



在社会科学、心理学、管理学等领域的研究中,我们常常需要测量一些无法直接观测的“潜变量”,如工作满意度、组织承诺、学习动机等。这时,验证性因子分析(Confirmatory Factor Analysis, CFA) 就成为了检验量表结构效度的核心工具。本文将系统介绍CFA的理论基础、分析流程、常用指标及其解读,并展示如何借助SPSSAU平台高效完成CFA分析。
一、CFA与EFA:两种因子分析的本质区别
在开始CFA之前,我们首先要明确它与探索性因子分析(EFA)的区别:
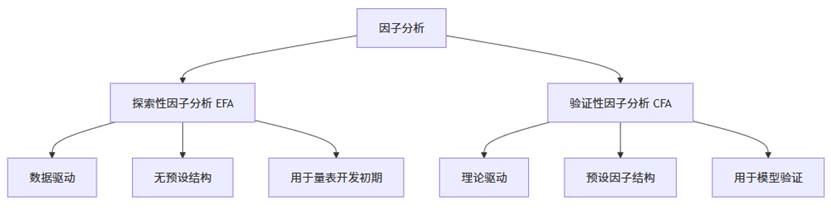
- EFA 是数据驱动的,研究者不清楚变量背后的因子结构,通过分析“探索”可能的因子数量与关系,帮助我们找到数据中的潜在维度。
- CFA 是理论驱动的,研究者基于已有理论或前期研究预设因子结构,再通过数据验证该结构是否成立,用统计模型确认这些维度是否稳定可靠。
二者核心区别说明如下:
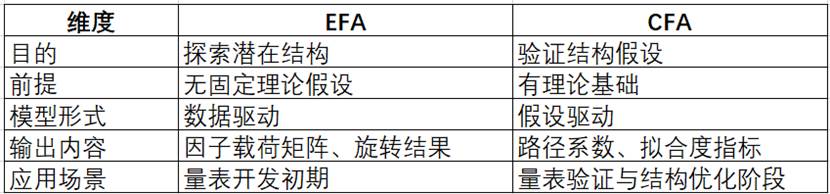
下面主要介绍验证性因子分析的相关内容。CFA的主要目的包括:
- 结构效度验证:检验量表是否真实测量了理论构念;
- 聚合效度:同一因子下的测量项是否高度相关;
- 区分效度:不同因子之间是否具有足够区分性;
- 共同方法偏差检验:检测是否存在因数据来源相同导致的虚假相关。
二、CFA分析全流程与SPSSAU操作示意
完整的CFA分析遵循一个清晰的逻辑流程,下图展示了在SPSSAU中执行CFA的标准步骤:
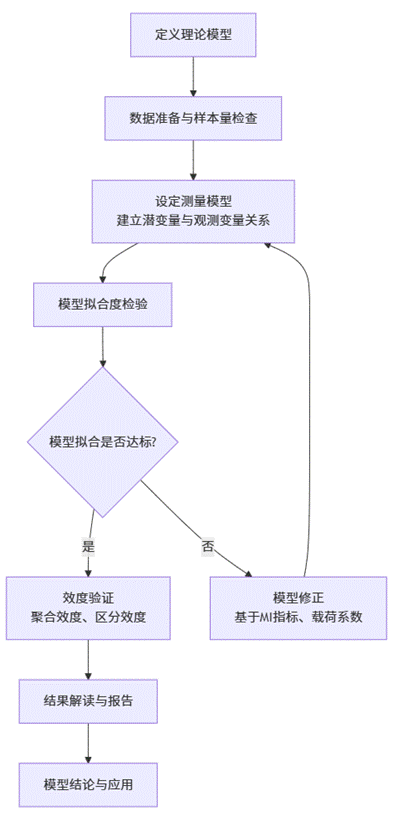
该流程图系统地展示了结构方程模型(SEM)从理论构建到实际应用的完整分析流程。
- 始于定义理论模型,即基于研究假设和理论基础,明确潜变量(如满意度、忠诚度等抽象概念)及其相互关系。
- 随后,进入数据准备与样本量检查阶段,确保收集的观测变量数据满足统计要求。
- 接着,通过设定测量模型,建立潜变量与观测变量的对应关系,并形成路径假设。
- 核心环节是模型拟合度检验,通过一系列统计指标评估模型与数据的匹配程度。
- 若拟合达标,则进入效度验证,检验模型的聚合效度与区分效度;若不达标,则需返回上一步,根据修正指数等信息对模型进行迭代优化。
- 最后,在结果解读与报告和模型结论与应用阶段,分析参数并形成研究报告,将发现转化为理论贡献或实践指导。
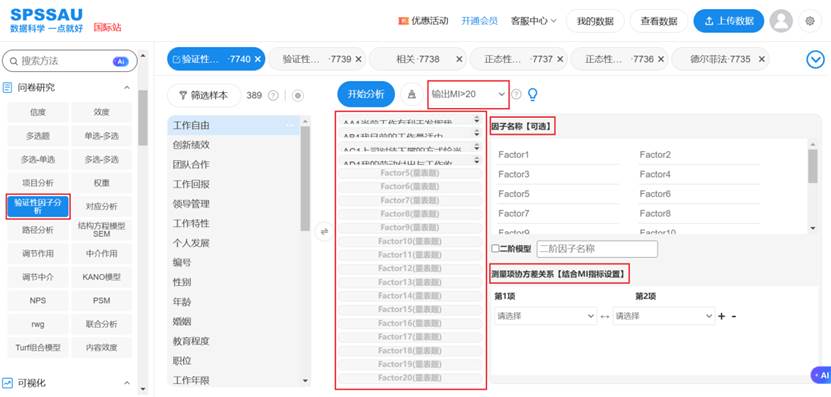
每个步骤在SPSSAU中都有对应的自动化输出与智能分析建议,即使是初学者也能轻松完成。SPSSAU软件进行验证性因子分析操作示例如下图:
三、CFA核心指标解读与SPSSAU输出详解
1. 因子载荷系数
因子载荷反映了测量项与潜变量之间的关联强度。载荷越高,说明测量项能更好地代表潜在因子。通常使用标准化载荷系数,其判断标准为:
- >0.7:理想状态
- 0.5~0.7:可接受
- <0.5:考虑删除
SPSSAU在CFA输出中会自动提供标准化载荷系数与标准误差,并附显著性检验结果,同时自动标记出载荷系数较低的测量项,并建议是否移除。结果示例如下图:
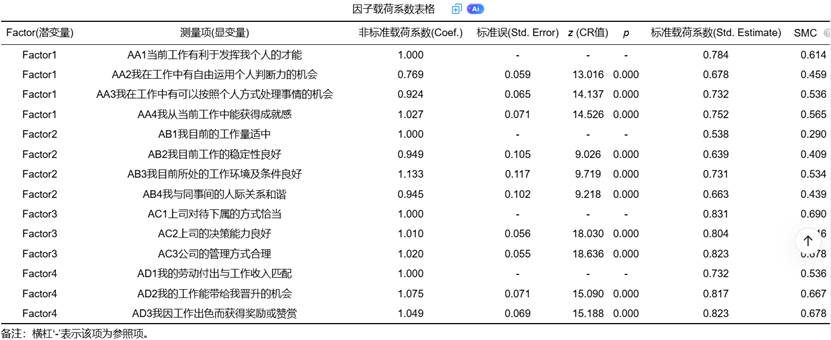
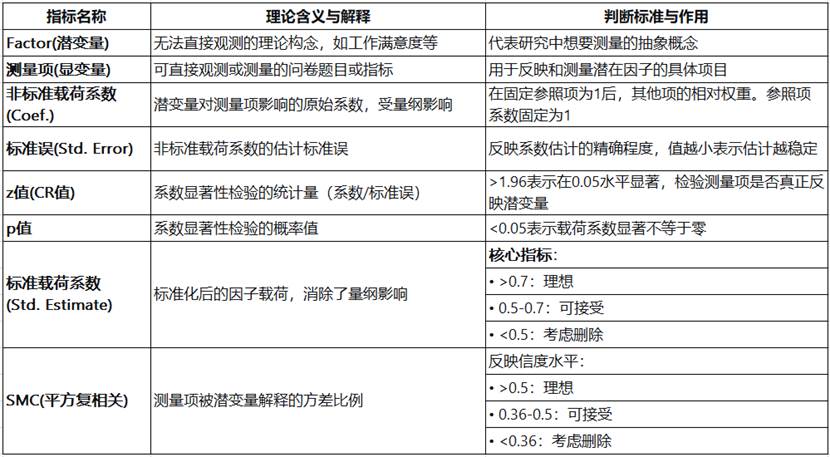
上表中指标含义与解释说明如下表:
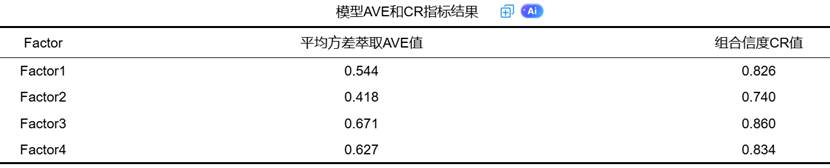
2. 聚合效度:AVE与CR指标
聚合效度指同一构念下各测量项之间的相关性,用于评估“同一潜变量下的测量项是否真的测量了同一个概念”。通过AVE和CR两个指标衡量:
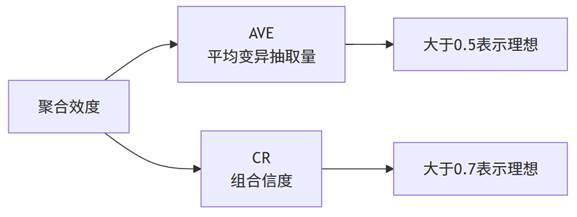
- AVE:表示潜变量能解释多少比例的测量项变异,>0.5为佳;
- CR:表示构念内部一致性,>0.7为佳。
SPSSAU会自动计算这两个指标,智能分析会直接给出是否达标的判断。
3. 区分效度检验
区分效度用于判断不同潜变量是否能彼此区分,即它们是否测量了不同的构念。区分效度检验方法多样,SPSSAU提供了三种主流方法:
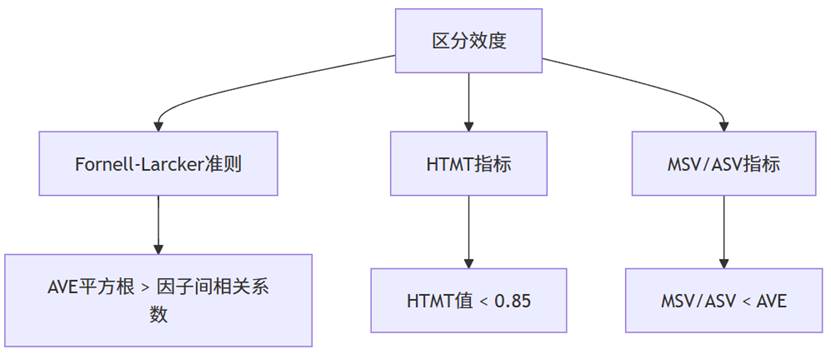
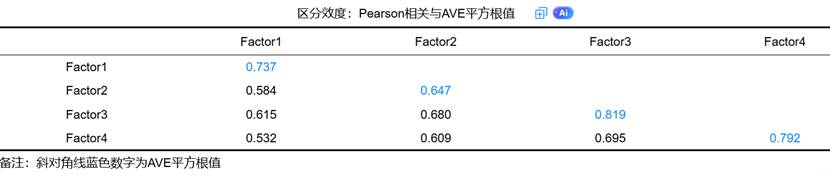
(1)Fornell-Larcker法:要求每个潜变量的AVE平方根值大于其与其他潜变量的相关系数。
下表格中斜对角线为AVE平方根值,其余值为相关系数;AVE平方根值可表示因子的‘聚合性’,相关系数表示相关关系,如果因子‘聚合性’很强(明显强于与其它因子间的相关系数绝对值),则能说明具有区分效度;如果某因子AVE平方根值,大于该因子与其它因子的相关系数绝对值。并且所有因子均呈现出这样的结论,则说明具有良好的区分效度。
(2)HTMT法(Heterotrait-Monotrait Ratio):若HTMT值低于0.85(或0.9),表示区分效度良好。
下表格中的数值表示两两因子之间的HTMT值,通常情况下HTMT值小于0.85(有时以0.9作为标准)则说明该两因子之间具有区分效度。表格中所有的HTMT值均在标准范围内,此时说明数据具有区分效度。

(3)MSV与ASV法:若共享方差(MSV、ASV)小于AVE,也能证明区分性。
通常情况下MSV值小于AVE值,并且ASV值小于AVE值则说明具有区分效度。

SPSSAU在结果中会同时输出三种验证路径,使研究者可多角度判断效度稳健性。
4. 模型拟合指标
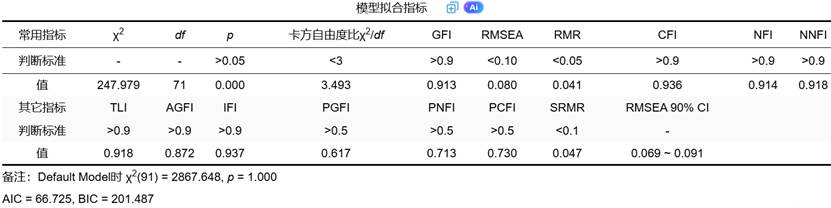
CFA最终的目标是建立一个与真实数据“拟合良好”的模型。模型拟合指标评估理论模型与数据的匹配程度,SPSSAU输出完整的拟合指标表,如下图:
模型拟合指标解读如下:
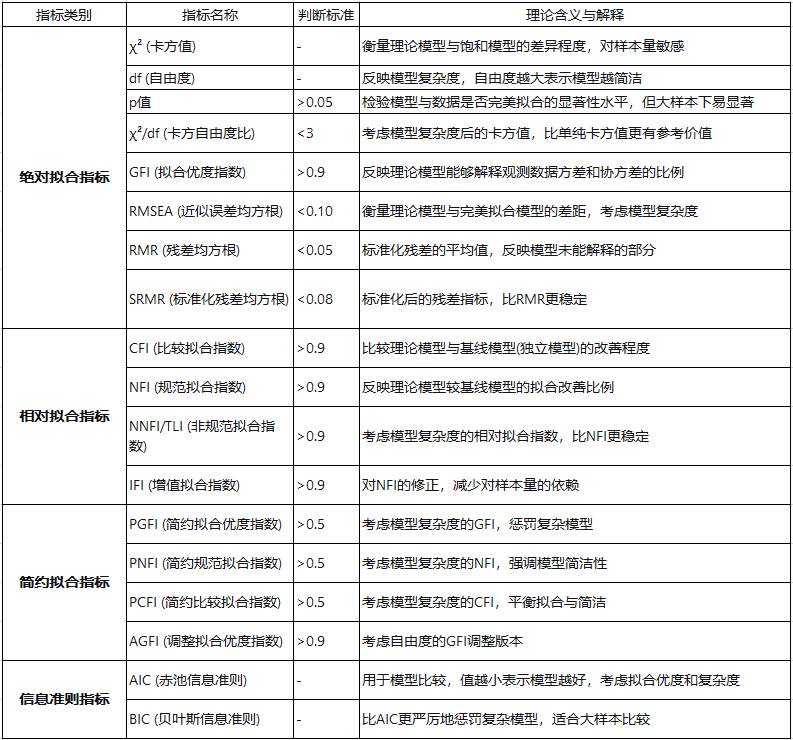
- 绝对拟合指标:直接衡量理论模型与观测数据的匹配程度
- 相对拟合指标:通过与基线模型比较来评估模型改善程度
- 简约拟合指标:在拟合优度基础上考虑模型简洁性
- 信息准则指标:主要用于不同模型之间的比较选择
实际应用建议:在实际研究中,不需要所有指标都达标。通常重点关注:χ²/df < 3、RMSEA < 0.08、CFI > 0.9、SRMR < 0.08。这些指标在SPSSAU中会一次性完整输出,并提供智能判断,帮助研究者快速了解模型拟合状况。
5. 模型修正指标
当模型拟合不佳时,需要进行模型修正。SPSSAU提供的MI(Modification Index)表格,展示了潜变量与测量项之间或测量项之间的潜在共变关系。当MI值较大时,可能意味着模型中存在潜在的遗漏路径或冗余测量。
- MI修正指标:反映如果释放某条参数限制,模型会改善多少;
- 测量项间MI:提示哪些测量项的误差项可能存在相关;
- 因子与测量项MI:提示某测量项可能更适合归属另一因子。
在CFA模型微调阶段,研究者可参考MI指标重新设定路径、移除弱项或建立协方差。SPSSAU的“智能分析”功能会自动识别并给出模型调整建议,让模型修正过程更高效、更直观。SPSSAU分析前可设置输出MI指标,如下图:

四、CFA在方法偏差检验中的应用
共同方法偏差是问卷研究中常见的问题,CMV用于评估由于同一测量来源(如同一问卷、同一时间收集)带来的偏差。SPSSAU可通过CFA模型的单因子检验或Harman检验评估CMV问题,帮助研究者识别潜在的系统误差风险。这一功能在心理学、组织管理与教育研究中尤为重要。
单因子检验法:将所有测量项负载到一个因子上,比较单因子模型与理论模型的拟合度。如果单因子模型拟合度与理论模型相近,可能存在严重的共同方法偏差。
五、SPSSAU的CFA分析优势
作为一款智能数据分析平台,SPSSAU在CFA分析中展现出多项优势:
- 一键自动化分析:从数据导入到结果解读,全程智能化;
- 多指标联合输出:一次性输出因子载荷、拟合指标、效度指标等全部结果;
- 智能建议系统:自动识别问题项并提供修正建议;
- 可视化图表:自动生成模型结果图,如下图:
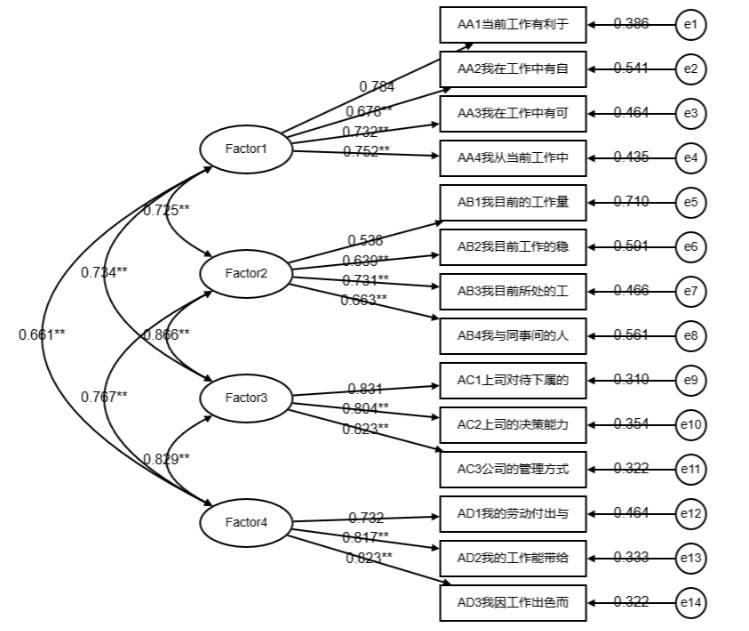
- 适合各层次用户:既适合初学者的引导式分析,也适合资深研究者的深度定制。
无论是学术论文写作、量表开发,还是企业调研验证,SPSSAU都能提供专业级的CFA分析支持。
六、总结
验证性因子分析是量表效度验证的核心技术,通过系统的指标检验和模型评估,确保测量工具的科学性和准确性。SPSSAU平台将复杂的CFA分析流程标准化、自动化,让研究者能更专注于理论构建和结果解释,而非技术细节。

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









