




 本文介绍了一种高效且易于实现的视觉变压器架构Twins,包括Twins-PCPVT和Twins-SVT。Twins通过引入空间可分离自注意机制解决传统transformer计算复杂度高的问题。该机制结合局部分组自注意和全局子采样注意,既能捕捉局部细节又能处理全局信息。
本文介绍了一种高效且易于实现的视觉变压器架构Twins,包括Twins-PCPVT和Twins-SVT。Twins通过引入空间可分离自注意机制解决传统transformer计算复杂度高的问题。该机制结合局部分组自注意和全局子采样注意,既能捕捉局部细节又能处理全局信息。
abstract
我们提出了两种视觉变压器架构,即Twins-PCPVT和TwinsSVT。我们提出的架构是高效的和易于实现的,
将transformers应用于视觉任务的主要问题之一是transformers的空间自注意操作的计算复杂度较大,其输入图像的像素数呈二次增长。
.这导致了我们提出的第一个架构,称为Twins-PCPVT。在此基础上,我们进一步提出了一种精心设计但简单的空间注意机制,使我们的架构比PVT更有效。
我们的注意机制是受到广泛使用的可分离深度卷积的启发,因此我们将其命名为空间可分离自注意(SSSA)。
我们提出的SSSA由两种类型的注意操作组成——(i)局部分组自注意(LSA)和(ii)全局子采样注意(GSA),其中LSA捕获细粒度和短距离信息,GSA处理长距离和全局信息。
3 Our Method: Twins
3.1 Twins-PCPVT
我们发现,PVT的性能较差,主要是由于在PVT中使用的绝对位置编码
如CPVT [9]所示,绝对位置编码在处理不同大小的输入时遇到了困难(这在密集预测任务中很常见)
我们使用CPVT [9]中提出的条件位置编码(CPE)来代替PVT中的绝对PE。
生成CPE的位置编码发生器(PEG)[9]被放置在每个阶段的第一个编码器块之后
我们也尝试用Swin中的CPE替换相对PE,但这并没有导致明显的性能提高,如我们的实验所示。我们推测,这可能是由于在Swin中使用了移位的窗口,这可能不能很好地使用CPE。
3.2 Twins-SVT
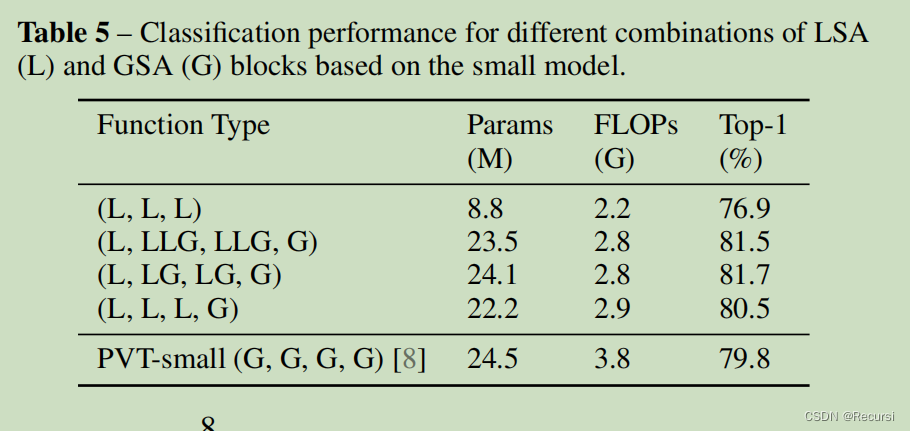
SSSA由局部分组的自我注意(LSA)和全局次抽样注意(GSA)组成
Locally-grouped self-attention (LSA).
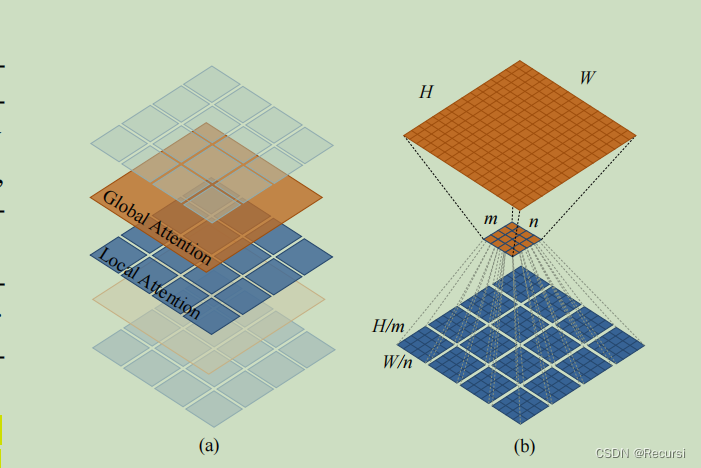

虽然局部分组的自注意机制是计算友好的,但图像被划分为不重叠的子窗口。因此,我们需要一种机制来实现不同子窗口之间的通信,否则,信息将被限制在局部处理,这使得接受域很小,并显著降低了性能,如我们的实验所示。这类似于我们不能用cnn中的深度卷积来替换所有的标准卷积。
Global sub-sampled attention (GSA).
一个简单的解决方案是在每个局部注意块之后添加额外的标准全局自注意层,这可以实现跨组信息交换。然而,这种方法将具有O(H2W2d)的计算复杂度。


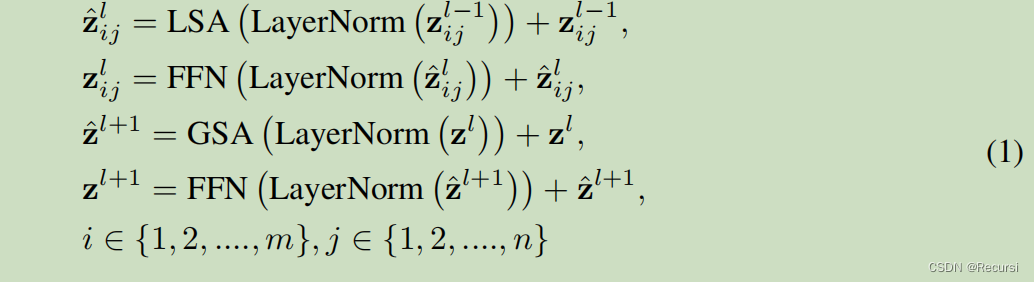
4 Experiments
4.1 Classifification on ImageNet-1K

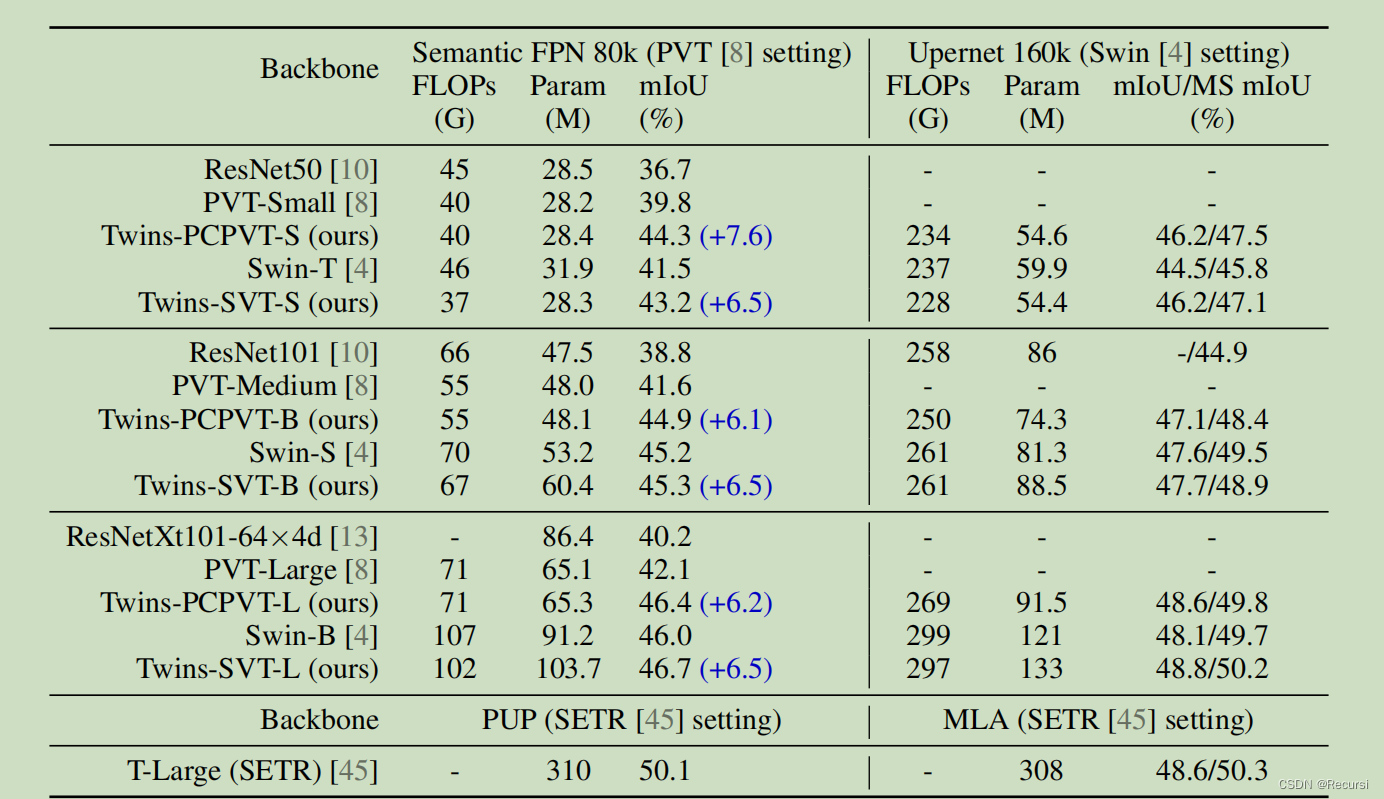
4.2 Semantic Segmentation on ADE20K
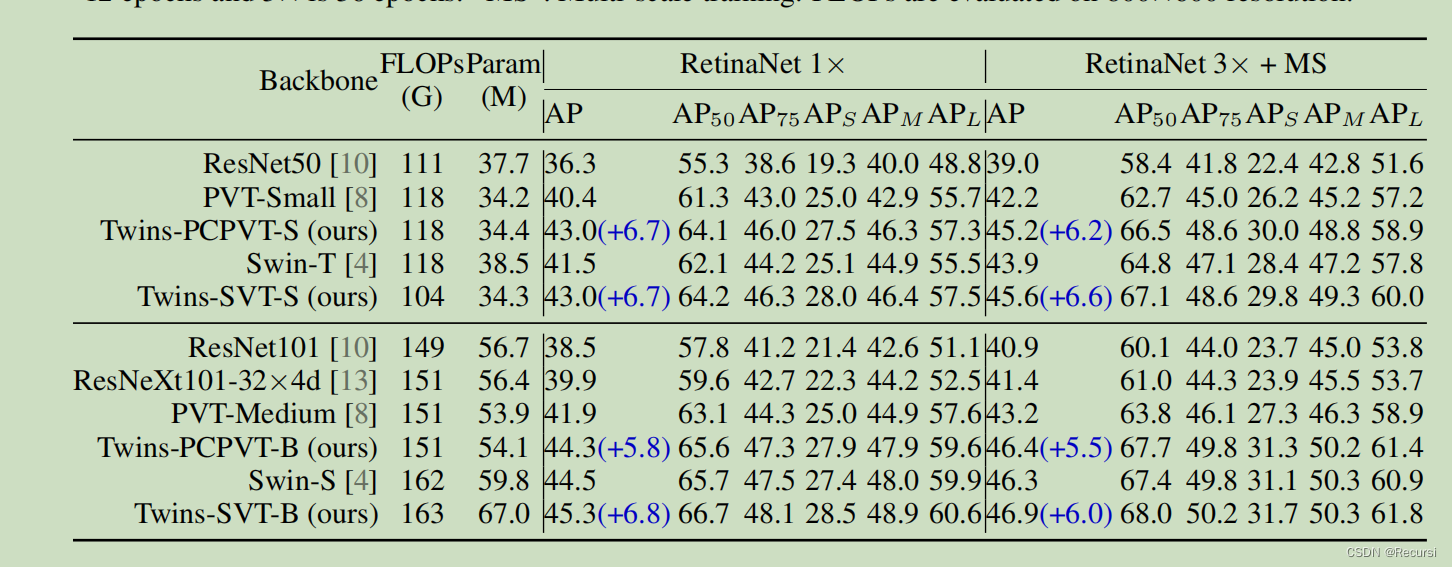
4.3 Object Detection and Segmentation on COCO
4.4 Ablation Studies
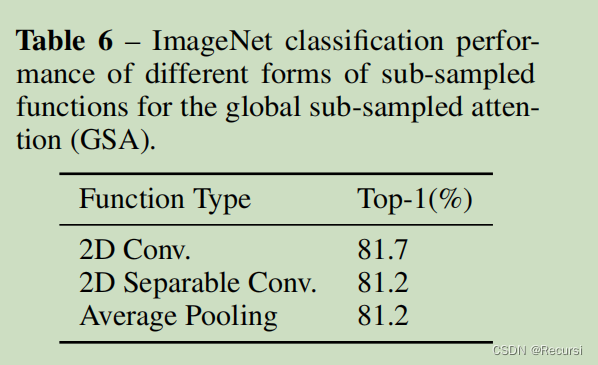
Sub-sampling functions.
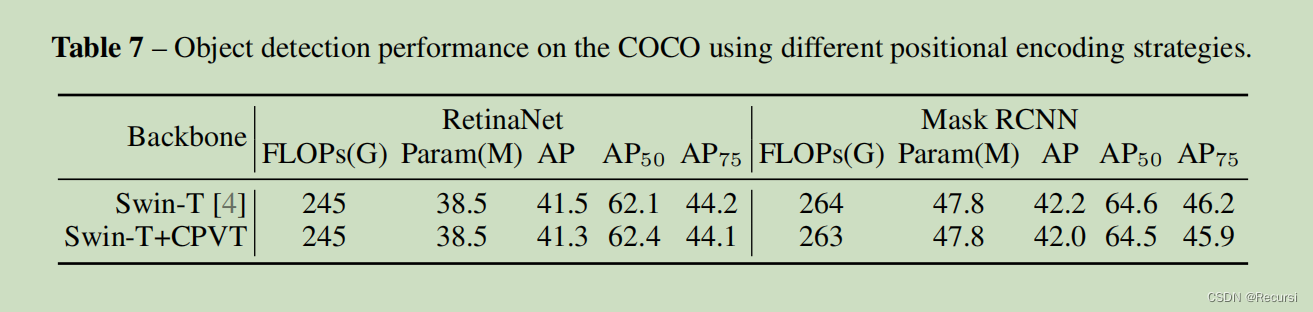
Positional Encodings


















 233
233

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









