







 本文介绍了一种新的图像描述生成方法,解决了现有模型难以处理新颖场景和领域外图片的问题。通过引入pointing机制,该方法能够在生成描述时灵活地引用识别到的新颖物体,同时提出LSTM-P模型,结合sequence loss和sentence-level coverage loss,显著提高了描述的准确性和全面性。
本文介绍了一种新的图像描述生成方法,解决了现有模型难以处理新颖场景和领域外图片的问题。通过引入pointing机制,该方法能够在生成描述时灵活地引用识别到的新颖物体,同时提出LSTM-P模型,结合sequence loss和sentence-level coverage loss,显著提高了描述的准确性和全面性。
Point Novel Objects in Image Captioning
时间:2019 CVPR
本文与guide object那篇可做对比
Intro
本文要解决的问题是novel object captioning的问题
当前的image captioning模型各方面表现都已不错,但最大的问题是,它通常建立在image-caption对上,导致了仅仅能够捕捉领域内的目标,且无法拓展到现实中很多novel scene和out-of-domain的图片上
为了生成novel objects,需要面临两个困难:
- 如何促进词汇拓展
- 如何学习网络,使得能够很好的融入识别到的目标到caption中
我们通过利用识别数据集的信息来缓和第一个问题,然后使用了pointing机制来平衡decoder生成词或者从识别的词上直接进行拷贝,因为image captioning模型通常会在训练集中学习到过多的先验,从而导致幻视,因此我们将考虑coverage of object来在句子中覆盖更多的objects来提高模型表现,我们提出了一个LSTM-P模型来解决上述问题
Approach
LSTM-P模型将识别的novel objects动态地融入到输出的句子中,通过一个pointing机制。模型总体如图所示
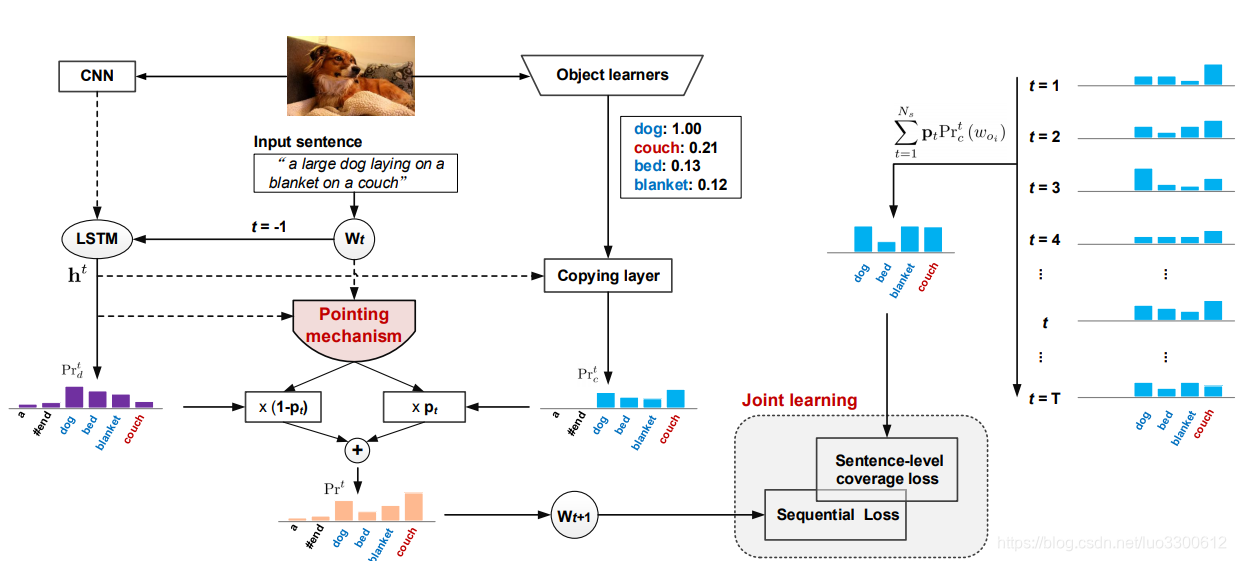
模型首先用一个CNN+RNN来利用生成词的上下文关系,同时object learners在目标识别数据集上进行训练,以备后续的直接拷贝识别的目标词的操作。然后,两个pathway,一个是word-by-word的生成方法,一个是直接拷贝词,通过pointing机制结合,pointing机制将给出何时需要生成、何时需要拷贝,整个模型在最小化序列误差和sentence-level coverage loss,
Notation
sentence S = { w 1 , w 2 , . . . , w N s } S=\{w_1,w_2,...,w_{N_s}\} S={w1,w2,...,wNs},图片 I I I被编码为 I ∈ R D v \mathbf{I}\in R^{D_v} I∈RDv维向量, w t ∈ R D w \mathbf{w}_t\in R^{D_w} wt∈RDw是word embedding,记 W d W_d Wd为image-caption对上的词汇集,目标识别中的object vocabulary为 W c W_c Wc, I c ∈ R D c \mathbf{I}_c\in R^{D_c} Ic∈RDc为 W c W_c Wc中 D c D_c Dc个目标的概率分布,因此整个的词汇表为 W = W d ∪ W c W=W_d\cup W_c W=Wd∪Wc,为了度量生成句子中对object的覆盖程度,我们将句子中的object提炼出来作为另一个目标,每个句子有一个bag-of-objects
Problem Formulation
novel object captioning的目标有两个,生成的流畅的句子,和生成的句子包括所有object,因此损失函数为
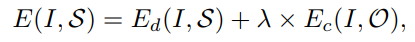
E
d
E_d
Ed和
E
c
E_c
Ec分别是sequential loss和sentence-level coverage loss
Pointing Mechanism
pointing mechanism就是在传统caption生成和模型加上一个拷贝层以及一个pointing behavior,具体的,在decoding阶段,LSTM输出
h
t
h_t
ht,然后在
W
W
W和
W
c
W_c
Wc上的分布首先被计算出来,在
W
W
W上的概率计算为
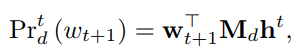
其中
M
d
M_d
Md是embedding矩阵,在
W
c
W_c
Wc上的分布为
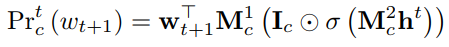
其中
I
c
I_c
Ic是object learner的输出,然后pointing mechanism决定是否copy
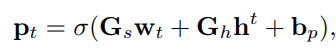
最终的词分布概率为(soft guide)
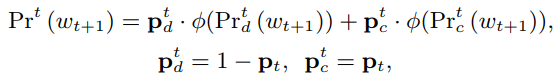
Coverage of Objects
问题实际上是多标签分类问题,
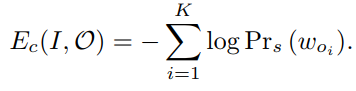
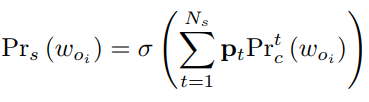
Optimization
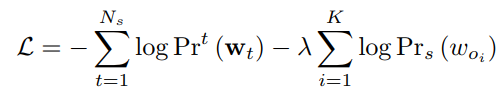
Experiments

Conclusion
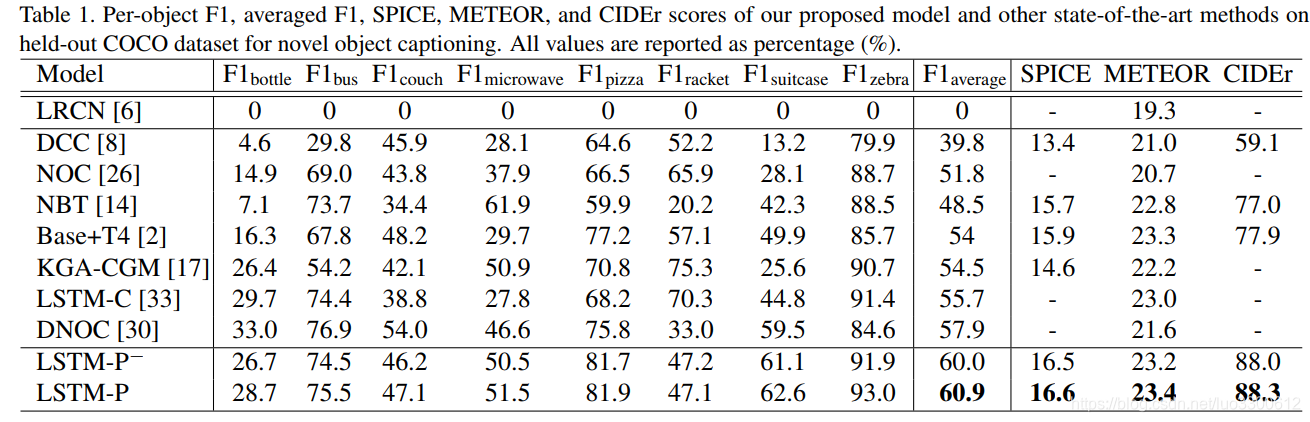
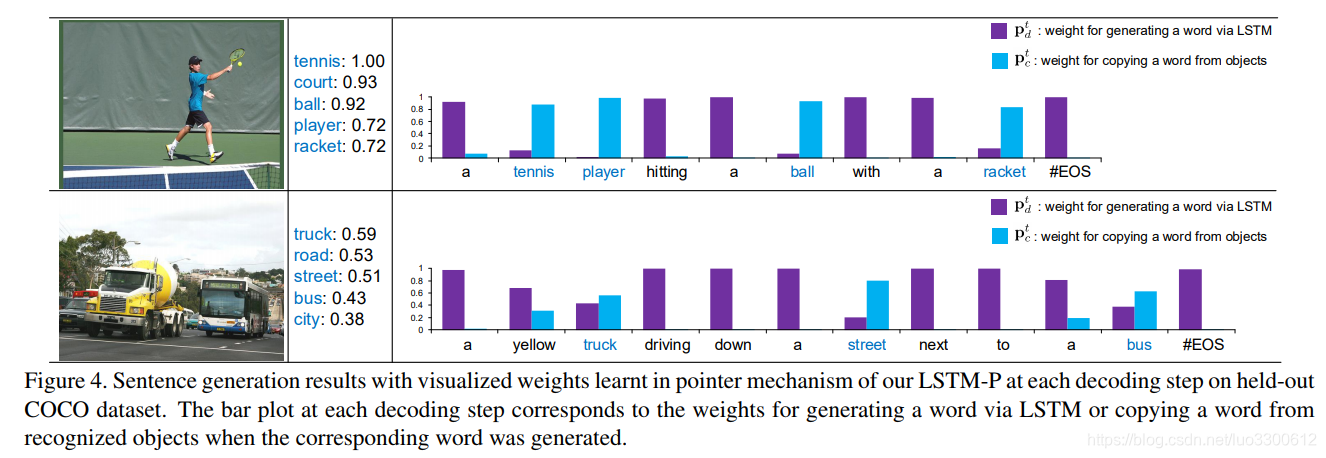
本文通过引入pointing mechanism解决novel Image caption的问题,具体的做法是通过soft的方式,在copy和generate之间进行选择,引入sentence-level coverage loss来强制句子包含更多的object,在COCO上达到了SoTA的F1 60.9%

















 1780
1780

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









