






2025程序员AI学习全景图:从Java/Python到AI架构师的完整进阶路线
一份涵盖产业布局、技术路线、职业规划三位一体的AI转型指南
引言:AI浪潮下的程序员机遇与挑战
2025年,AI技术已深度融入软件开发的全生命周期。Gartner报告显示,超过70%的企业将在核心业务中集成AI能力,这意味着不懂AI的程序员正在快速失去职场竞争力。
作为深耕Java+AI+Python领域多年的技术专家,我见证了太多程序员陷入"学AI不知从何下手"的困境。本文融合多份优质技术指南,为你呈现一份完整的AI学习全景图,涵盖:
- AI产业布局分析:看清产业链结构,找准学习方向
- Java+Python双轨进阶路线:5阶段系统化成长路径
- 职业发展规划:从初级开发到AI架构师的转型路径
- 实战项目与避坑指南:高效学习,少走弯路
无论你是Java后端、Python开发者还是全栈工程师,这份指南都将帮助你构建AI时代的核心竞争力。
一、AI产业布局全景分析:找准学习方向的底层逻辑
1.1 AI产业链完整拆解
AI产业分为上游基础层、中游技术层、下游应用层,每个环节的技术需求差异显著:
1.2 Java+Python在AI产业中的核心定位
AI产业并非"Python独大",Java和Python各司其职、互补共生:
- Python:AI算法研发、模型训练、轻量化推理的核心语言,优势是生态丰富(PyTorch/TensorFlow/LangChain),是"AI实验室"的核心工具
- Java:AI应用工程化、高并发部署、企业级系统集成的核心语言,优势是稳定性、生态成熟(Spring Boot/微服务/分布式),是"AI落地到生产环境"的核心工具
- 核心竞争力:同时懂Java+Python,能把AI模型从实验室(Python)落地到企业生产环境(Java),是当前市场最稀缺的复合型能力
二、程序员AI学习进阶路线:从0到1系统化成长
基于AI产业链需求,我设计了一套适配程序员的五阶段进阶路线,兼顾"技术深度"和"落地能力":
2.1 阶段一:L1启航篇(0-3个月)—— 极速破界AI新时代
核心目标:建立AI全局认知,掌握基础工具链,实现第一个AI应用
(1)Python AI原生语法速成
- 环境搭建:Conda环境管理、Poetry依赖管理
- 核心库:NumPy向量运算、Pandas数据处理、Matplotlib可视化
- 异步编程:async/await处理大量AI API调用
- 学习重点:不是死记语法,而是能高效处理数据、写模块化的代码
(2)AI数学基础精要
- 线性代数:矩阵运算、向量空间(3天集中攻克)
- 概率统计:条件概率、贝叶斯定理、最大似然估计
- 微积分:梯度下降法的直观理解
- 学习技巧:不必深究数学证明,重点理解几何直观和编程实现
(3)大模型核心原理
根据我的实践建议,重点理解:
- Transformer架构:自注意力机制、位置编码、多头注意力
- Tokenization:BPE、WordPiece分词原理
- 模型参数:175B参数的含义,模型容量与智能涌现
- 训练过程:预训练、指令微调、RLHF人类反馈强化学习
(4)入门实战项目
Mini项目:企业智能问答机器人
- 使用Python调用OpenAI API或文心一言API
- 基于Spring Boot快速搭建RESTful服务
- 实现基础的对话记忆功能
- 技术栈:Python 3.11 + Spring Boot 3.2 + LangChain4j
// Java端调用示例
@RestController
public class ChatController {
@Autowired
private ChatClient chatClient;
@PostMapping("/chat")
public String chat(@RequestBody ChatRequest request) {
return chatClient.call(request.getMessage());
}
}
2.2 阶段二:L2攻坚篇(3-6个月)—— RAG开发实战工坊
核心目标:掌握检索增强生成技术,构建私有知识库系统
(1)文档处理流水线
- 多格式解析:PDF(PyPDF2)、Word(python-docx)、HTML(BeautifulSoup)
- 智能分块:基于语义的Chunk分割策略,避免截断重要信息
- 元数据提取:保留文档结构、作者、时间等上下文信息
(2)向量化技术深度解析
- Embedding模型选择:text-embedding-3-small vs bge-large-zh
- 向量维度:1536维、1024维的存储成本与检索效率权衡
- 批量处理:使用Spring AI的EmbeddingClient实现高性能转换
// Java端向量化示例
@Bean
CommandLineRunner run(EmbeddingClient embeddingClient) {
return args -> {
List<String> knowledgeTexts = List.of(
"Spring AI支持向量存储集成:Milvus、Chroma、Redis Vector",
"PromptTemplate支持Freemarker语法动态渲染"
);
List<float[]> embeddings = embeddingClient.embedAll(knowledgeTexts);
System.out.println("向量维度:" + embeddings.get(0).length);
};
}
(3)向量数据库选型与实战
| 数据库 | 特点 | Java支持 | Python支持 | 适用场景 |
|---|---|---|---|---|
| Milvus | 分布式、高性能 | ✅ Spring AI集成 | ✅ LangChain集成 | 亿级向量检索 |
| Chroma | 轻量级、本地优先 | ✅ 原生支持 | ✅ 首选 | 快速原型开发 |
| Pinecone | 全托管、Serverless | ✅ REST API | ✅ 官方SDK | 生产级SaaS应用 |
| Redis Stack | 混合存储 | ✅ Redisson | ✅ redis-py | 缓存+向量混合 |
(4)阶段产出项目
实战项目:研发文档智能助手
- 支持PDF/Word文档批量上传
- 实现基于语义的精准检索(召回率>85%)
- 提供答案溯源功能(高亮原文段落)
- 技术栈:Python(FastAPI+LangChain)+ Java(Spring AI)+ Milvus
2.3 阶段三:L3跃迁篇(6-9个月)—— Agent智能体架构设计
核心目标:构建具备工具调用能力的AI智能体,实现复杂任务自动化
(1)Agent架构模式
- ReAct:Reasoning-Acting循环,边思考边行动
- Plan-and-Execute:先规划后执行,适合确定性任务
- BabyAGI:动态任务生成与优先级调度
- 多Agent协作:MetaGPT的"软件开发团队"模拟
(2)工具调用机制
- Function Calling:OpenAI Functions与Spring AI的集成
- 工具描述协议:如何让LLM理解工具入参与出参
- 错误处理:工具调用失败的重试与降级策略
- 权限控制:敏感工具(如删除数据库)的二次确认机制
// Spring AI Function Calling示例
@Bean
public FunctionCallingOptions functionCallingOptions() {
return FunctionCallingOptions.builder()
.withFunction("get_current_weather", """
{
"name": "get_current_weather",
"description": "获取当前天气",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "城市名称"
}
}
}
}
""")
.build();
}
(3)Memory系统设计
- 短期记忆:ConversationBufferWindow的记忆窗口管理
- 长期记忆:基于向量数据库的对话历史存储
- 实体记忆:提取对话中的关键实体(人名、地名、配置项)
- 摘要记忆:对长对话进行滚动摘要
(4)阶段产出项目
实战项目:智能运维助手OpsAgent
- 集成Kubernetes API、Jenkins、Prometheus等工具
- 实现"分析日志→定位问题→执行修复→验证结果"全流程自动化
- 支持自然语言指令:“查看prod环境错误率最高的服务并重启”
- 技术栈:Java(Spring AI+LangChain4j)+ Python(Tool集合)+ gRPC通信
2.4 阶段四:L4精进篇(9-12个月)—— 模型微调与私有化部署
核心目标:掌握领域模型微调技术,实现AI能力的企业级私有化
(1)微调技术选型
- 全参数微调:使用Llama Factory、Axolotl等框架
- LoRA微调:低秩适配器,学习率设置技巧(1e-4到5e-4)
- QLoRA:4-bit量化 + LoRA,消费级显卡可跑65B模型
- 领域适配:法律、医疗、金融等垂直领域的数据准备原则
(2)训练数据工程
- 数据清洗:去除低质量、重复、敏感数据
- 指令构造:Alpaca格式、ShareGPT格式的优劣对比
- 数据增强:使用LLM生成多样化指令(Self-Instruct)
- 质量评估:人工抽样 + 自动评分(perplexity、ROUGE)
(3)私有化部署技术栈
| 部署框架 | Java集成 | 性能特点 | 适用规模 |
|---|---|---|---|
| Ollama | ✅ HTTP调用 | 单机、易用 | 1000次/日以下 |
| vLLM | ✅ gRPC调用 | 高吞吐、低延迟 | 百万级请求 |
| TensorRT-LLM | ✅ JNI调用 | 极致性能 | GPU集群 |
| OpenLLM | ✅ Java SDK | 多模型管理 | 中大规模 |
(4)推理优化
- 量化技术:GPTQ、AWQ的后训练量化
- KV Cache优化:PagedAttention减少显存碎片
- 动态批处理:Continuous Batching提升吞吐量
- 服务监控:Prometheus + Grafana监控首Token延迟、吞吐量
(5)阶段产出项目
实战项目:Java领域代码生成专家模型
- 基于CodeLlama-13B,使用10万条优质Java代码微调
- 实现"自然语言需求→生产级Java代码"生成
- 部署为内部服务,集成到IDE插件
- 技术栈:LoRA微调 + vLLM部署 + Spring AI统一接口
2.5 阶段五:L5专题篇(12个月+)—— 多模态与前沿探索
核心目标:融合文本、图像、语音等多模态能力,探索Agentic AI新范式
(1)多模态大模型
- 视觉理解:CLIP、LLaVA、Qwen-VL的架构原理
- 语音集成:Whisper语音识别 + CosyVoice语音合成
- 视频分析:Video-LLaMA的时空注意力机制
- 统一接口:Spring AI多模态支持(图像生成、语音合成)
(2)Agentic AI新范式
- 自治Agent:AutoGPT、BabyAGI的自我驱动机制
- 人机协作:Copilot模式的上下文感知与主动建议
- 群体智能:多Agent模拟社会协作
- 安全对齐:Constitutional AI、RLHF的进阶应用
(3)企业级AI治理
- 成本控制:API调用成本分析与优化(缓存、批处理)
- 质量监控:回答准确率、幻觉率的自动化评估
- 合规审计:GDPR、中国生成式AI备案的数据处理要求
- 可解释性:LLM决策链路的可视化与归因分析
(4)阶段产出项目
实战项目:多模态智能合同审查系统
- 支持PDF合同文本分析 + 公章识别 + 手写签名验证
- 集成法务知识库(RAG)+ 风险规则引擎
- 技术栈:Java(Spring AI)+ Python(多模态模型)+ Milvus + 图数据库
三、AI产业布局与机会分析
3.1 2025年AI产业全景图
3.2 头部企业AI布局分析
3.3 企业级AI应用场景分析
根据Java企业技术趋势,当前主流应用场景集中在:
| 应用场景 | Java技术栈 | Python技术栈 | 核心价值 | 技术难点 |
|---|---|---|---|---|
| 智能客服 | Spring AI + WebFlux | Rasa/LlamaIndex | 7×24小时服务 成本降低60% | 多轮对话管理 情感识别 |
| 代码生成 | JBoltAI插件 | CodeT5/CodeLlama | 开发效率提升50% | 代码安全性 上下文理解 |
| 文档审查 | LangChain4j | PyMuPDF + RAG | 准确率95% 耗时从小时到分钟 | 表格结构保留 跨文档推理 |
| 智能运维 | Spring AI Agents | Prometheus + LLM | MTTR降低80% | 工具调用安全 故障根因分析 |
| 推荐系统 | DJL + Kafka | TensorFlow Recommenders | 点击率提升20% | 实时特征工程 冷启动问题 |
| 风控合规 | Drools + LLM | 图神经网络 | 风险识别覆盖率99% | 可解释性 监管合规 |
四、AI程序员职业发展规划
4.1 岗位能力模型全景图
4.2 薪资与岗位分布(2025年数据)
| 岗位名称 | 技术栈要求 | 1-3年薪资 | 3-5年薪资 | 5年+薪资 | 岗位稀缺度 |
|---|---|---|---|---|---|
| AI应用工程师 | Python+API调用 | 20-30K | 30-45K | 50K+ | ⭐⭐ |
| Java AI开发 | Spring AI+LangChain4j | 25-35K | 35-50K | 60K+ | ⭐⭐⭐⭐ |
| 大模型算法工程师 | PyTorch+Transformer | 30-40K | 45-65K | 80K+ | ⭐⭐⭐ |
| AI架构师 | 全栈+分布式系统 | - | 50-70K | 100K+ | ⭐⭐⭐⭐⭐ |
| Agent开发专家 | 多智能体+强化学习 | 35-45K | 50-70K | 90K+ | ⭐⭐⭐⭐⭐ |
| AI产品经理 | 技术理解+业务洞察 | 25-35K | 35-50K | 60K+ | ⭐⭐⭐ |
数据分析:
- Java+AI复合型人才溢价最高,比纯Python岗位薪资高20-30%
- Agent开发和AI架构师是2025年最紧缺岗位,猎头高薪挖角
- 模型微调能力是从应用层到核心层的关键跃迁
4.3 Java/Python开发者转型路径
(1)纯Java程序员转型路径(核心优势:工程化/高并发)
- 第一步(0-3个月):补Python核心(数据处理、基础语法)+ AI数学基础
- 第二步(3-6个月):学习AI工程化落地(模型封装、REST API、Docker)
- 第三步(6-12个月):学习大模型应用与跨语言集成(Py4J/gRPC),成为AI开发工程师
- 第四步(12个月+):深耕行业,向大模型应用架构师/AI架构师发展
- 核心策略:发挥Java的工程化优势,重点补Python和AI基础,聚焦"AI落地"
(2)纯Python程序员转型路径(核心优势:算法/数据处理)
- 第一步(0-3个月):补AI数学基础+经典机器学习算法
- 第二步(3-6个月):学习深度学习+框架实战(PyTorch/TensorFlow)
- 第三步(6-12个月):补Java基础+工程化落地(Docker/K8s),掌握跨语言集成
- 第四步(12个月+):向数据科学家/AI架构师发展
- 核心策略:发挥Python的算法优势,重点补工程化和Java基础,避免只做"调包侠"
4.4 5年职业发展路线图
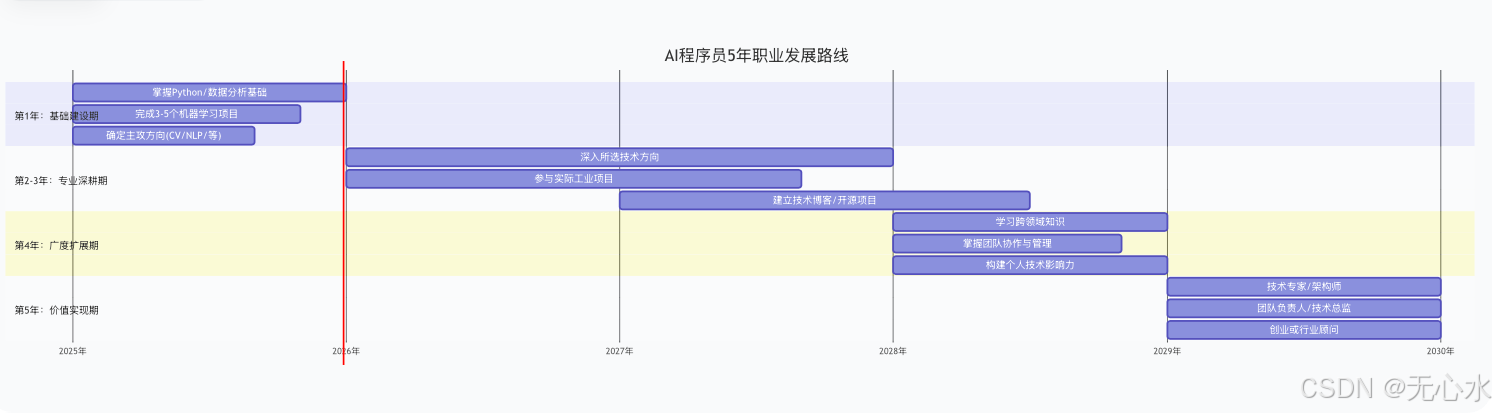
五、实战项目深度解析
5.1 项目一:企业级智能客服系统
架构设计
关键技术实现
- 流量削峰与成本控制:使用Spring AI的速率限制器,设置每分钟100次调用限制
- 多模型路由策略:基于问题复杂度动态选择模型(简单问题用本地模型,复杂问题用GPT-4)
- 性能优化:首Token延迟从3s优化到800ms,RAG检索采用Milvus HNSW索引优化
项目成果
- 上线效果:替代60%人工客服,成本降低200万/年
- 技术指标:平均响应时间1.2s,用户满意度4.7/5.0
- 扩展性:支持10万+QPS,通过Kubernetes弹性伸缩
5.2 项目二:智能代码审查平台
架构设计
核心技术实现
- 代码表示学习:将Java语法树转换为LLM可理解的文本描述
- 渐进式审查:L1基础语法检查(<1s)→ L2模式匹配(<3s)→ L3 AI深度分析(<10s)
- 审查Prompt工程:设计资深Java架构师角色,输出结构化审查结果
项目成果
- 准确率:Bug检出率85%,误报率<15%
- 效率:单次审查时间从人工30分钟缩短到5分钟
- 知识沉淀:累计生成10万+审查案例,用于持续微调模型
六、学习资源与避坑指南
6.1 分阶段学习资源包
| 学习阶段 | 核心资源 | 实战平台 | 项目建议 |
|---|---|---|---|
| L1启航篇 | 吴恩达《AI For Everyone》 李宏毅《生成式AI导论》 | Hugging Face Spaces OpenAI Playground | 智能对话机器人 简单分类任务 |
| L2攻坚篇 | LangChain官方文档 《Building LLM-powered Applications》 | Kaggle RAG竞赛 阿里天池知识库项目 | 企业知识库系统 文档智能助手 |
| L3跃迁篇 | DeepLearning.AI《AI Agent》课程 AutoGPT源码阅读 | LangChain Agents示例 Spring AI官方Sample | 智能运维助手 多工具调用Agent |
| L4精进篇 | Hugging Face《Fine-tuning Course》 LLaMA-Factory文档 | 本地GPU微调实践 云平台模型部署 | 领域模型微调 私有化部署服务 |
| L5专题篇 | CLIP论文精读 LLaVA微调教程 | 多模态项目实践 前沿论文复现 | 多模态合同审查 AI治理平台 |
6.2 100天行动计划
第1-30天:基础攻坚
- 目标:Python熟练 + AI数学通关 + 第一个API应用
- 每日投入:4小时(2小时编码 + 1小时理论 + 1小时实践)
- 周任务:
- Week 1:Python基础 + NumPy
- Week 2:Pandas数据处理 + 可视化
- Week 3:线性代数核心概念 + 梯度下降
- Week 4:调用GPT API + 构建简单对话机器人
第31-60天:RAG实战
- 目标:独立完成知识库系统
- 关键产出:GitHub项目(Star 50+)
- 技术点:LangChain/LangChain4j + Milvus + 文档解析
第61-90天:Agent进阶
- 目标:掌握工具调用,开发智能助手
- 关键产出:技术博客3篇(掘金/优快云阅读量1万+)
- 技术点:ReAct模式 + Spring AI Functions + 多Agent协作
第91-100天:项目整合
- 目标:一个端到端的AI应用
- 关键产出:部署到云服务器,提供公开访问链接
- 简历亮点:项目经历+技术博客+开源贡献三位一体
6.3 常见学习误区与解决方案
七、未来趋势与技术演进
7.1 2025-2027年技术趋势预测
趋势1:Java AI基础设施成熟化
- 虚拟线程普及:Project Loom彻底解决AI调用中的并发问题
- ZGC优化:<1ms停顿时间,满足实时AI推理需求
- Project Leyden:Java静态编译技术,AI应用启动时间缩短90%
- Vector API:SIMD指令加速Embedding计算,性能提升5-10倍
趋势2:多模态Agent成为主流
趋势3:AI工程化工具链完善
- LangSmith/Weights & Biases:成为AI应用开发标配
- AI Gateway:Kong/AWS API Gateway原生支持LLM路由
- 向量数据库Serverless:Pinecone/Milvus按查询付费,成本降低70%
- 低代码AI平台:OutSystems/Mendix集成AI能力,开发门槛大幅降低
7.2 技术挑战与应对策略
挑战1:大模型幻觉问题
- 解决方案:RAG增强 + 知识图谱 + 规则引擎三重校验
- Java实现:Spring AI的RetrievalAugmentationAdvisor + Drools规则
- 评估指标:回答准确率达到95%以上,幻觉率<3%
挑战2:成本控制
- 成本构成:API调用60% + 向量存储25% + GPU资源15%
- 优化策略:
- 问题分类路由(简单问题用低成本模型)
- 响应缓存(Redis缓存高频问题)
- 批量化处理(异步聚合请求)
- 模型压缩(从GPT-4降级到GPT-3.5-turbo)
挑战3:数据安全与合规
- 技术方案:私有化部署 + 数据脱敏 + 访问审计
- Java工具:Spring Security + Bouncy Castle加密 + OpenTelemetry审计日志
- 合规框架:GDPR数据地图、中国《生成式AI服务管理暂行办法》
结语:在AI时代构建你的技术护城河
2025年的程序员面临着职业生涯中最重要的技术变革。Java+AI+Python三位一体的技术栈不仅是一套技能组合,更是一种AI原生思维的体现——用Java的严谨构建可靠系统,用Python的灵活探索算法边界,用大模型的智能创造业务价值。
真正的护城河不在于你会用某个框架,而在于:
- 系统化能力:从数据→模型→应用→监控的全链路掌控
- 领域深度:在你的行业(金融/医疗/制造)打造不可替代的AI解决方案
- 工程智慧:在成本、性能、质量之间做出最优权衡
立即行动指南:
- 今天:确定学习目标和方向
- 本周:制定详细的学习计划
- 本月:完成第一个AI项目
- 本季度:建立系统的知识体系
- 今年:实现职业转型或升级
记住,AI不会取代程序员,但懂AI的程序员会取代不懂AI的程序员。愿你在这条路上,既能脚踏实地写代码,也能仰望星空探智能,最终成为AI时代的技术领导者。
版权声明:本文为原创文章,遵循CC 4.0 BY-SA协议,转载请注明出处。
互动讨论:
- 你目前处于AI学习的哪个阶段?
- 在AI学习过程中遇到的最大挑战是什么?
- 你最感兴趣的AI应用方向是哪个?
欢迎在评论区分享你的想法和经验!


















 1244
1244

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











