







很多时候我们输出的特征重要性gain值和cover值不一致,会导致些许困惑(到底那个特征最为重要,那个特征重要性要靠前)。所以,我们考虑用shapely value 来衡量特征的重要性,它即考虑了特征的cover,同时也考虑了gain值,且输出结果更加的符合业务直觉。
在XGB中预测接口同样配置了样本shap值的输出选项(xgb_model.predict(te_mt, pred_contribs=True))。因此本文主要简单梳理下树模型的Shap value值计算
一、Shapely Value
shapely value 衡量一方在博弈中的总贡献,可以简单看下以下计算(枚举所有可能,然后计算加入一方的时候对总体的贡献度影响,再基于权重累加)。
𝑦
𝑖
=
𝑦
𝑏
𝑎
𝑠
𝑒
+
𝑓
(
𝑥
𝑖
1
)
+
𝑓
(
𝑥
𝑖
2
)
+
.
.
.
+
𝑓
(
𝑥
𝑖
𝑘
)
𝑦_𝑖=𝑦_{𝑏𝑎𝑠𝑒}+𝑓(𝑥_𝑖^1)+𝑓(𝑥_𝑖^2)+...+𝑓(𝑥_𝑖^𝑘)
yi=ybase+f(xi1)+f(xi2)+...+f(xik)
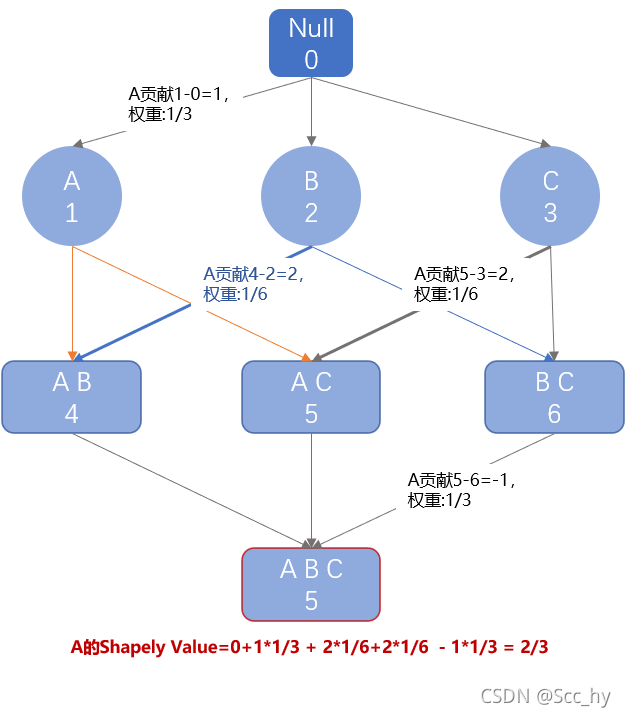
二、树模型的Shapley Value计算简化
由于枚举全部可能,在大数据情况下,百维的特征是十分常见的,必然其效率十分低。所以,就有了基于已有树模型去优化、简化计算shapely value的方法。
def get_data():
iris = load_iris()
df = pd.DataFrame(iris.data, columns='a b c d'.split(' '))
df['y'] = iris.target
return train_test_split(df.iloc[:, :-1].values, df.iloc[:, -1].values, test_size=0.2, random_state=42)
xgb_params = {
'objective' : 'reg:squarederror',
'gamma' : 1,
'min_split_loss': 0,
'max_depth': 1,
'reg_lambda': 0.01,
'learning_rate':1
}
tr_x, te_x, tr_y, te_y = get_data()
tr_mt = xgb.DMatrix(tr_x, label=tr_y)
te_mt = xgb.DMatrix(te_x, label=te_y)
xgb_model = xgb.train(xgb_params, tr_mt, num_boost_round=3)
te_p_xgb = xgb_model.predict(te_mt)
2.1 shapely value 的 base value
b a s e _ v a l u e = E ( f ( z ) ) base\_value = E(f(z)) base_value=E(f(z)) 是训练集的预测值的均值.
shap_te.base_values[0], np.mean(xgb_model.predict(tr_mt))
shap_base = np.mean(xgb_model.predict(tr_mt))
"""
>>> shap_te.base_values[0], np.mean(xgb_model.predict(tr_mt))
(0.99165833, 0.99165833)
"""
2.2 一个样本的特征贡献度计算
因为是基于树结果进行计算特征贡献度,所有我们需要先查看生成的树的情况。
xgb_tree = xgb_model.trees_to_dataframe()
print(xgb_tree)
"""
Tree Node ID Feature Split Yes No Missing Gain Cover
0 0 0 0-0 f2 2.45 0-1 0-2 0-1 58.994327 120.0
1 0 1 0-1 Leaf NaN NaN NaN NaN -0.499875 40.0
2 0 2 0-2 Leaf NaN NaN NaN NaN 0.987377 80.0
3 1 0 1-0 f3 1.75 1-1 1-2 1-1 11.572807 120.0
4 1 1 1-1 Leaf NaN NaN NaN NaN -0.199235 85.0
5 1 2 1-2 Leaf NaN NaN NaN NaN 0.483914 35.0
6 2 0 2-0 f2 2.45 2-1 2-2 2-1 2.377620 120.0
7 2 1 2-1 Leaf NaN NaN NaN NaN 0.199060 40.0
8 2 2 2-2 Leaf NaN NaN NaN NaN -0.099507 80.0
"""
F2 贡献度 fx(s U f2) - fx(s)
样本:array([6.1, 2.8, 4.7, 1.2])
no节点权重:frac = 80/120; yes节点权重:1-frac (查看输出树的1 2 7 8行)
f2_con = (
# 加入样本的Tree 0 的预测结果 (4.7 < 2.45 => no => 0-2 => 0.987377)
0.987377
# 未加入样本的Tree 0 的平均预测结果
- (0.987377 * frac + -0.499875 * (1-frac))
# 加入样本的Tree 2 的预测结果 (4.7 < 2.45 => no => 2-2 => -0.099507)
-0.099507
# 未加入样本的Tree 2 的平均预测结果
-(-0.099507*frac + 0.199060*(1-frac))
)
f3 贡献度 fx(s U f2) - fx(s)
yes节点权重:frac_3 = 85/120; no节点权重:1-frac (查看输出树的4 5行)
f3_con = (
# 加入样本的Tree 1 的预测结果 (1.2 < 1.75 => yes => 1-1 => -0.199235 )
-0.199235
# 未加入样本的Tree 1 的平均预测结果
-(-0.199235*frac_3 + 0.483914*(1-frac_3))
)
结果比对
与SHAP包中的计算结果,以及xgb预测输出比对
x1_contribution = xgb_model.predict(te_mt, pred_interactions=True)[0].sum(axis=1)
x1_contribution[2:], shap_te.values[0][2:], (f2_con, f3_con, shap_base)
"""
>>> x1_contribution[2:], shap_te.values[0][2:], (f2_con, f3_con, shap_base)
(array([ 0.39622822, -0.19925164, 0.99165833], dtype=float32),
array([ 0.39622822, -0.19925164], dtype=float32),
(0.3962283333333333, -0.19925179166666665, 0.99165833))
"""
三、预测
Shap value预测与叶子节点的预测
Shap value预测就是shap基础值与所有特征的贡献之和,即之前提到的公式:
𝑦
𝑖
=
𝑦
𝑏
𝑎
𝑠
𝑒
+
𝑓
(
𝑥
𝑖
1
)
+
𝑓
(
𝑥
𝑖
2
)
+
.
.
.
+
𝑓
(
𝑥
𝑖
𝑘
)
𝑦_𝑖=𝑦_{𝑏𝑎𝑠𝑒}+𝑓(𝑥_𝑖^1)+𝑓(𝑥_𝑖^2)+...+𝑓(𝑥_𝑖^𝑘)
yi=ybase+f(xi1)+f(xi2)+...+f(xik)
所以预测结果是 y i = f 2 _ c o n + f 3 _ c o n + s h a p _ b a s e yi = f2\_con + f3\_con + shap\_base yi=f2_con+f3_con+shap_base
f2_con + f3_con + shap_base, x1_contribution.sum(), xgb_model.predict(te_mt)[0]
"""
(1.1886348716303508, 1.1886349, 1.188635)
"""
叶子节点的预测,与损失函数相关, 当前使用的是回归mse,所以可以从预测基础值与预测节点累加:
y
i
=
0.5
+
0.987377
+
−
0.099507
−
0.199235
yi =0.5 + 0.987377 + -0.099507 -0.199235
yi=0.5+0.987377+−0.099507−0.199235
xgb源码中的预测基础值默认为0.5。
笔者猜测:预测基础值是假设y是服从(0, 1)正态分布的。然后可以基于损失函数进行简单推导:
m
s
e
=
1
2
(
y
−
y
^
)
2
;
g
=
y
^
−
y
;
h
=
1
mse= \frac{1}{2}(y - \hat{y})^2;\ \ g=\hat{y}-y;\ \ h=1
mse=21(y−y^)2; g=y^−y; h=1
L
o
s
s
=
m
s
e
+
g
1
!
y
^
+
h
2
!
y
^
+
γ
∗
T
+
λ
2
y
^
Loss=mse+\frac{g}{1!} \hat{y}+\frac{h}{2!} \hat{y}+ \gamma*T + \frac{\lambda}{2} \hat{y}
Loss=mse+1!gy^+2!hy^+γ∗T+2λy^
令
λ
=
0
:
\lambda=0:
λ=0:
L
o
s
s
=
1
2
(
y
−
y
^
)
2
+
(
y
^
−
y
)
y
^
+
1
2
y
^
2
+
γ
∗
T
=
(
1
2
y
2
−
y
y
^
+
1
2
y
^
2
)
+
(
y
^
2
−
y
y
^
)
+
1
2
y
^
2
+
γ
∗
T
=
2
y
^
2
−
2
y
y
^
+
(
0.5
y
2
+
γ
∗
T
)
Loss=\frac{1}{2}(y - \hat{y})^2+(\hat{y}-y) \hat{y}+\frac{1}{2} \hat{y}^2+ \gamma*T\\ =(\frac{1}{2}y^2 - y\hat{y}+\frac{1}{2}\hat{y}^2)+(\hat{y}^2- y\hat{y})+\frac{1}{2} \hat{y}^2+ \gamma*T\\ =2\hat{y}^2-2y\hat{y} + (0.5y^2+ \gamma*T)
Loss=21(y−y^)2+(y^−y)y^+21y^2+γ∗T=(21y2−yy^+21y^2)+(y^2−yy^)+21y^2+γ∗T=2y^2−2yy^+(0.5y2+γ∗T)
由二次项式顶点公式
x
=
−
b
2
a
=
>
y
^
=
2
y
4
=
y
2
x=\frac{-b}{2a} \ => \ \hat{y}=\frac{2y}{4}=\frac{y}{2}
x=2a−b => y^=42y=2y
由于y是服从(0, 1)正态分布的,所以E(y)=1;
h
a
t
y
=
1
/
2
=
0.5
hat{y}=1/2=0.5
haty=1/2=0.5


















 2371
2371

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











