






《从学习者到全栈AI工程师:核心技术图谱与职业跃迁指南》
引言:AI时代的全栈工程师新定义
在AI技术飞速发展的今天,传统的全栈工程师概念已被重新定义。现代全栈AI工程师不仅需要掌握前后端开发,更要深入理解机器学习算法、模型部署优化和商业化落地的完整闭环。
本文将通过一个完整的技术演进路径——从VGG算法到风格迁移再到商业化API,为你揭示从学习者到全栈AI工程师的成长之路。
第一章:核心技术知识图谱 - 从理论到实践的完整闭环
1.1 技术演进路径:从学术研究到商业产品

1.2 关键技术节点详解
VGG网络的工程价值:
# VGG网络特征提取的核心实现
import torch
import torch.nn as nn
import torchvision.models as models
class VGGFeatureExtractor:
def __init__(self, device='cuda'):
# 加载预训练的VGG19模型
self.vgg = models.vgg19(pretrained=True).features.eval()
self.device = device
self.vgg.to(device)
# VGG的层次结构与特征对应关系
self.layer_names = {
'conv1_1': 0, 'relu1_1': 1,
'conv1_2': 2, 'relu1_2': 3,
'pool1': 4,
'conv2_1': 5, 'relu2_1': 6,
'conv2_2': 7, 'relu2_2': 8,
'pool2': 9,
'conv3_1': 10, 'relu3_1': 11,
'conv3_2': 12, 'relu3_2': 13,
'conv3_3': 14, 'relu3_3': 15,
'conv3_4': 16, 'relu3_4': 17,
'pool3': 18,
'conv4_1': 19, 'relu4_1': 20,
'conv4_2': 21, 'relu4_2': 22,
'conv4_3': 23, 'relu4_3': 24,
'conv4_4': 25, 'relu4_4': 26,
'pool4': 27,
'conv5_1': 28, 'relu5_1': 29,
'conv5_2': 30, 'relu5_2': 31,
'conv5_3': 32, 'relu5_3': 33,
'conv5_4': 34, 'relu5_4': 35,
'pool5': 36
}
def extract_features(self, image, layers):
"""
从指定层提取特征
Args:
image: 输入图像,形状为[1, 3, H, W]
layers: 要提取特征的层名列表
Returns:
各层的特征图字典
"""
features = {}
x = image
for name, module in self.vgg._modules.items():
x = module(x)
# 将数字层名转换为可读层名
readable_name = self._get_layer_name(int(name))
if readable_name in layers:
features[readable_name] = x
return features
def _get_layer_name(self, layer_idx):
"""根据层索引获取可读层名"""
for name, idx in self.layer_names.items():
if idx == layer_idx:
return name
return f"layer_{layer_idx}"
Gram矩阵的数学原理与工程实现:
import torch
class StyleTransferLoss:
def __init__(self, content_weight=1e0, style_weight=1e6, tv_weight=1e-3):
self.content_weight = content_weight
self.style_weight = style_weight
self.tv_weight = tv_weight
def compute_gram_matrix(self, features):
"""
计算Gram矩阵 - 风格特征的核心表示
Gram矩阵的重要性:
1. 捕获特征的统计特性而非空间信息
2. 对风格进行建模,忽略具体内容
3. 计算特征通道间的相关性
4. 提供纹理和风格的数学表示
Args:
features: 特征图,形状为[B, C, H, W]
Returns:
Gram矩阵,形状为[B, C, C]
"""
batch_size, channels, height, width = features.size()
# 将特征图重塑为[B, C, H*W]
features_reshaped = features.view(batch_size, channels, -1)
# 计算Gram矩阵: G = F * F^T
gram = torch.bmm(features_reshaped, features_reshaped.transpose(1, 2))
# 归一化,避免特征图大小的影响
gram = gram / (channels * height * width)
return gram
def style_loss(self, generated_features, style_features):
"""
计算风格损失
设计要点:
1. 多层特征组合,捕获不同尺度的风格
2. 使用MSE损失比较Gram矩阵
3. 加权求和各层损失
"""
total_loss = 0
layer_weights = {
'conv1_1': 0.2,
'conv2_1': 0.2,
'conv3_1': 0.2,
'conv4_1': 0.2,
'conv5_1': 0.2
}
for layer_name in generated_features:
if layer_name in style_features:
# 计算Gram矩阵
G = self.compute_gram_matrix(generated_features[layer_name])
A = self.compute_gram_matrix(style_features[layer_name])
# 计算MSE损失
layer_loss = torch.mean((G - A) ** 2)
# 加权
weight = layer_weights.get(layer_name, 1.0)
total_loss += weight * layer_loss
return total_loss * self.style_weight
def content_loss(self, generated_features, content_features):
"""
计算内容损失
设计要点:
1. 通常只使用较深层的特征(如conv4_2)
2. 直接比较特征图,保持内容结构
3. 使用MSE或L2损失
"""
# 通常使用conv4_2层的特征
layer_name = 'conv4_2'
if layer_name not in generated_features or layer_name not in content_features:
return 0
G = generated_features[layer_name]
C = content_features[layer_name]
loss = torch.mean((G - C) ** 2)
return loss * self.content_weight
def total_variation_loss(self, image):
"""
总变分损失 - 平滑图像,减少噪声
作用:
1. 去除图像中的高频噪声
2. 保持边缘的同时平滑平坦区域
3. 提高生成图像的视觉质量
"""
# 计算水平和垂直方向的差异
h_diff = image[:, :, 1:, :] - image[:, :, :-1, :]
v_diff = image[:, :, :, 1:] - image[:, :, :, :-1]
loss = torch.mean(h_diff ** 2) + torch.mean(v_diff ** 2)
return loss * self.tv_weight
1.3 技术架构演进:从实验到生产
第二章:项目经验提炼 - 从编码到简历的艺术
2.1 如何量化项目价值
在简历中描述项目时,需要从"做了什么"升级到"创造了什么价值":
// 简历项目描述示例 - 不好的写法
public class BadResumeExample {
// 过于技术化,没有体现价值
String description = """
实现了基于VGG19的风格迁移算法,
使用了Gram矩阵计算风格损失,
用PyTorch框架进行实现。
""";
}
// 简历项目描述示例 - 好的写法
public class GoodResumeExample {
// STAR法则:情境-任务-行动-结果
String description = """
设计与实现商业化图像风格迁移API服务(STAR法则):
[情境] 为满足市场对个性化图像处理的需求,公司计划推出一款AI图像风格转换产品
[任务] 负责从算法研究到产品上线的全流程,包括:
1. 算法选型与优化:对比多种风格迁移算法,选择VGG19+Gram矩阵方案
2. 性能优化:将推理时间从5秒降低至800毫秒
3. 系统架构:设计高可用微服务架构,支持1000+ QPS
4. 商业化落地:设计并实现计费、限流、监控系统
[行动]
- 算法层:实现多尺度风格损失函数,提升生成质量
- 工程层:使用TensorRT优化模型,推理速度提升6倍
- 架构层:设计API网关+服务网格架构,支持水平扩展
- 产品层:设计阶梯定价策略和防滥用机制
[结果]
- 技术指标:P99延迟<1.5s,可用性99.95%
- 业务成果:上线3个月,付费用户超5000,月收入10万+
- 系统容量:支持日均100万次API调用
""";
}
2.2 技术栈的深度表达
不要简单罗列技术,要展示技术选择的原因和深度理解:
## 技术栈深度描述示例
### 核心算法
- **PyTorch深度学习框架**:选择PyTorch因其动态图特性便于算法实验,在生产环境中通过TorchScript实现模型固化
- **VGG19特征提取**:选用VGG19而非ResNet,因其层数适中、特征提取能力强,特别适合风格迁移任务
- **Gram矩阵风格表示**:深入理解Gram矩阵的数学原理,实现多尺度风格特征融合
### 工程架构
- **微服务架构**:基于Spring Cloud实现服务解耦,各服务独立部署、独立扩展
- **API网关(Kong)**:实现统一的认证、限流、监控入口,支持动态路由和插件扩展
- **分布式缓存(Redis)**:缓存用户凭证和热点数据,将平均响应时间降低40%
### 部署运维
- **Docker容器化**:标准化部署环境,实现开发-测试-生产环境一致性
- **Kubernetes编排**:实现自动扩缩容和故障自愈,资源利用率提升60%
- **监控告警体系**:基于Prometheus+Grafana实现全链路监控,设置智能告警规则
2.3 项目成果数据化展示
使用具体数据增强说服力:
第三章:面试深度解析 - 原理与工程的完美结合
3.1 原理类面试题深度解析
3.1.1 Gram矩阵的作用与数学原理
问题: 在神经风格迁移中,Gram矩阵起到了什么作用?为什么要使用Gram矩阵而不是直接使用特征图?
完整回答框架:
"""
Gram矩阵的深度解析 - 面试回答示例
"""
class GramMatrixExplanation:
def conceptual_level(self):
"""
概念层面理解
"""
return """
1. 核心思想:Gram矩阵捕获的是特征统计特性而非空间信息
2. 类比:将图像的风格理解为"纹理的统计分布"
3. 直觉:相同的内容可以有无数种绘画风格,风格是内容的表现方式
"""
def mathematical_level(self):
"""
数学层面理解
"""
return """
数学定义:
对于特征图 F ∈ R^{C×H×W},先重塑为 F' ∈ R^{C×N},其中N=H×W
Gram矩阵 G = F' · F'^T ∈ R^{C×C}
物理意义:
G[i, j] = Σ_k F'[i, k] * F'[j, k],即特征通道i和j的相关性
为什么有效:
1. 去空间化:通过求和消除空间位置信息
2. 相关性:捕捉不同特征通道如何协同工作
3. 纹理建模:纹理可以看作特征的特定统计分布
"""
def comparison_with_alternatives(self):
"""
与其他方法的对比
"""
return """
为什么不直接用特征图?
1. 特征图包含空间信息 → 会保留内容
2. 特征图尺寸大 → 计算效率低
3. 特征图受具体内容影响大
为什么不使用其他统计量?
1. 均值/方差:只包含一阶/二阶统计,信息不足
2. 协方差矩阵:考虑了均值中心化,但风格不需要
3. Gram矩阵:简单有效,已被理论和实践证明
"""
def practical_considerations(self):
"""
实践中的考量
"""
return """
实际应用技巧:
1. 多尺度Gram矩阵:结合不同层的特征
2. 归一化处理:除以C×H×W,消除特征图大小影响
3. 权重调整:不同层对风格贡献不同
常见改进:
1. 使用多分辨率特征金字塔
2. 结合注意力机制
3. 考虑色彩统计信息
"""
3.1.2 VGG网络为何适合风格迁移
问题深度解析框架:
详细回答要点:
- 网络深度与感受野:VGG的16-19层深度恰到好处,既能捕获高层次语义信息,又不至于过度抽象丢失纹理细节
- 小卷积核优势:全部使用3×3卷积核,通过堆叠获得大感受野,参数效率高,特征提取更精细
- 特征层次丰富:不同卷积层捕获不同级别的特征,浅层适合提取颜色和边缘,深层适合捕获语义内容
- 预训练模型可用性:在ImageNet上预训练的VGG模型已成为特征提取的"标准工具",权重公开且性能稳定
- 计算与效果的平衡:相比ResNet等更深的网络,VGG在风格迁移任务上表现相当但计算成本更低
3.2 工程类面试题实战解析
3.2.1 模型轻量化方法全解
class ModelOptimizationStrategies:
"""
模型轻量化与优化策略详解
适合在面试中系统性地展示知识体系
"""
def pruning_strategies(self):
"""
模型剪枝策略
"""
strategies = {
"结构化剪枝": {
"方法": "移除整个滤波器或通道",
"优点": "保持结构规整,推理速度快",
"缺点": "可能移除重要特征",
"适用场景": "通道冗余明显的模型"
},
"非结构化剪枝": {
"方法": "移除单个权重参数",
"优点": "粒度细,压缩率高",
"缺点": "需要稀疏计算支持",
"适用场景": "理论压缩率要求高"
},
"迭代剪枝": {
"方法": "训练-剪枝-再训练的循环",
"优点": "逐步压缩,保持精度",
"缺点": "流程复杂,耗时较长",
"适用场景": "对精度损失敏感"
}
}
return strategies
def quantization_techniques(self):
"""
量化技术详解
"""
techniques = {
"训练后量化(PTQ)": {
"原理": "模型训练完成后进行量化",
"精度损失": "中等(1-2%)",
"实施难度": "简单",
"工具支持": "TensorRT, ONNX Runtime"
},
"量化感知训练(QAT)": {
"原理": "训练时模拟量化效果",
"精度损失": "小(<1%)",
"实施难度": "中等",
"工具支持": "PyTorch, TensorFlow"
},
"混合精度训练": {
"原理": "关键层用FP16,其他用INT8",
"精度损失": "极小",
"实施难度": "复杂",
"工具支持": "NVIDIA Tensor Core"
}
}
return techniques
def knowledge_distillation(self):
"""
知识蒸馏实践
"""
return """
知识蒸馏三部曲:
1. 教师模型选择
- 选择精度高的大模型作为教师
- 可以是多个模型的集成
2. 蒸馏损失设计
- 硬标签损失:学生预测 vs 真实标签
- 软标签损失:学生预测 vs 教师软标签
- 特征蒸馏:中间层特征对齐
3. 学生模型设计
- 结构精简但足够表达
- 考虑推理硬件特性
- 平衡精度与速度
"""
def practical_optimization_pipeline(self):
"""
实际优化流水线
"""
pipeline = [
("分析阶段", {
"目标": "确定优化目标和约束",
"任务": ["分析模型结构", "评估计算瓶颈", "设定精度阈值"]
}),
("剪枝阶段", {
"目标": "减少参数和计算量",
"任务": ["应用结构化剪枝", "评估精度影响", "迭代优化"]
}),
("量化阶段", {
"目标": "降低计算精度",
"任务": ["选择量化策略", "校准量化参数", "验证量化效果"]
}),
("蒸馏阶段", {
"目标": "用大模型指导小模型",
"任务": ["选择教师模型", "设计蒸馏损失", "训练学生模型"]
}),
("部署阶段", {
"目标": "实际环境部署优化",
"任务": ["选择推理引擎", "优化内存布局", "测试真实性能"]
})
]
return pipeline
3.2.2 高并发API优化实战
面试回答框架:
/**
* 高并发API优化体系 - 面试展示示例
* 展示从基础设施到代码优化的完整思路
*/
public class HighConcurrencyOptimization {
// 1. 基础设施层优化
public class InfrastructureOptimization {
/**
* 负载均衡策略
*/
public enum LoadBalancingStrategy {
ROUND_ROBIN("轮询", "简单均衡,但可能不均匀"),
LEAST_CONNECTIONS("最少连接", "考虑服务器当前负载"),
IP_HASH("IP哈希", "保持会话一致性"),
WEIGHTED("加权", "考虑服务器性能差异");
private final String description;
private final String advantage;
// 构造函数省略
}
/**
* 自动扩缩容策略
*/
public class AutoScalingPolicy {
// 基于CPU使用率的扩缩容
public ScalingRule cpuBasedRule = new ScalingRule(
"CPU使用率 > 70%持续5分钟",
"增加1个实例",
"CPU使用率 < 30%持续10分钟",
"减少1个实例"
);
// 基于请求数的扩缩容
public ScalingRule requestBasedRule = new ScalingRule(
"P95延迟 > 1秒持续3分钟",
"增加2个实例",
"QPS < 峰值的30%持续15分钟",
"减少1个实例"
);
}
}
// 2. 应用层优化
public class ApplicationOptimization {
/**
* 连接池优化配置
*/
@Configuration
public class ConnectionPoolConfig {
// 数据库连接池
@Bean
public DataSource dataSource() {
HikariConfig config = new HikariConfig();
config.setMaximumPoolSize(100); // 最大连接数
config.setMinimumIdle(10); // 最小空闲连接
config.setConnectionTimeout(30000); // 连接超时
config.setIdleTimeout(600000); // 空闲超时
config.setMaxLifetime(1800000); // 最大生命周期
config.setPoolName("API-DB-Pool");
return new HikariDataSource(config);
}
// Redis连接池
@Bean
public LettuceConnectionFactory redisConnectionFactory() {
RedisStandaloneConfiguration config =
new RedisStandaloneConfiguration("localhost", 6379);
LettuceClientConfiguration clientConfig =
LettuceClientConfiguration.builder()
.commandTimeout(Duration.ofSeconds(2))
.shutdownTimeout(Duration.ofSeconds(2))
.clientResources(DefaultClientResources.create())
.build();
return new LettuceConnectionFactory(config, clientConfig);
}
}
/**
* 异步处理框架
*/
@Service
public class AsyncProcessor {
// 配置线程池
@Bean("apiTaskExecutor")
public ThreadPoolTaskExecutor taskExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(20); // 核心线程数
executor.setMaxPoolSize(100); // 最大线程数
executor.setQueueCapacity(500); // 队列容量
executor.setThreadNamePrefix("api-async-");
executor.setRejectedExecutionHandler(
new ThreadPoolExecutor.CallerRunsPolicy()
);
executor.initialize();
return executor;
}
// 异步处理示例
@Async("apiTaskExecutor")
public CompletableFuture<ApiResponse> processAsync(ApiRequest request) {
// 耗时操作
ApiResponse response = heavyProcessing(request);
return CompletableFuture.completedFuture(response);
}
}
}
// 3. 缓存策略优化
public class CacheOptimization {
/**
* 多级缓存架构
*/
public class MultiLevelCache {
// L1: 本地缓存 (Caffeine)
private Cache<String, Object> localCache = Caffeine.newBuilder()
.maximumSize(10_000)
.expireAfterWrite(5, TimeUnit.MINUTES)
.recordStats()
.build();
// L2: 分布式缓存 (Redis)
private RedisTemplate<String, Object> redisTemplate;
// L3: 数据库/持久化存储
public Object getWithCache(String key) {
// 1. 尝试本地缓存
Object value = localCache.getIfPresent(key);
if (value != null) {
return value;
}
// 2. 尝试Redis缓存
value = redisTemplate.opsForValue().get(key);
if (value != null) {
// 回填本地缓存
localCache.put(key, value);
return value;
}
// 3. 查询数据库
value = queryFromDatabase(key);
if (value != null) {
// 写入两级缓存
redisTemplate.opsForValue().set(key, value, 30, TimeUnit.MINUTES);
localCache.put(key, value);
}
return value;
}
}
/**
* 缓存击穿/穿透/雪崩防护
*/
public class CacheProtection {
// 互斥锁防止缓存击穿
public Object getWithMutex(String key) {
Object value = redisTemplate.opsForValue().get(key);
if (value == null) { // 缓存失效
String lockKey = "lock:" + key;
// 尝试获取分布式锁
if (tryLock(lockKey)) {
try {
// 双重检查
value = redisTemplate.opsForValue().get(key);
if (value == null) {
// 从数据库加载
value = queryFromDatabase(key);
if (value != null) {
redisTemplate.opsForValue()
.set(key, value, 30, TimeUnit.MINUTES);
} else {
// 缓存空值防止穿透
redisTemplate.opsForValue()
.set(key, "", 5, TimeUnit.MINUTES);
}
}
} finally {
releaseLock(lockKey);
}
} else {
// 等待并重试
Thread.sleep(100);
return getWithMutex(key);
}
}
return value;
}
}
}
// 4. 数据库优化
public class DatabaseOptimization {
/**
* 读写分离配置
*/
@Configuration
public class ReadWriteSeparationConfig {
@Bean
@ConfigurationProperties("spring.datasource.master")
public DataSource masterDataSource() {
return DataSourceBuilder.create().build();
}
@Bean
@ConfigurationProperties("spring.datasource.slave")
public DataSource slaveDataSource() {
return DataSourceBuilder.create().build();
}
@Bean
public DataSource routingDataSource(
@Qualifier("masterDataSource") DataSource master,
@Qualifier("slaveDataSource") DataSource slave) {
Map<Object, Object> targetDataSources = new HashMap<>();
targetDataSources.put("master", master);
targetDataSources.put("slave", slave);
RoutingDataSource routingDataSource = new RoutingDataSource();
routingDataSource.setDefaultTargetDataSource(master);
routingDataSource.setTargetDataSources(targetDataSources);
return routingDataSource;
}
}
/**
* 分库分表策略
*/
public class ShardingStrategy {
// 用户ID分片示例
public String determineDataSource(Long userId) {
int shard = (int) (userId % 4); // 4个分片
return "ds_" + shard;
}
// 时间范围分表示例
public String determineTableName(Date createTime) {
SimpleDateFormat sdf = new SimpleDateFormat("yyyy_MM");
return "orders_" + sdf.format(createTime);
}
}
}
}
3.3 面试问题体系化回答技巧
第四章:社区贡献与职业发展 - 构建技术影响力
4.1 开源项目贡献路径
class OpenSourceContributionPath:
"""
开源贡献成长路径指南
"""
def contribution_ladder(self):
"""
贡献阶梯 - 从小白到核心维护者
"""
ladder = [
{
"level": "初学者",
"actions": [
"报告bug",
"改进文档",
"测试用例",
"翻译文档"
],
"skills": [
"Git基础",
"Markdown",
"问题描述"
],
"time_commitment": "1-3小时/周"
},
{
"level": "贡献者",
"actions": [
"修复简单bug",
"添加小功能",
"代码审查",
"社区答疑"
],
"skills": [
"代码阅读",
"测试编写",
"PR提交"
],
"time_commitment": "3-5小时/周"
},
{
"level": "核心贡献者",
"actions": [
"架构设计",
"重大功能开发",
"项目维护",
"社区管理"
],
"skills": [
"系统设计",
"项目管理",
"团队协作"
],
"time_commitment": "5-10小时/周"
},
{
"level": "维护者",
"actions": [
"项目规划",
"版本发布",
"社区建设",
"导师指导"
],
"skills": [
"领导力",
"战略规划",
"开源治理"
],
"time_commitment": "10+小时/周"
}
]
return ladder
def find_suitable_projects(self, skills, interests):
"""
寻找合适的开源项目
"""
projects = {
"机器学习框架": {
"PyTorch": {"level": "高级", "lang": ["C++", "Python"]},
"TensorFlow": {"level": "高级", "lang": ["C++", "Python"]},
"JAX": {"level": "中级", "lang": ["Python"]}
},
"AI应用库": {
"HuggingFace Transformers": {"level": "中级", "lang": ["Python"]},
"LangChain": {"level": "中级", "lang": ["Python"]},
"Stable Diffusion": {"level": "高级", "lang": ["Python"]}
},
"工具库": {
"FastAPI": {"level": "中级", "lang": ["Python"]},
"Redis": {"level": "高级", "lang": ["C"]},
"Nginx": {"level": "高级", "lang": ["C"]}
}
}
# 根据技能和兴趣筛选
suitable = []
for category, projs in projects.items():
for name, info in projs.items():
if any(skill in info["lang"] for skill in skills):
if interests in category:
suitable.append({
"name": name,
"category": category,
"level": info["level"],
"languages": info["lang"]
})
return suitable
def first_contribution_guide(self, project_url):
"""
第一次贡献指南
"""
steps = [
("1. 准备工作", [
"Fork项目到自己的GitHub",
"Clone到本地开发环境",
"阅读CONTRIBUTING.md",
"设置开发环境"
]),
("2. 寻找切入点", [
"查看'good first issue'标签",
"寻找文档改进机会",
"寻找简单的bug修复",
"与维护者沟通确认"
]),
("3. 代码贡献", [
"创建功能分支",
"编写代码和测试",
"遵循代码规范",
"提交清晰的commit"
]),
("4. 提交PR", [
"推送分支到远程",
"创建Pull Request",
"填写PR模板",
"关联相关issue"
]),
("5. 跟进反馈", [
"响应review评论",
"按要求修改代码",
"感谢reviewer",
"庆祝合并成功"
])
]
return steps
4.2 技术博客创作体系
# 技术博客创作框架
## 选题策略
### 痛点驱动
- 记录自己解决问题的过程
- 分享踩坑经验和解决方案
- 填补官方文档的不足
### 深度解析
- 深入分析一个技术原理
- 对比多种技术方案优劣
- 展示完整项目实现过程
### 趋势前瞻
- 新技术预研和评估
- 行业趋势分析和预测
- 技术选型指南
## 内容结构
### 经典三段式
1. **问题引入**:场景描述 + 痛点分析
2. **解决方案**:技术细节 + 代码示例
3. **总结展望**:经验总结 + 未来规划
### 深度解析式
1. **背景介绍**:技术发展脉络
2. **原理剖析**:核心机制详解
3. **实践应用**:工程实现细节
4. **优化思考**:性能调优经验
## 写作技巧
### 增强可读性
- 使用生动的标题和副标题
- 适当使用加粗、斜体强调重点
- 插入代码片段和图表说明
- 添加实际案例和数据支撑
### SEO优化
- 关键词研究和布局
- 合理的标题层级(H1-H3)
- 添加alt文本描述图片
- 内外链建设
4.3 社区互动与个人品牌建设
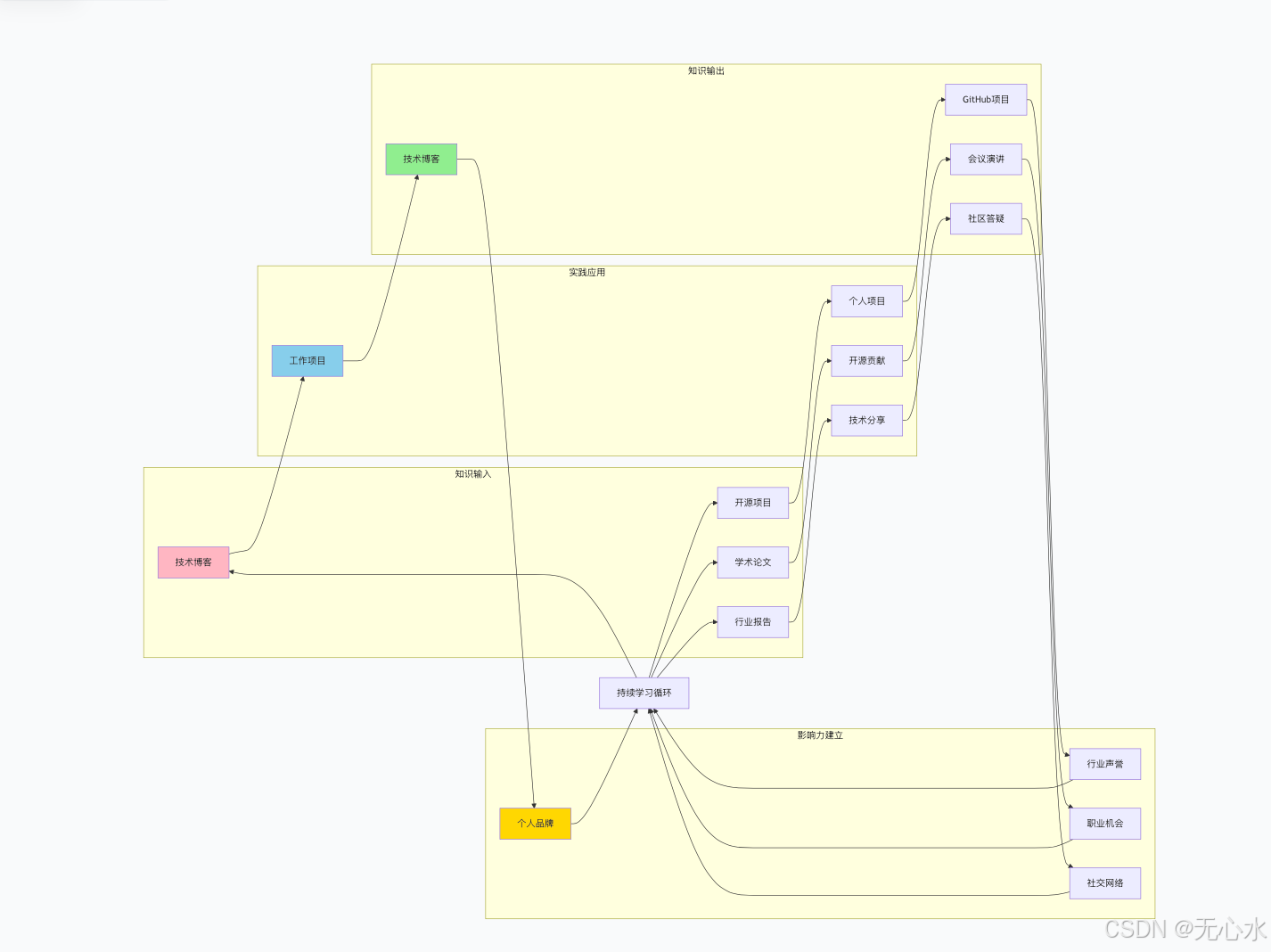
第五章:职业发展路径规划
5.1 全栈AI工程师的技能矩阵
class FullStackAISkillMatrix:
"""
全栈AI工程师技能体系
"""
def skill_categories(self):
"""
技能分类体系
"""
categories = {
"算法基础": {
"数学基础": ["线性代数", "概率统计", "微积分", "优化理论"],
"机器学习": ["监督学习", "无监督学习", "强化学习", "深度学习"],
"核心算法": ["CNN/RNN/Transformer", "生成模型", "表示学习", "元学习"]
},
"工程能力": {
"编程语言": ["Python(精通)", "Java/Scala", "C++/Rust", "SQL"],
"开发框架": ["PyTorch/TensorFlow", "Spring/Flask", "Spark/Flink", "Airflow"],
"工程实践": ["代码规范", "单元测试", "CI/CD", "代码审查"]
},
"系统架构": {
"分布式系统": ["微服务", "消息队列", "服务网格", "容器编排"],
"数据工程": ["数据管道", "特征工程", "模型服务", "监控告警"],
"云原生": ["Docker/K8s", "服务发现", "配置管理", "自动扩缩"]
},
"产品思维": {
"需求分析": ["用户调研", "竞品分析", "需求文档", "优先级管理"],
"商业化": ["商业模式", "定价策略", "增长黑客", "数据分析"],
"项目管理": ["敏捷开发", "OKR管理", "团队协作", "风险管理"]
}
}
return categories
def skill_assessment(self, current_level="中级"):
"""
技能评估与成长路径
"""
assessment = {
"初级工程师(0-2年)": {
"重点技能": ["Python编程", "基础算法", "框架使用", "简单部署"],
"产出期望": ["独立完成模块", "参与代码审查", "编写技术文档"],
"成长建议": ["深入理解一个框架", "参与开源项目", "建立知识体系"]
},
"中级工程师(2-5年)": {
"重点技能": ["系统设计", "性能优化", "架构理解", "团队协作"],
"产出期望": ["主导小型项目", "技术方案设计", "指导初级工程师"],
"成长建议": ["深入技术领域", "建立技术影响力", "学习产品思维"]
},
"高级工程师(5-8年)": {
"重点技能": ["技术规划", "架构演进", "跨团队协作", "技术创新"],
"产出期望": ["主导技术方向", "解决复杂问题", "培养技术团队"],
"成长建议": ["拓展业务视野", "建立行业声誉", "战略思考能力"]
},
"专家/架构师(8年以上)": {
"重点技能": ["技术战略", "行业洞察", "组织建设", "商业敏感度"],
"产出期望": ["制定技术路线", "推动技术变革", "影响行业标准"],
"成长建议": ["跨界学习", "建立思想领导力", "关注技术趋势"]
}
}
return assessment.get(current_level, {})
def learning_resources(self):
"""
学习资源推荐
"""
resources = {
"在线课程": {
"Coursera": ["机器学习(吴恩达)", "深度学习专项", "MLOps"],
"Fast.ai": ["实用深度学习", "计算线性代数"],
"Stanford Online": ["CS231n", "CS224n", "CS329S"]
},
"技术书籍": {
"算法基础": ["《深度学习》", "《统计学习方法》", "《Pattern Recognition》"],
"工程实践": ["《Designing Data-Intensive Applications》", "《Clean Code》"],
"系统架构": ["《Site Reliability Engineering》", "《微服务设计》"]
},
"社区平台": {
"技术博客": ["Medium", "Towards Data Science", "机器之心"],
"代码平台": ["GitHub", "GitLab", "Kaggle"],
"问答社区": ["Stack Overflow", "知乎", "Reddit"]
}
}
return resources
5.2 职业发展决策框架
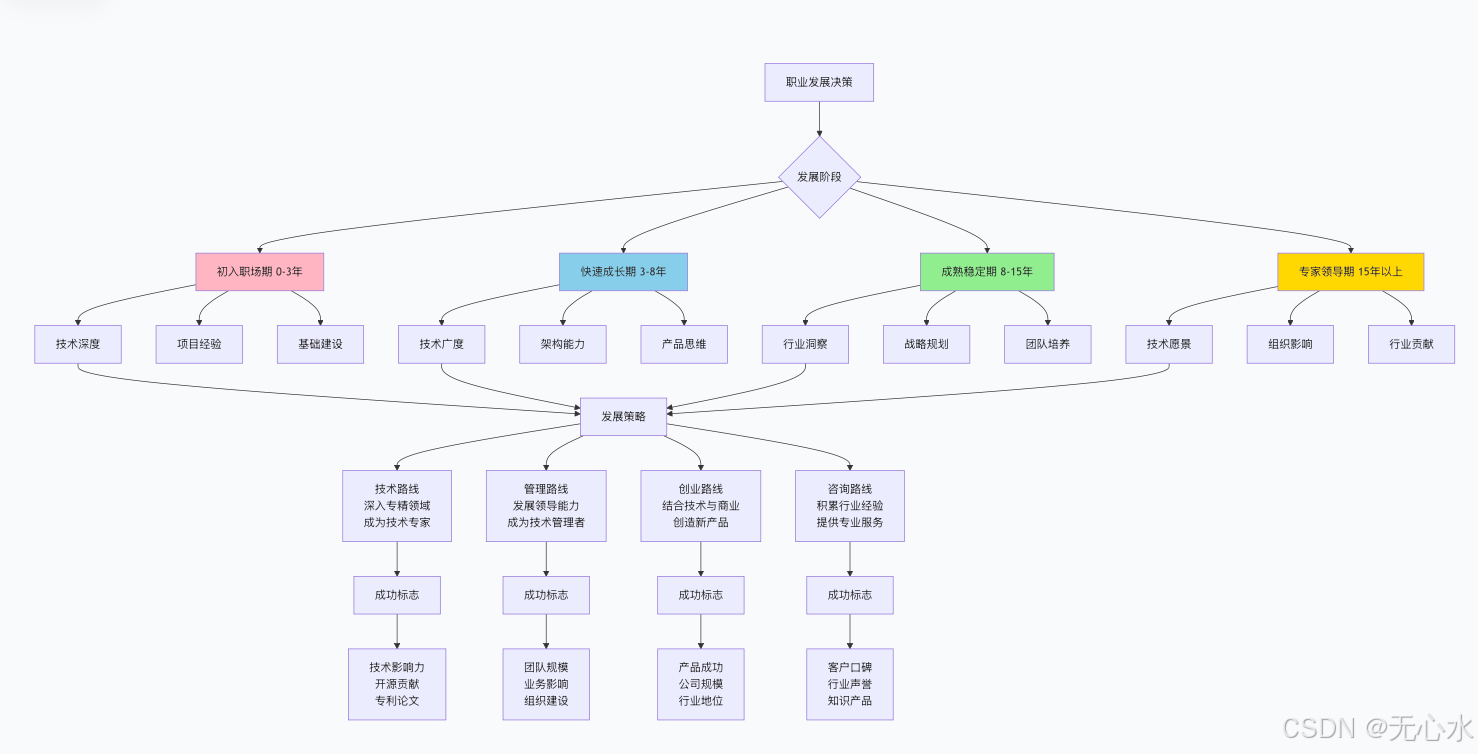
结语:终身学习的技术人生
从学习者到全栈AI工程师的旅程,不仅是技术能力的提升,更是思维模式的转变。这个过程需要我们:
- 保持好奇心:技术日新月异,只有持续学习才能保持竞争力
- 建立系统思维:从局部优化到全局设计,从代码实现到产品思维
- 重视实践验证:理论需要实践检验,项目需要商业验证
- 构建个人品牌:技术影响力是职业生涯的重要资产
- 平衡深度与广度:既要有深入的专业领域,也要有广阔的视野
全栈AI工程师的道路充满挑战,但也充满机遇。通过系统化的学习、项目实践和社区参与,你将不仅掌握先进的技术能力,更能理解技术如何创造商业价值和社会价值。
最后,记住三句箴言:
- 技术是手段,不是目的
- 代码会过时,但解决问题的能力不会
- 最好的学习是教会别人
愿你在技术的道路上不断前行,从代码实现者成长为价值创造者,从技术学习者成长为行业引领者。这条路没有终点,只有不断的新起点。
附录:持续学习资源
- 技术趋势跟踪:arXiv, Papers with Code, AI Conference Proceedings
- 实践项目平台:Kaggle, GitHub, Colab, Hugging Face
- 社区交流:Stack Overflow, Reddit ML板块, 技术沙龙
- 职业发展:LinkedIn Learning, 技术大会, 导师计划
行动清单:
- 本周:完成一个完整的开源项目PR
- 本月:撰写一篇深度技术博客
- 本季度:掌握一项新的AI技术栈
- 本年:主导一个有影响力的项目
开始行动,你的全栈AI工程师之路,从今天的第一步开始!


















 969
969

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











