
Q^\pi(s^n_t, a^n_t)=r^n_t + V^\pi(s^n_{t+1})
Qπ(stn,atn)=rtn+Vπ(st+1n)。然后我们再将Q用r+V替代:
Q
π
(
s
t
,
a
t
)
=
r
t
+
γ
m
a
x
[
Q
π
(
s
t
+
1
,
a
t
+
1
)
]
Q^\pi (s_t, a_t)=r_t+\gamma max[Q^\pi(s_{t+1}, a_{t+1})]
Qπ(st,at)=rt+γmax[Qπ(st+1,at+1)]
r
t
n
+
V
π
(
s
t
+
1
n
)
=
r
t
n
+
γ
(
r
t
+
1
n
+
V
π
(
s
t
+
2
n
)
)
r^n_t + V^\pi(s^n_{t+1})=r^n_t+\gamma (r^n_{t+1} + V^\pi(s^n_{t+2}))
rtn+Vπ(st+1n)=rtn+γ(rt+1n+Vπ(st+2n))
将t均-1, 去掉
γ
\gamma
γ:
V
π
(
s
t
n
)
=
(
r
t
n
+
V
π
(
s
t
+
1
n
)
)
V^\pi(s^n_{t})=(r^n_{t} + V^\pi(s^n_{t+1}))
Vπ(stn)=(rtn+Vπ(st+1n))
我们最终的目的是最小化下式,即优势函数:
Δ
=
r
t
n
+
V
π
(
s
t
+
1
n
)
−
V
π
(
s
t
n
)
\Delta = r^n_{t} + V^\pi(s^n_{t+1}) -V^\pi(s^n_{t})
Δ=rtn+Vπ(st+1n)−Vπ(stn)
所以整个流程就是这样(和DQN基本差不多):
1.初始的演员去和环境交互,收集到buffer中
2. 从buffer中抽样,然后去估计价值函数(monta carlo或者TD的方法)
3. 更新演员
4. 重复2 3,到收敛。
9-2 在实现演员-评论员算法的时候有哪些技巧?
-
需要两个有共享层的网络:
- V函数网络和Actor网络。V输入一个状态,输出一个标量;Actor输入一个状态,输出一个动作分布,或者是一个连续的向量。
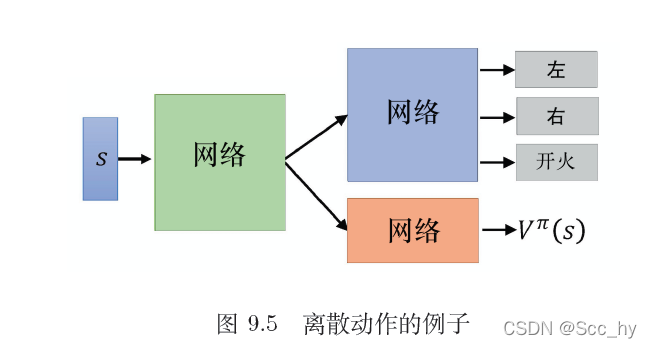
- V函数网络和Actor网络。V输入一个状态,输出一个标量;Actor输入一个状态,输出一个动作分布,或者是一个连续的向量。
-
探索机制
- 对 π \pi π的输出的分布下一个约束。这个约束是希望分布的熵不要太小,及希望不同动作被采样的概率平均一些。这样在测试的时候,它才会多尝试各种不同的动作,才会把这个环境探索的比较充分,以得到比较好的结果。
9-3 异步优势演员-评论员算法在训练时会有很多进程进行异步的工作,最后再将他们所获得的"结果"再集合到一起。那么其具体的如何运作的呢?
在每个进程工作前都会全局网络的参数复制过来。每个Actor都是平行进行的,当进行结束后,再进行梯度计算,计算完之后,再把参数传回去。然后,逐步对不同Actor传回的梯度进行参数更新。
9-4 对比经典的Q学习算法,路径衍生策略梯度有哪些改进之处?
- 原先输入状态 s t s_t st,后续采用哪个动作 a t + 1 a_{t+1} at+1,是由 Q ( s t , a t ) Q(s_t, a_t) Q(st,at)决定,变成直接由 π \pi π决定
- 原先需要用 m a x [ Q π ( s t + 1 , a i ) ] max[Q^\pi(s_{t+1}, a_i)] max[Qπ(st+1,ai)]来获取最大价值,现在只需要 π ( s t + 1 ) \pi(s_{t+1}) π(st+1)就可以
- 之前只要学习Q函数,现在需要多学习一个策略 π \pi π,其目的在于最大化Q函数,希望得到的演员可以让Q函数的输出尽可能地大,这个跟生成对抗网络(GAN)里面的生成器的概念是类似的。
- 与原来的Q函数不一样。我们要把目标的Q网络取代掉,你现在也要把目标网络策略取代掉。


















 8220
8220

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











