



在社会科学、管理学、心理学等领域的实证研究中,我们常常需要回答这样一个问题:一个变量(X)对另一个变量(Y)的影响,会不会因为第三个变量(Z)的不同而不同? 这个第三个变量(Z),就是我们今天要讨论的主角——调节变量。
当调节变量是诸如性别、职业类型、教育水平等分类变量时,分析流程与连续型调节变量有所不同,涉及虚拟变量处理等关键步骤。本文将从理论到实践,系统梳理分类变量作为调节变量时的分析逻辑、操作流程与结果解读,并展示如何借助SPSSAU智能化平台,高效、准确地完成整个分析。
一、理论基石:什么是调节效应?
调节效应,顾名思义,是考察一个变量是否能够“调节”或“影响”另外两个变量之间关系的强度甚至方向。这个概念由统计学大师Baron和Kenny于1986年明确提出,并已成为机制研究中的核心方法之一。
我们可以用一个简单的比喻来理解:假设“学习时间”(X)对“考试成绩”(Y)有正向影响。那么,“学习质量”(Z)可能就是一个调节变量——对于学习质量高的学生,增加学习时间带来的成绩提升效果会更明显;而对于学习质量低的学生,效果可能就不那么显著。在这里,“学习质量”就调节了“学习时间”与“考试成绩”之间关系的强度。
当调节变量Z是分类变量(如性别:男/女;公司类型:A/B/C)时,我们实质上是在探究:X与Y的关系,在不同类型的群体或情境下是否存在显著差异。
二、分析流程总览:三步走战略
一个规范且完整的调节效应分析,通常遵循以下三步流程。为了更直观地展示,我们使用Mermaid流程图进行梳理:
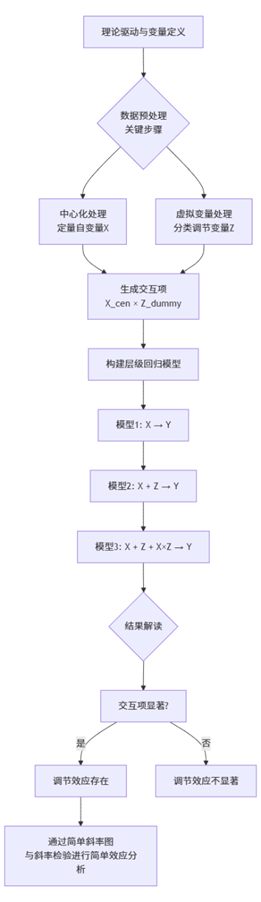
如上图所示,整个分析是一个环环相扣的过程。首先,分析必须始于理论驱动,明确你的研究假设。紧接着是至关重要的数据预处理阶段,特别是当调节变量为分类变量时。然后,通过构建一系列层级回归模型来检验交互项的显著性,从而判断调节效应是否存在。最后,如果效应存在,还需要进行简单效应分析(或简单斜率分析)来具体揭示调节作用的具体模式。
三、核心步骤拆解与SPSSAU的自动化实现
下面,我们详细解读上图中的几个核心步骤,并看看SPSSAU如何将这些步骤自动化。
步骤1:数据预处理——分析的基石
数据预处理是调节效应分析,尤其是包含分类调节变量分析中最容易出错,但也最为关键的一步。它主要包括两方面:
1.自变量的中心化或标准化
(1)理论与意义:对于连续型的自变量(如“团队合作”水平),我们通常需要对其进行中心化处理(即每个数据点减去均值)。这样做的主要目的是为了减少多重共线性问题,并使交互项的系数更易于解释。中心化后,变量的均值变为0,解读结果时更具现实意义。
(2)SPSSAU实现:在SPSSAU的“调节作用”分析模块中,用户只需将变量选入相应的“自变量”、“调节变量”框内。如果自变量是定量数据,SPSSAU会自动提示并执行中心化处理,用户无需手动计算。
2.分类调节变量的虚拟变量化
(1)理论与意义:回归分析只能处理数值型变量。当调节变量是分类变量(如“性别”,包含“男”、“女”两个类别)时,必须将其转化为一个或多个虚拟变量。通常,如果分类变量有k个类别,则需要生成k个虚拟变量。留一个虚拟变量不参与分析作为“参照组”或“基线组”,所有其他组的效应都是与这个参照组进行比较。
(2)SPSSAU实现:这是SPSSAU在处理分类调节变量时的巨大优势。用户将定类变量(如“性别”)选入“调节变量”框后,选择“调节类型”,系统会自动识别其数据类型,并自动完成虚拟变量的生成和设置(通常以第一个类别作为默认参照项)。用户完全无需手动创建虚拟变量,避免了繁琐的操作和可能的人为错误。操作示例如下:
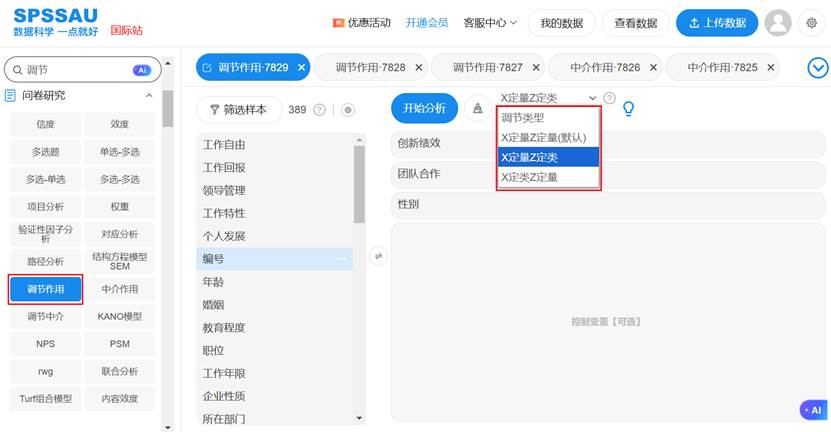
研究变量处理说明如下:

步骤2:生成交互项
- 理论与意义:调节效应的核心是交互作用。在统计模型中,我们通过引入“自变量”与“调节变量”的乘积项(即交互项)来表征这种效应。如果这个乘积项的系数显著,则说明调节效应存在。
- SPSSAU实现:SPSSAU在后台自动将处理好的中心化自变量与生成的调节变量虚拟变量进行相乘,生成交互项,并直接纳入后续的回归模型中。用户无需进行任何手动计算。
步骤3:构建层级回归模型与结果解读
调节效应的检验通常通过建立三个嵌套的回归模型来完成:
- 模型1:仅放入自变量 X,检验X对Y的主效应。
- 模型2:在模型1基础上,加入调节变量 Z(此处为虚拟变量),考察Z的主效应。
- 模型3:在模型2基础上,加入核心的交互项 X×Z。
如何判断调节效应是否存在?
主要有两种方式,二者结论通常一致:
- 查看交互项的显著性:在模型3中,如果交互项(如“团队合作×性别-女”)的回归系数达到了统计学上的显著水平(通常*p*<0.05),则表明调节效应存在。
- 查看模型拟合度的改善:比较模型2和模型3的R²变化(ΔR²)。如果ΔR²显著(即其对应的△F检验显著),说明加入交互项后,模型对数据的解释力有了显著提升,即调节效应存在。
SPSSAU的输出结果会清晰地呈现这三个模型的所有细节,包括每个变量的回归系数、标准误、t值、p值,以及模型的R²、调整后R²、F值和ΔR²、△F值。其“智能分析”功能还会自动根据交互项的显著性,用文字告诉你调节效应是否成立。分析结果示例如下:

四、深入分析:简单效应分析与可视化
当确认调节效应显著后,我们的工作并未结束。一个完整的分析还需要回答:“调节的具体模式是什么?”也就是说,我们需要知道在调节变量的不同类别下,X对Y的影响(即斜率)具体是怎样的。这就是简单效应分析(对于分类调节变量,也常称为简单斜率分析或组间比较)。
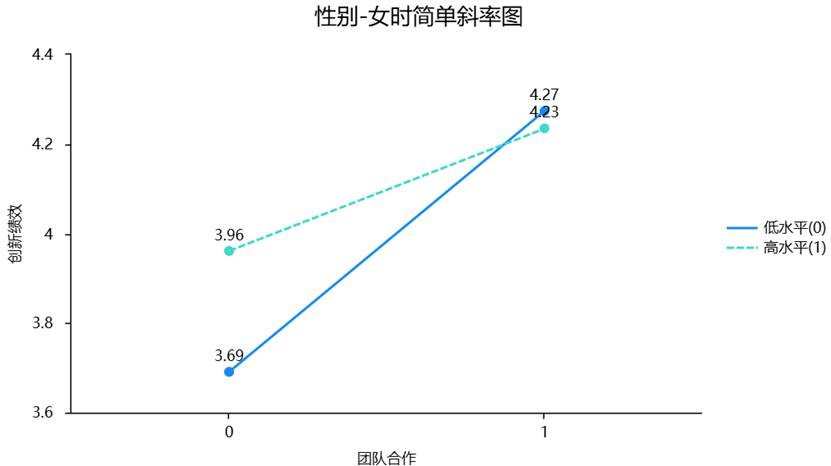
(1)理论与意义:简单效应分析是通过分别计算在调节变量Z的每一个特定水平上,自变量X对因变量Y的回归斜率来实现的。例如,当调节变量是性别时,我们需要分别求出对于“男性”和“女性”两个群体,“团队合作”对“创新绩效”的影响系数各是多少,并检验这两个系数是否存在显著差异。
(2)SPSSAU实现:SPSSAU的强大之处在于,它不仅能完成复杂的计算,还提供了极其友好的可视化输出。在调节效应分析结果中,SPSSAU会自动生成简单斜率图。这张图可以非常直观地展示,在调节变量(如性别)的不同水平上,自变量与因变量关系的斜率有何不同。是斜率变大了还是变小了?是正向关系减弱了还是反向了?如下图:
五、总结与最佳实践建议
将分类变量作为调节变量进行分析,是一个逻辑严谨、步骤清晰的过程。它要求研究者:
- 具备坚实的理论基础,明确假设。
- 严格遵循数据分析流程,特别是数据预处理环节。
- 完整地进行模型检验与后续分析,不能只停留在交互项是否显著上,还必须进行简单效应分析和结果可视化。
对于研究者而言,手动执行这些步骤——特别是中心化、生成虚拟变量、计算交互项——既繁琐又容易出错。SPSSAU的调节效应分析模块,将这些步骤全部自动化、智能化。用户只需明确变量角色,系统即可自动完成数据处理、模型构建、结果检验和图形生成,并输出易于理解的智能文字分析。这极大地解放了研究者,使其能更专注于理论思考和结果阐释,而非陷入复杂的技术操作中。

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









