




1. Yarn容量调度器
在中小型企业中,我们一般配置为容量调度器
请先检查本地host配置
127.0.0.1 datanode
127.0.0.1 namenode
127.0.0.1 resourcemanager
127.0.0.1 nodemanager
127.0.0.1 nodemanager2
127.0.0.1 historyserver
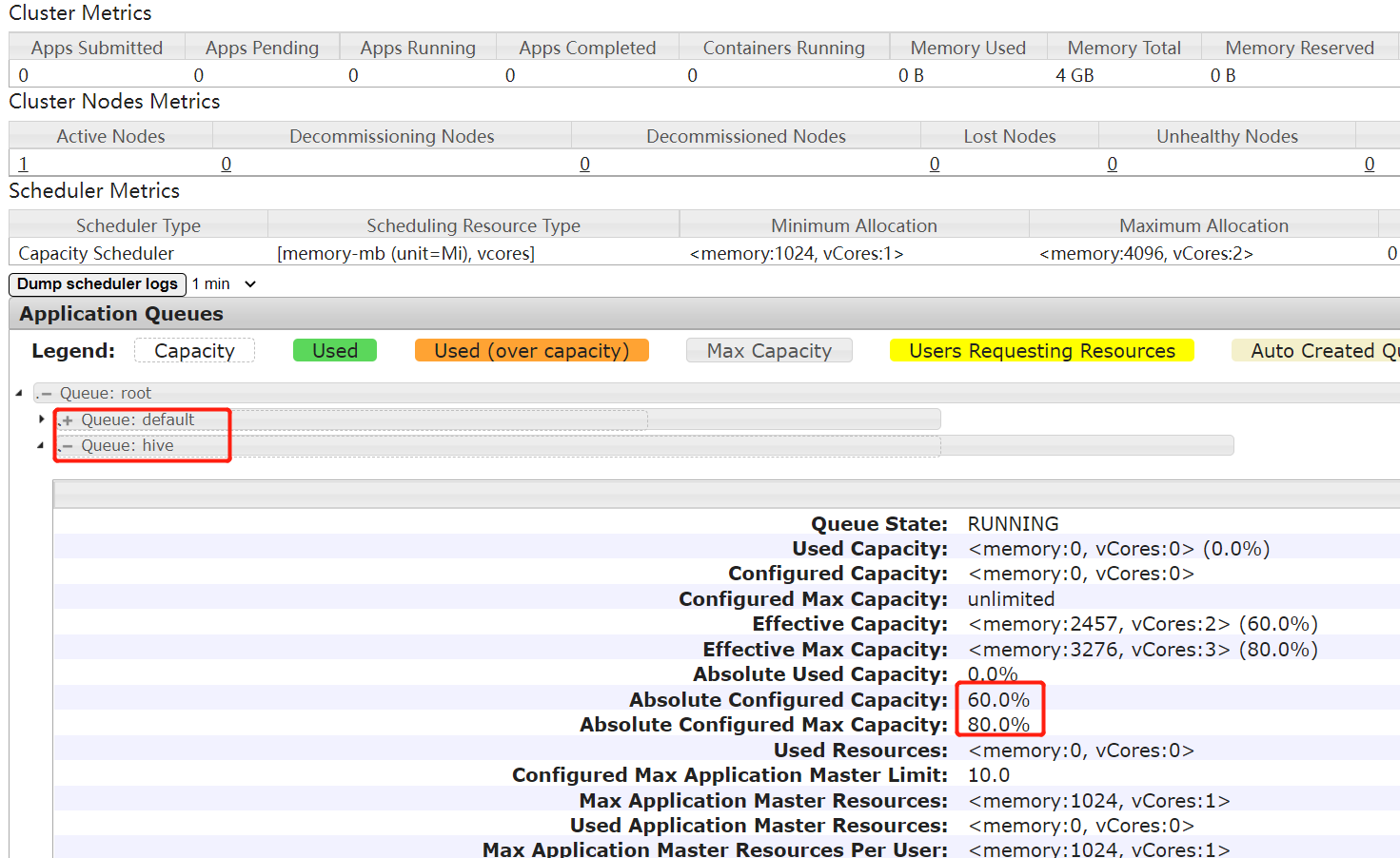
2.1 容器调度器配置多队列
需求 1:default 队列占总内存的40%,最大资源容量占总资源60%,hive 队列占总内存
的60%,最大资源容量占总资源80%。
需求 2:配置队列优先级
多队列配置需要/opt/hadoop-3.2.1/etc/hadoop/capacity-scheduler.xml,我们先将容器中该文件拷贝出来
docker cp fd7a9150237:/opt/hadoop-3.2.1/etc/hadoop/capacity-scheduler.xml .
对于docker-compose.yml中所有容器进行挂载
volumes:
- ./capacity-scheduler.xml:/opt/hadoop-3.2.1/etc/hadoop/capacity-scheduler.xml
同时我们对nodemanager映射端口8042,historyserver映射端口8188,并且新增1个nodemanager节点【笔者执行WordCount时单节点资源不够导致mapreduce无法进行】
nodemanager:
ports:
- 8042:8042
nodemanager2:
image: bde2020/hadoop-nodemanager:2.0.0-hadoop3.2.1-java8
container_name: nodemanager2
hostname: nodemanager2
ports:
- 8043:8042
environment:
SERVICE_PRECONDITION: "namenode:9000 namenode:9870 datanode:9864 resourcemanager:8088"
volumes:
- ./capacity-scheduler.xml:/opt/hadoop-3.2.1/etc/hadoop/capacity-scheduler.xml
env_file:
- ./hadoop.env
historyserver:
ports:
- 8188:8188
【修改】capacity-scheduler.xml中配置
<!-- 指定多队列,增加 hive 队列 -->
<property>
<name>yarn.scheduler.capacity.root.queues</name>
<value>default,hive</value>
</property>
<!-- 降低 default 队列资源额定容量为 40%,默认 100% -->
<property>
<name>yarn.scheduler.capacity.root.default.capacity</name>
<value>40</value>
</property>
<!-- 降低 default 队列资源最大容量为 60%,默认 100% -->
<property>
<name>yarn.scheduler.capacity.root.default.maximum-capacity</name>
<value>60</value>
</property>
【新增】capacity-scheduler.xml中配置
<!-- 指定 hive 队列的资源额定容量 -->
<property>
<name>yarn.scheduler.capacity.root.hive.capacity</name>
<value>60</value>
</property>
<!-- 用户最多可以使用队列多少资源,1 表示 -->
<property>
<name>yarn.scheduler.capacity.root.hive.user-limit-factor</name>
<value>1</value>
</property>
<!-- 指定 hive 队列的资源最大容量 -->
<property>
<name>yarn.scheduler.capacity.root.hive.maximum-capacity</name>
<value>80</value>
</property>
<!-- 启动 hive 队列 -->
<property>
<name>yarn.scheduler.capacity.root.hive.state</name>
<value>RUNNING</value>
</property>
<!-- 哪些用户有权向队列提交作业 -->
<property>
<name>yarn.scheduler.capacity.root.hive.acl_submit_applications</name>
<value>*</value>
</property>
<!-- 哪些用户有权操作队列,管理员权限(查看/杀死) -->
<property>
<name>yarn.scheduler.capacity.root.hive.acl_administer_queue</name>
<value>*</value>
</property>
<!-- 哪些用户有权配置提交任务优先级 -->
<property>
<name>yarn.scheduler.capacity.root.hive.acl_application_max_priority</name>
<value>*</value>
</property>
<!-- 如果 application 指定了超时时间,则提交到该队列的 application 能够指定的最大超时
时间不能超过该值,-1不超时 -->
<property>
<name>yarn.scheduler.capacity.root.hive.maximum-application-lifetime</name>
<value>-1</value>
</property>
<!-- 如果 application 没指定超时时间,则用 default-application-lifetime 作为默认
值 -->
<property>
<name>yarn.scheduler.capacity.root.hive.default-application-lifetime</name>
<value>-1</value>
</property>
【修改】hadoop.env文件,根据情况相应调整
MAPRED_CONF_mapred_child_java_opts=-Xmx1024m
MAPRED_CONF_mapreduce_map_memory_mb=2048
MAPRED_CONF_mapreduce_reduce_memory_mb=2048
MAPRED_CONF_mapreduce_map_java_opts=-Xmx1024m
MAPRED_CONF_mapreduce_reduce_java_opts=-Xmx2048m
配置好后,再次执行docker-compose up -d会recreate容器
访问http://resourcemanager:8088/cluster/scheduler后可以看到hive队列已出现
2.2 向hive队列中提交任务
hadoop jar /opt/hadoop-3.2.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar wordcount -D mapreduce.job.queuename=hive /shenjian/input /shenjian/output
当然我们也可以通过在WordCountDriver中配置
conf.set("mapreduce.job.queuename", "hive");

一会可以在FINSHED中看到完成信息,如下图所示
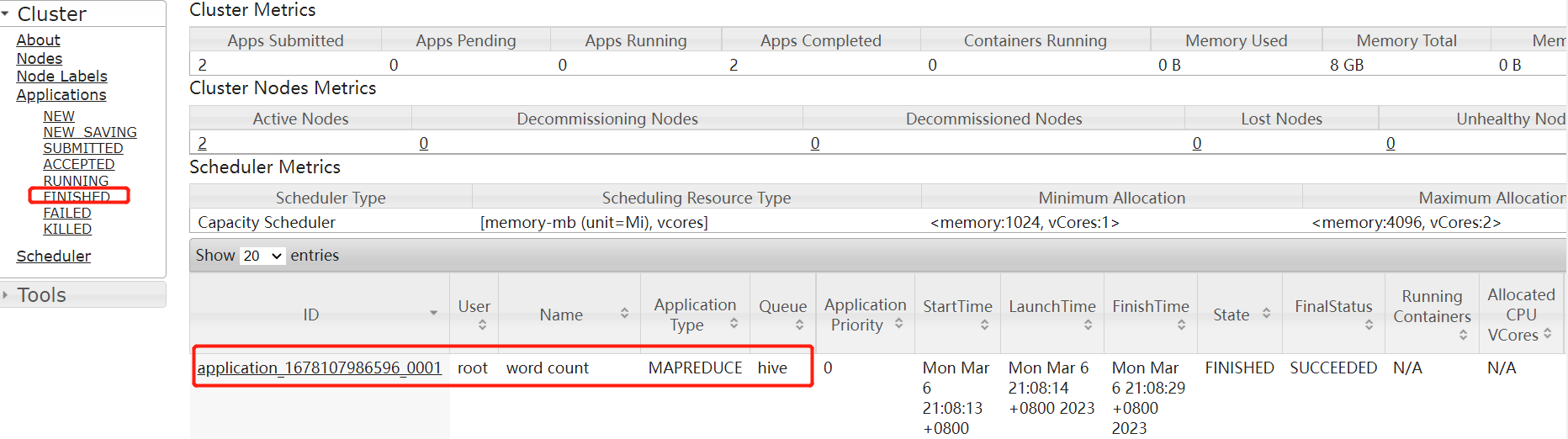
点击ID,可以点击LOGS查看具体日志信息,当然失败时会有不同的文件生成,点击查看错误日志即可

2.3 任务优先级设置
在hadoop.env中配置
// 任务最高优先级为5
YARN_CONF_yarn_cluster_max___application___priority=5
提交优先级高的任务
hadoop jar /opt/hadoop-3.2.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar pi -D mapreduce.job.priority=5 5 2000000
也可以通过以下命令修改正在执行的任务的优先级
yarn application -appID <Application ID> -updatePriority 优先级
2. 生产环境核心参数配置
我们先按照之前的配置启动好hadoop集群,连接到resourcemanager节点shell
2.1.常用命令
// 列出所有Application
# yarn application -list
// 列出所有已结束的Application
# yarn application -list -appStates FINISHED
// KILL调Application
# yarn application -kill <Application ID>
// 查看Application日志
# yarn logs -applicationId <Application ID>
// 查看Container日志
# yarn logs -applicationId <Application ID> -containerId <Container ID>
// 查看所有Application尝试的列表,此中会显示出ApplicationAttempt-Id、AM-Container-Id等信息
# yarn applicationattempt -list <Application ID>
// 打印ApplicationAttempt状态
# yarn applicationattempt -status <Application Attempt ID>
// 列出所有容器,容器只有在运行的时候才可查看到
# yarn container -list <Application Attempt ID>
// 打印container状态
# yarn container -status <Container ID>
// 列出所有节点
# yarn node -list -all
// 加载队列配置
# yarn rmadmin -refreshQueues
// 打印队列信息, default为默认队列名
# yarn queue -status <Queue Name>
2.2 生产环境核心配置
需求:从1G数据中,统计每个单词出现次数。服务器3台,每台配置4G内存,4核CPU,4线程
分析:1G/128m(默认块大小)=8个MapTask,1个ReduceTask,1个MrAppMaster。平均每个节点运行10个/3台≈3个任务(4 3 3)
以下hadoop.env配置会被映射到/opt/hadoop-3.2.1/etc/hadoop/yarn-site.xml
// 调度器类型指定
YARN_CONF_yarn_resourcemanager_scheduler_class=org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler
// ResourceManager处理调度器请求的线程数量,默认50;如果提交的任务数大于50,可以增加该值,但是不能超过3台*4线程(去除其他应用程序实际不超过8)
YARN_CONF_yarn_resourcemanager_scheduler_client_thread__count=8
// 是否yarn自动检测硬件进行配置,默认false,如果该节点有很多其他应用程序,建议手工配置。
YARN_CONF_yarn_nodemanager_resource_detect__hardware__capabilities=false
// 是否将虚拟核数当做CPU核数,默认false,采用物理CPU核数,对于节点机器配置相同的话,默认就好
YARN_CONF_yarn_nodemanager_resource_count__logical__processors__as__cores=false
// 虚拟核数和物理核数乘数,默认1.0
YARN_CONF_yarn_nodemanager_resource_pcores__vcores__multiplier=1.0
// NodeManager使用内存数,默认8G,修改为4G
YARN_CONF_yarn_nodemanager_resource_memory___mb=4096
// NodeManager的CPU核数,不按照硬件环境自动设定时默认是8个,修改为4个
YARN_CONF_yarn_nodemanager_resource_cpu___vcores=4
// 容器最大内存,默认8G,修改为2G
YARN_CONF_yarn_scheduler_maximum_allocation_mb=2048
// 容器最大CPU核数,默认4个,修改为2个
YARN_CONF_yarn_scheduler_maximum___allocation___vcores=2
// 虚拟内存检查,默认打开,修改为关闭,因为JDK实际使用的虚拟内存不用Linux系统为Java进程预留的虚拟内存,导致虚拟内存分配使用率低
YARN_CONF_yarn_nodemanager_vmem__check__enabled=false
// 虚拟内存和物理内存设置比例,默认2.1
YARN_CONF_yarn_nodemanager_vmem__pmem__ratio=2.1
// 注意检查下面配置也相应缩小,否则ResourceManager无法启动
YARN_CONF_yarn_scheduler_capacity_root_default_maximum___allocation___mb=2048
YARN_CONF_yarn_scheduler_capacity_root_default_maximum___allocation___vcores=2
欢迎关注公众号算法小生与我沟通交流
欢迎关注公众号算法小生与我沟通交流



















 3489
3489

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











