




3月12日,谷歌用一场发布会重新定义了AI模型的性价比——Gemma 3系列开源模型发布,号称“单GPU最强AI模型”。Gemma-3共有四种不同参数规模,分别为10亿、40亿、120亿和270亿参数。其中最大参数的27B模型仅需一张H100显卡即可运行!
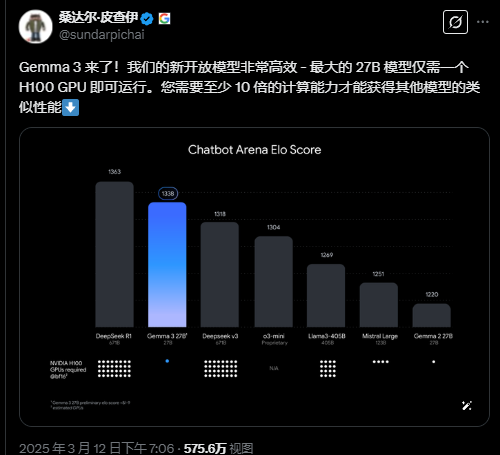
Gemma-3在LMArena得分为1338,性能超越Meta的Llama-405B、DeepSeek-V3等大模型。
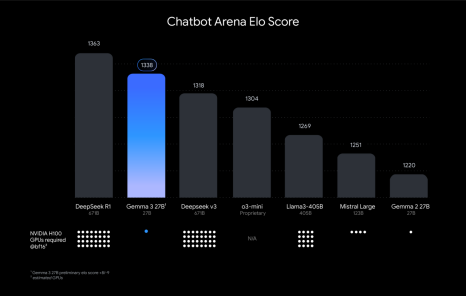
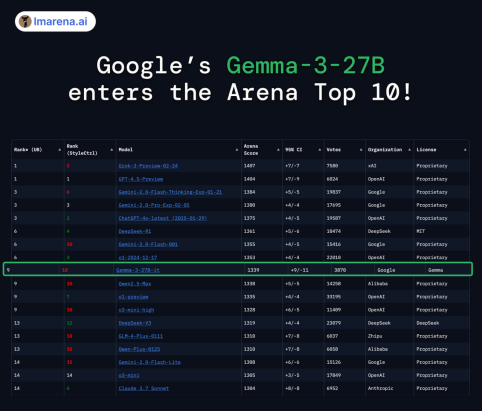
同时,Gemma 3也跻身ChatBot Arena Imarena Top 10,击败许多同等参数的模型,在开源模型中仅次于DeepSeek-R1。而且同其他性能相当的模型相比,Gemma 3仅消耗了1/10的计算资源。
更令人瞩目的是其多语言能力——目前支持超过35种语言,能够分析文本、图像及短视频。对于全球化企业而言,这意味着无需额外标注数据即可开发多语言客服系统或内容平台。
同时,新版本的视觉编码器也得到了升级,支持高分辨率和非方形图像,并引入了新的 ShieldGemma2图像安全分类器,以便过滤输入和输出中被分类为危险或暴力的内容。
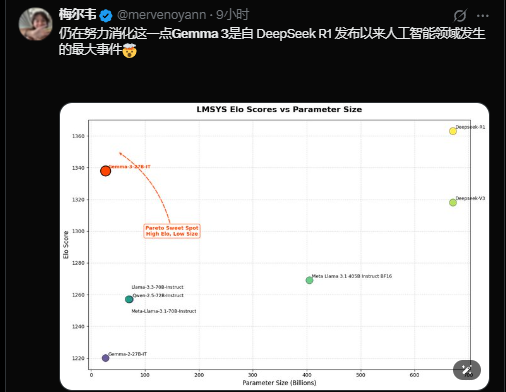
有网友表示“Gemma 3是自DeepSeek-R1发布以来人工智能领域发生的最大事件”:
当“轻量级”成为新战场
大模型的能耗与成本一直是AI行业的痛点之一。然而,过去一年,DeepSeek等模型的崛起已证明,市场对低硬件门槛的AI需求越来越大。
而Gemma 3的杀手锏在于,它将轻量化与高性能结合到了极致——1B到27B四种参数版本适配不同硬件,最小的1B模型也能处理32K tokens的上下文,还能在手机端运行。
即便是最大的27B版本也只需要一张H100就足以解析一本300页的书籍或1小时视频。
这背后是谷歌对硬件生态的深度绑定:针对英伟达H100和TPU的优化、支持AMD GPU的ROCm堆栈,甚至推出Gemma.cpp实现CPU部署。这种全栈式适配,让开发者能够在各种设备上运行,从智能手机到工作站均可兼容。

或重新定义AI竞赛规则
当27B模型单卡跑赢405B对手,AI大模型是否真的需要万亿参数?谷歌的答案很明确——通过架构优化、硬件协同和开源生态,让小模型释放大能量。这不仅可能会威胁DeepSeek等专注轻量化的玩家,甚至可能重塑OpenAI的闭源霸权。在芯片封锁下,如何学会用技术游击战突围,或许Gemma 3正是教科书级的案例。
未来的AI战场,或许不再属于拥有最多GPU的巨头,而是那些能用1%的算力实现90%效果的技术革新者。Gemma 3已按下启动键,这场效率革命,才刚刚开始。
大家怎么看?欢迎在评论区留言讨论~


















 125
125

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









