




1. Yarn资源调度器
Yarn是一个资源调度平台,负责为运算程序提供服务器运算资源,相当于一个分布式的操作系统,而MapReduce等运算程序则相当于运行于操作系统之上的应用程序
1.1 Yarn基础架构
Yarn主要由ResourceManager、NodeManager、ApplicationMaster和Container等组件构成
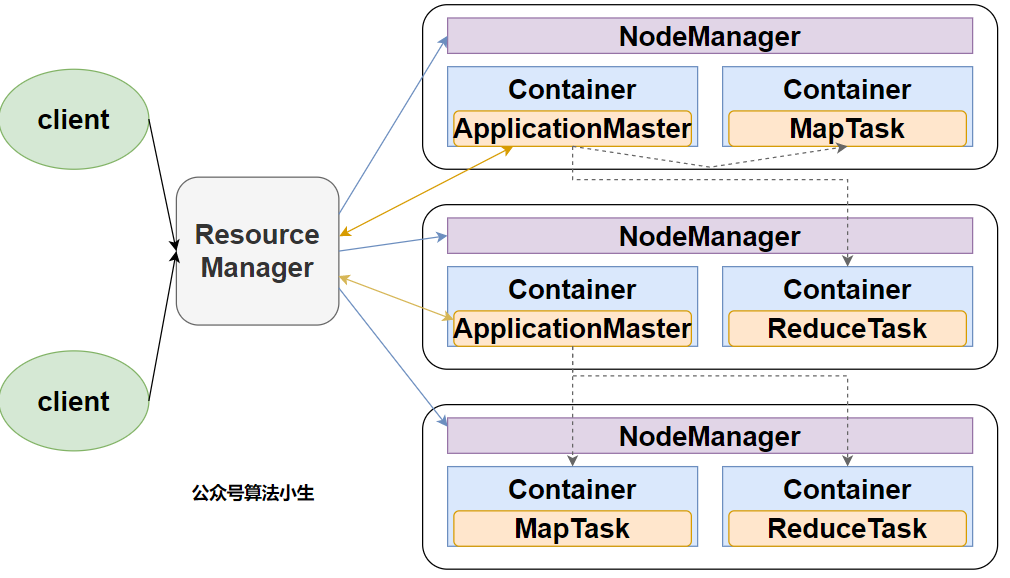
ResourceManager(RM)作用:
- 处理客户端请求
- 监控NodeManager
- 启动或监控ApplicationMaster
- 资源分配与调度
NodeManager(NM)作用:
- 管理单个节点上的资源
- 处理来自ResourceManager的命令
- 处理来自ApplicationMaster的命令
ApplicationMaster(AM)作用:
- 为应用程序申请资源并分配给内部的任务
- 任务的监控与容错
Container:
Container是Yarn中的资源抽象,它封装了某个节点上的多维度资源,如内存、CPU、磁盘、网络等
Hadoop作业调度器主要有三种:FIFO、容量(Capacity Scheduler)和公平(Fair Scheduler)
Apache hadoop-2.7.2之后默认调度器是容量调度器Capacity Scheduler
Apache hadoop-3.2.2默认调度器是公平调度器Fair Scheduler
2. Yarn三大调度器
2.1 先进先出调度器FIFO
FIFO调度器(First In First Out):单队列,根据提交作业的先后顺序,先来先服务
2.2 容量调度器
Capacity Scheduler是Yahoo开发的多用户调度器
2.2.1 容量调度器特点

- 多队列:每个队列可配置一定的资源量,每个队列采用FIFO调用策略
- 容量保证:管理员可为每个队列设置资源最低保证和使用上限
- 灵活性:如果队列资源有剩余,可以暂时共享给其他需要资源的队列,而一旦该队列有新的应用程序提交,则其他队列借调的资源会归还
- 多租户:支持多用户共享集群和多应用程序同时运行。为了防止同一个用户作业独占队列中资源,该调度器会对同一用户提交的作业所占资源量进行限定
2.2.2 容量调度器资源分配算法
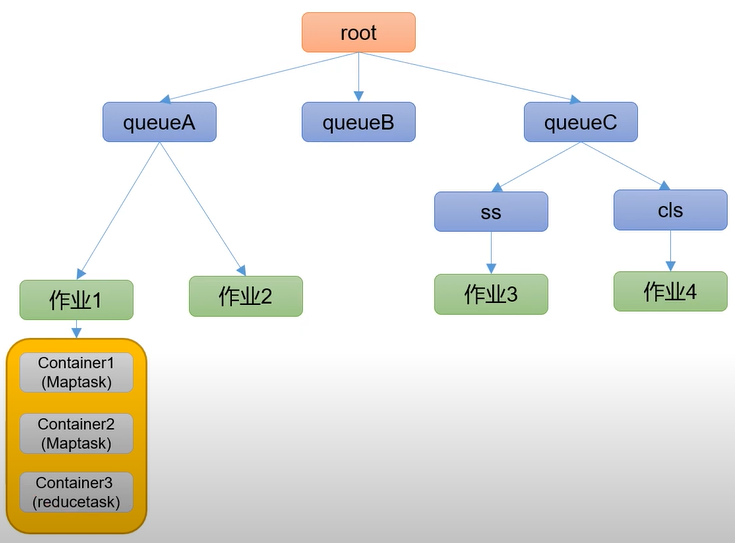
- 队列资源分配:从root开始,使用深度优先算法,优先选择资源占用率最低的队列分配资源
- 作业资源分配:默认按照提交作业的优先级和提交时间顺序分配资源
- 容器资源分配:按照容器的优先级分配资源;如果优先级相同,按照数据本地性原则:
- 任务和数据在同一节点
- 任务和数据在同一机架
- 任务和数据不在同一节点也不在同一机架
2.3 公平调度器
公平调度器除了具有容量调度器的特点外,不同点在于:
- 核心调用策略不同:容量调度器优先选择利用率低的队列;公平调度器优先选择对资源的缺额【应获资源和实际获取的资源差距叫缺额】比较大的
- 每个队列可以设置资源分配方式:容量调度器FIFO、DRF【Dominant Resource Fairness,根据CPU和内存公平调度资源】;公平调度器:FIFO、FAIR、DRF
3. Yarn工作机制
Yarn工作机制是面试的重点,需要重点理解学习

- MR程序提交到客户端所在的节点
- YarnRunner向ResourceManager申请一个Application
- RM将该应用程序的资源路径返回给YarnRunner
- 该程序将运行所需资源提交到HDFS上
- 程序资源提交完毕后,申请运行MRAppMaster
- RM将用户的请求初始化成一个Task
- 其中一个NodeManager领取到Task任务
- 该NodeManager创建容器Container,并产生MRAppMaster
- Container从HDFS上拷贝资源到本地
- MRAppMaster向RM申请运行MapTask资源
- RM将运行MapTask任务分配给另外两个NodeManager,另两个NodeManager分
别领取任务并创建容器 - MR向两个接收到任务的NodeManager发送程序启动脚本,这两个NodeManager分别启动MapTask,MapTask对数据分区排序
- MrAppMaster等待所有MapTask运行完毕后,向RM申请容器,运行ReduceTask
- ReduceTask向MapTask获取相应分区的数据
- 程序运行完毕后,MR会向RM申请注销自己
4. Yarn Tool接口实现动态传参
当我们通过yarn向集群提交自定义任务时,若传入队列参数会报错
yarn jar hadoop-1.0-SNAPSHOT.jar online/shenjian/hadoop/WordCountDriver -Dmapreduce.job.queuename=hive /shenjian/input/ /shenjian/output
/bin/sh: 25: Dmapreduce.job.queuename=hive: not found
此时我们需要Tool工具,进行动态传参控制
4.1 新建WordCount实现Tool接口
public class WordCount implements Tool {
private Configuration conf;
@Override
public int run(String[] args) throws Exception {
Job job = Job.getInstance(conf);
job.setJarByClass(WordCountDriver.class);
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
return job.waitForCompletion(true) ? 0 : 1;
}
@Override
public void setConf(Configuration conf) {
this.conf = conf;
}
@Override
public Configuration getConf() {
return conf;
}
public static class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
private Text keyOut = new Text();
private IntWritable valueOut = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] words = line.split(" ");
for (String word : words) {
keyOut.set(word);
context.write(keyOut, valueOut);
}
}
}
public static class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable valueOut = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
valueOut.set(sum);
context.write(key, valueOut);
}
}
}
4.2 新建WordDriver类
public class WordCountDriver {
private static Tool tool;
public static void main(String[] args) throws Exception {
// 1. 创建配置文件
Configuration conf = new Configuration();
// 2. 判断是否有 tool 接口
switch (args[0]) {
case "wordcount":
tool = new WordCount();
break;
// 当然有更多的控制需求可以进行其他case调整
default:
throw new RuntimeException(" No such tool: " + args[0]);
}
// 3. 用 Tool 执行程序
// Arrays.copyOfRange 将老数组的元素放到新数组里面
int run = ToolRunner.run(conf, tool, Arrays.copyOfRange(args, 1, args.length));
System.exit(run);
}
}
4.3 提交至集群运行
其中-开头的参数为设置参数,arg[0]=wordcount, args[1]=/shenjian/input/, args[2]=/shenjian/output
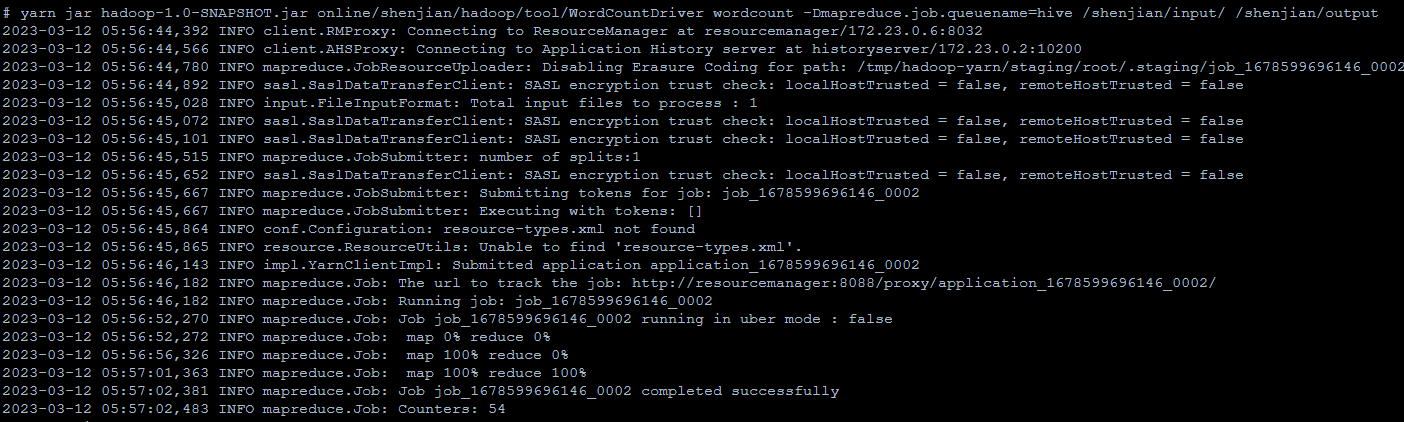
yarn jar hadoop-1.0-SNAPSHOT.jar online/shenjian/hadoop/tool/WordCountDriver wordcount -Dmapreduce.job.queuename=hive /shenjian/input/ /shenjian/output
欢迎关注公众号算法小生与我沟通交流



















 5504
5504

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











