







这篇论文收录在2017年CVPR上,跟2015年发表在CVPR上的论文《From Captions to Visual Concepts and Back》都是微软研究院创作的。跟《From Captions to Visual Concepts and Back》方法有点类似,不过将其方法改进,将image caption扩展到了novel objects上。
一、introduction
这一部分点出了论文提出来的一种新框架LSTM-C,全称是 Long Short-Term Memory with Copying Mechanism 。该机制主要工作原理,给定一张图片,利用CNN提取特征并作为语言模型LSTM的初始时刻的输入,另一方面,目标检测网络识别出图片中的物体,接下来复制机制考虑怎么将识别出来的物体放到输出中。
二、Related Work
提到image caption、novel object caption
三、Image caption with copying mechanism
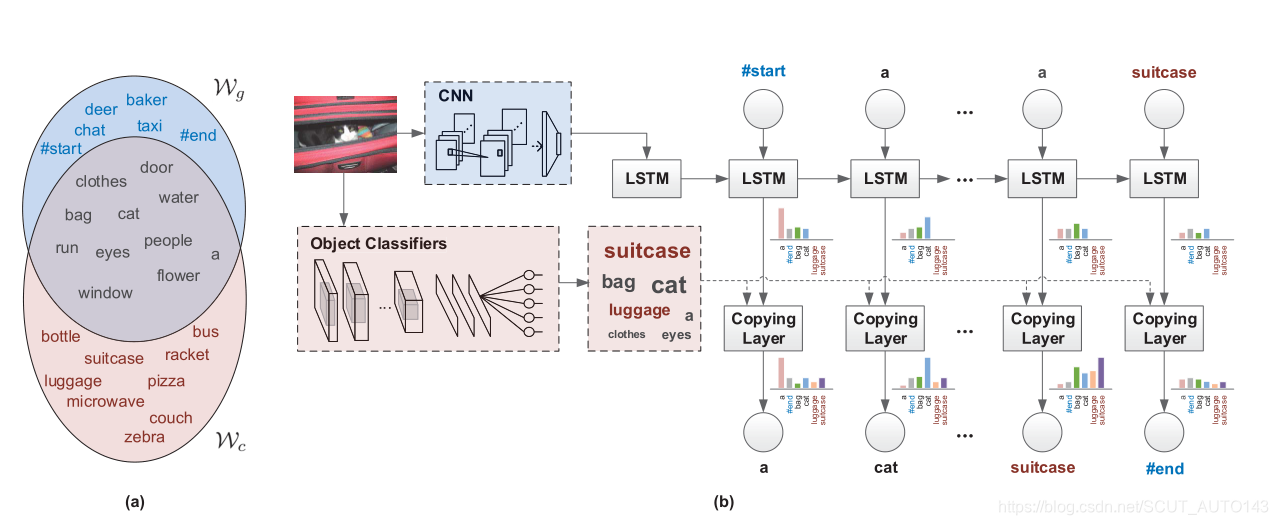
上图(b)展示了LSTM-C结构,(a)中代表paired image-sentences中出现的词汇,
代表unpaired objects组成的词汇
3.1 Notaion
image特征,textual sentence
,其中每一个
,输出还可以表示成
的矩阵,理解成
个
的列向量构成。
3.2 Sequence Modeling in Image Caption
这一部分跟show ant tell模型提出的language model一样,是一个典型的不带attention机制的Sequence-to-sequence模型,论文用表示下一时刻单词的出现概率,计算公式为
3.3 Copying Mechanism
Copying Mechanism主要用来解决out-of-vocabulary的问题。copying mechanism作用是将检测到的objects对应的word复制到输出sentence中,类似于人类的rote memorization,简单点说就是记住输入的sentence部分单词,然后直接放入输出sentence中。
计算公式为
其中,是单词
对应的物体在image中检测到概率的score,换句话说,检测到object概率越大,那么对应的score越大,对应单词出现概率就越大,跟
一样,
也是计算单词跟LSTM隐状态
的相似程度。不过具体的变换矩阵不一样。
3.4 LSTM with Copying Mechanism
根据3.2、3.3提到的方法,输出单词的计算公式有两个,根据其vocabulary集合属性,归纳出所有单词的计算公式,
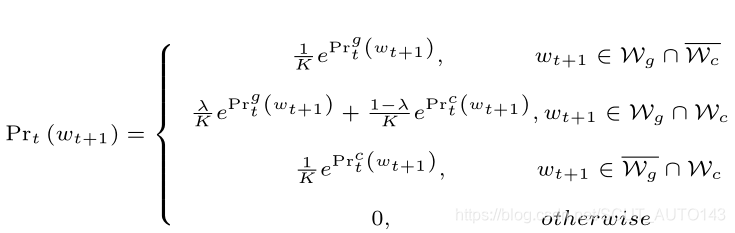
其中,这里给出的是最后的softmax归一化的形式。重点关注既在又在
中的单词,它们的计算公式结合了3.2、3.3的公式,其中,
是平衡参数。
根据计算公式,得到对数似然损失函数,计算公式为
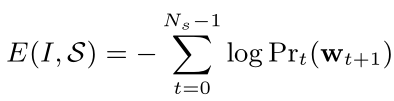
论文最终得到一个优化问题
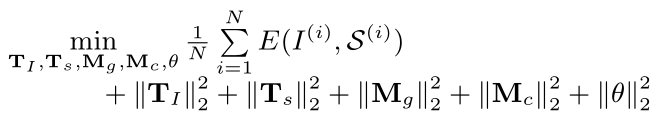
这里有一个疑问,按照论文的说法,训练LSTM-C的时候采用的是paired image-sentence数据,那么所有的单词就不存在只属于的情况,也就是说3.3提到的公式在训练整个LSTM-C的时候完全没有用,只在测试的时候起作用?

















 2339
2339

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









