



在商业、经济、气象、医疗等众多领域,我们每天都在与按时间顺序排列的数据点——即时间序列数据——打交道。从每月的销售额、每日的网站UV,到每年的GDP增长率,这些数据背后隐藏着关于趋势、周期和未来的秘密。时间序列分析,正是我们解读这些秘密、做出科学预测的利器。
然而,时间序列分析并非简单的“画图-拟合-预测”,它是一套严谨的科学流程。一个完整的、规范的时间序列分析项目,其核心流程可以概括为以下六个环环相扣的阶段:

上图清晰地展示了时间序列建模预测的完整闭环。它始于明确的分析目标与干净的数据,核心在于通过一系列处理与检验将非平稳序列转化为平稳序列,并构建出最优的统计模型,最终用于可靠的预测。这是一个迭代优化、直至模型满意的科学过程。
本文将遵循这一流程,深入剖析每个步骤的要点、常用方法及背后的逻辑,助你系统掌握时间序列分析的精髓。
一、 基石:分析目标界定与数据准备
1. 明确分析目标
在导入数据之前,必须回答:本次分析的终极目的是什么?是描述历史规律(如季节性波动),还是进行短期预测,或是探测结构性突变?目标决定了后续方法的选择与模型的复杂程度。
2. 数据收集与质量核查
确保数据在时间上是连续的,频率(日、月、年)是一致的。重点检查:
- 缺失值:对于少量缺失,可采用插值法(如线性插值、季节调整后插值)填补。
- 异常值:识别并判断异常值的性质。是记录错误(需修正),还是真实的极端事件(需保留或单独处理)?
在这一步,利用SPSSAU的【数据处理】功能,可以快速完成缺失值、异常值的识别与处理,为后续分析奠定坚实的数据基础。操作示例如下:
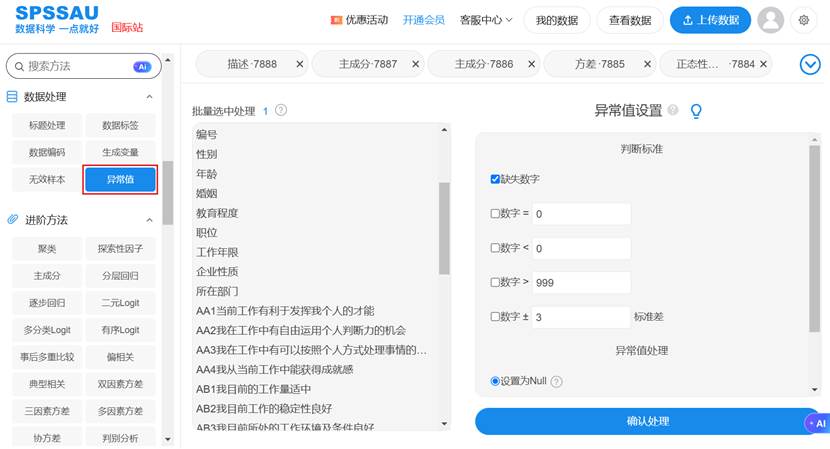
二、 灵魂:序列平稳化处理
平稳性是时间序列分析的基石。一个平稳序列的统计特性(如均值、方差)不随时间推移而变化。绝大多数经典时间序列模型(如ARIMA)都要求序列是平稳的。
1. 为何要平稳?
使用非平稳序列进行回归,极易产生“伪回归”问题,即模型显示变量间有显著关系,但这只是源于它们共同的时间趋势,而非真实关联。
2. 如何实现平稳?
平稳化处理是一个关键步骤,其具体路径如下:
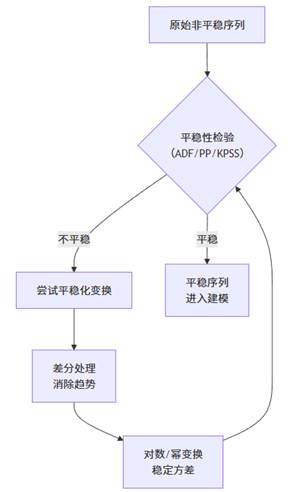
- 差分:是最常用、最有效的消除确定性趋势和季节性的方法。一阶差分可消除线性趋势,二阶差分可消除曲线趋势,季节差分可消除季节性。
- 变换:若序列方差随时间增大(异方差),可先进行对数变换或Box-Cox变换,以稳定方差。
3. 如何检验平稳性?
- 单位根检验:如ADF检验、PP检验。原假设为“序列存在单位根(非平稳)”。若p值<0.05,则拒绝原假设,认为序列平稳。
- 看图判断:绘制序列图,观察其是否围绕恒定均值波动,且波动幅度恒定。
在SPSSAU的【计量经济研究】模块中,提供了一键式的【ADF检验】功能,并直接给出ADF检验统计量与p值,同时输出差分后的序列图,让平稳性判断变得直观而高效。
三、 核心:模型识别与常用分析方法论
当一个序列被验证为平稳后,我们就可以为其匹配最合适的时间序列模型。以下是几种最经典和常用的分析方法:
1. 描述性分析方法
这是分析的起点,主要通过绘图实现:
- 时序图:观察整体趋势、季节性波动、异常点和方差稳定性。
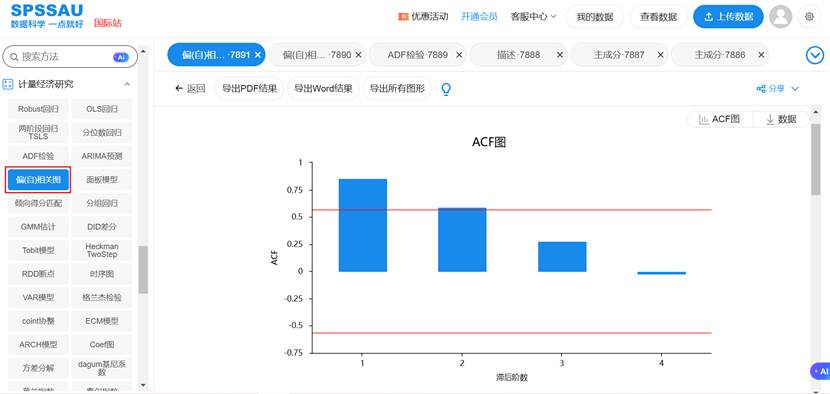
- 自相关图:揭示序列自身与其滞后项之间的相关性。平稳序列的自相关函数会快速衰减至零。
- 偏自相关图:在剔除中间变量影响后,揭示序列与特定滞后项之间的“纯粹”相关性。ACF和PACF图是识别模型类型的关键工具。SPSSAU【计量经济研究】模块提供【偏(自)相关图】,直接输出ACF和PACF图:
2. 平滑法
适用于无明显趋势/季节性的序列,或进行初步的趋势拟合。
- 移动平均:用近期观测值的简单平均值作为下一期的预测值。
- 指数平滑法:对近期观测值赋予更大权重,包括简单指数平滑、Holt双参数线性趋势平滑、Holt-Winters三参数季节模型等。在SPSSAU中,这些模型均可通过勾选轻松实现,并自动优化平滑参数。
3. ARIMA模型
这是分析平稳非白噪声序列最强大、最经典的框架。其核心思想如下图所示:
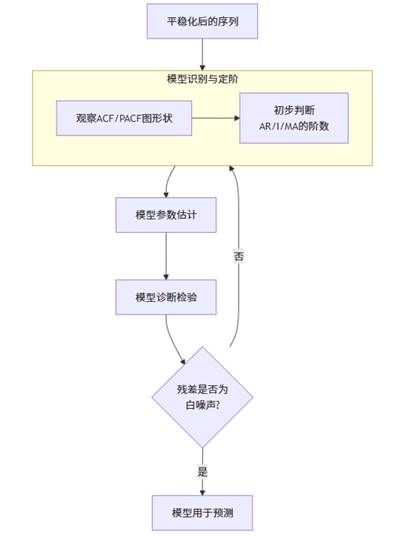
- ARIMA(p,d,q)模型由三个部分构成:
- AR(p):自回归模型。用自身过去p期的值来预测当前值。
- I(d):积分项。即进行了d阶差分使序列平稳。
- MA(q):移动平均模型。用过去q期的随机误差(白噪声)来预测当前值。
- 模型识别:通过观察平稳序列的ACF和PACF图的截尾/拖尾特性,初步判断p和q的值。
- 模型估计与检验:使用最大似然估计等方法求解模型参数,并检验其显著性。最关键的一步是检验残差是否为白噪声(即无任何信息可提取)。SPSSAU在完成ARIMA建模后,会自动输出Q统计量和对应p值,若p值大于0.05,则说明残差是白噪声,模型拟合良好。
4. 现代预测方法
- Prophet:由Facebook开源,特别适用于具有强季节性、节假日效应和缺失数据的时间序列,对异常值不敏感,更“自动化”。
- LSTM神经网络:一种深度学习模型,能够捕捉时间序列中复杂的长期依赖关系和非线性特征,适用于海量数据下的预测。
四、 关键注意事项与总结
1. 注意事项:科学与审慎
- 切忌忽视平稳性:这是最常犯的错误,直接导致无效模型。
- 避免过度拟合:模型不是越复杂越好。在样本外数据上测试预测效果,选择简洁且预测能力强的模型。
- 重视残差诊断:一个合格的模型,其残差必须近似于白噪声。
- 理解模型的局限性:任何统计模型都是对现实的简化。历史规律在未来不一定延续,需结合业务知识进行判断。
- 关注序列长度:通常建议至少有50个以上的观测点,模型才能有较好的稳定性。
2. 总结
时间序列分析是一条从数据预处理到模型预测的严谨路径。它要求我们:
- 始于目标与清洗,保证数据质量。
- 核心于平稳化,奠定模型基石。
- 成就于模型识别与诊断,构建最优统计模型。
- 终于预测与评估,将洞察转化为决策。
随着分析工具的进步,像SPSSAU这样的平台已经将时间序列分析中复杂的计算(如ADF检验、模型定阶、参数估计)高度自动化,研究者得以将更多精力投入到业务逻辑理解与模型结果解读上。掌握其核心思想与规范流程,你便能从纷繁复杂的时间数据中,提炼出有价值的规律与预见。

















 2783
2783

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









