




前言
SQLBI 网站上提供的《White paper: Understarnding DAX Query Plans》,发布于2013年7月17日,距今已近10年,随着DAX 版本不断更新优化,原文中关于查询计划的描述已不再符合当前实际情况。为充分理解、运用该文阐述的分析方法,以当前 DAX 版本运行文中案例,尝试理解查询计划及优化思路。
研究《DAX查询计划 白皮书》中的案例(一)初始方案
研究《DAX查询计划 白皮书》中的案例(二)优化方案1
研究《DAX查询计划 白皮书》中的案例(三)优化方案(番外)
研究《DAX查询计划 白皮书》中的案例(四)优化方案2
研究《DAX查询计划 白皮书》中的案例(四)优化方案3
运行环境
环境1:
CPU:i5-10500 @3.10GHz,L1:384 KB,L2:1.5MB,L3:12.0 MB
内存:16G
环境2:
CPU:i5-1135G7 @2.40GHz,L1:320 KB,L2:5.0 MB,L3:8.0 MB
内存:16G
模拟数据
案例文件:Sales.xlsb
数据表:
- Sales 表:记录有每笔订单的相关信息,共 121253 行,14 列。每行的订单唯一,主要用到的列是 [OrderDate](共 1081 个不重复值)、[ShipDate](共 1075 个不重复值)
- Calendar 表:根据 Sales[OrderDate]、Sales[ShipDate] 包含的日期范围生成的日期表,从 2017-7-1 到 2020-6-15,共 1081 行
Calendar =
var mind = min(min(Sales[OrderDate]), min(Sales[ShipDate]))
var maxd = max(max(Sales[OrderDate]), max(Sales[ShipDate]))
return
ADDCOLUMNS(
CALENDAR(mind,maxd),
"Year", YEAR([Date]),
"YM", Format([Date],"YYYY-MM")
)
表间关系:未建立关系
计算要求
给定日期 D,从 Sales 表中找出 [OrderDate] < D < [ShipDate] 的订单数量(被称为 Open Orders),由于 Sales 每行的订单是唯一的,即从 Sales 表中找出符合条件的数据行。
对 Calendar 日期表中的每一天,计算该日的 Open Orders 数量。
初始方案:
DAX 查询
// 初始方案
EVALUATE
ADDCOLUMNS (
VALUES ( 'Calendar'[Date] ),
"OpenOrders",
COUNTROWS (
FILTER (
Sales,
Sales[OrderDate] < 'Calendar'[Date] &&
Sales[ShipDate] > 'Calendar'[Date]
)
)
)
该方案采用了对题目最直接的理解转换而成的计算思路,在 DAX Studio 中运行,通过 Run Benchmark 功能测试运行效率,并在 QueryPlan 和 ServerTimings 中查看公式引擎和存储引擎的具体情况。
运行效率
以连续5次冷启动的结果进行统计:
- 环境1
平均总耗时 4389.4 毫秒,标准差 216.73 毫秒
其中 SE(存储引擎)平均耗时 14.4 毫秒,标准差 1.67 毫秒
SE/总耗时 = 0.328%
- 环境2
平均总耗时 4017.0 毫秒,标准差 41.90 毫秒
其中 SE(存储引擎)平均耗时 17.20 毫秒,标准差 2.17 毫秒
SE/总耗时 = 0.428%
两个环境下,存储引擎(SE)耗时占总时长的比例非常少,说明运行时主要时间都耗在公式引擎(FE)中,而且花费的时间太多了,稍后会分析是哪一步导致了该情况。
存储引擎部分(Storage Engine)
存储引擎执行了两个 xmSQL 查询,分别是
- VQ1: 从 Sales 表中按 [RowNumber]、[OrderDate]、[ShipDate] 分组
//VQ1
SELECT
'Sales'[RowNumber],
'Sales'[OrderDate],
'Sales'[ShipDate]
FROM 'Sales';
其中,[RowNumber] 是引擎自动给表添加的唯一标识列,由于 SELECT 部分包含有 [RowNumber],VQ1 将返回 Sales 全部 121253 行
- VQ2,从 Calendar 表中按 [Date] 分组
//VQ2
SELECT
'Calendar'[Date]
FROM 'Calendar';
从 Calendar 表中以 [Date] 列分组,共得到 1081 行数据。
公式引擎部分(Formula Engine)
公式引擎部分,有逻辑查询计划和物理查询计划,逻辑查询计划通常与原始 DAX 代码相近,物理查询计划则完全不同。
逻辑查询计划
查询计划如下(对 Line 的值做了缩进处理,方便看层级)
Line Logical Query Plan
1 AddColumns: RelLogOp DependOnCols()() 0-1 RequiredCols(0, 1)('Calendar'[Date], ''[OpenOrders])
2 Scan_Vertipaq: RelLogOp DependOnCols()() 0-0 RequiredCols(0)('Calendar'[Date])
3 CountRows: ScaLogOp DependOnCols(0)('Calendar'[Date]) Integer DominantValue=BLANK
4 Filter: RelLogOp DependOnCols(0)('Calendar'[Date]) 1-15 RequiredCols(0, 1, 6, 7)('Calendar'[Date], 'Sales'[RowNumber], 'Sales'[OrderDate], 'Sales'[ShipDate])
5 Filter: RelLogOp DependOnCols(0)('Calendar'[Date]) 1-15 RequiredCols(0, 1, 6, 7)('Calendar'[Date], 'Sales'[RowNumber], 'Sales'[OrderDate], 'Sales'[ShipDate])
6 Scan_Vertipaq: RelLogOp DependOnCols()() 1-15 RequiredCols(1, 6, 7)('Sales'[RowNumber], 'Sales'[OrderDate], 'Sales'[ShipDate])
7 LessThan: ScaLogOp DependOnCols(0, 6)('Calendar'[Date], 'Sales'[OrderDate]) Boolean DominantValue=NONE
8 'Sales'[OrderDate]: ScaLogOp DependOnCols(6)('Sales'[OrderDate]) DateTime DominantValue=NONE
9 'Calendar'[Date]: ScaLogOp DependOnCols(0)('Calendar'[Date]) DateTime DominantValue=NONE
10 GreaterThan: ScaLogOp DependOnCols(0, 7)('Calendar'[Date], 'Sales'[ShipDate]) Boolean DominantValue=NONE
11 'Sales'[ShipDate]: ScaLogOp DependOnCols(7)('Sales'[ShipDate]) DateTime DominantValue=NONE
12 'Calendar'[Date]: ScaLogOp DependOnCols(0)('Calendar'[Date]) DateTime DominantValue=NONE
按层级绘制流程图
从上往下看是逻辑执行方向,分别是:
-
1:AddColumns(2:Scan_Vertipaq, 3:CountRows) -
3:CountRows(4:Filter) -
4:Filter(5:FILTER, Sales[ShipDate] > Calendar[Date]) -
5:Filter(6:Scan_Vertipaq, Sales[OrderDate] < Calendar[Date])
从下往上看是数据流向方向,依次是:
-
6:Scan_Vertipaq
从 SE 获取数据 VQ1,即: Sales[RowNumber], Sales[OrderDate],Sales[ShipDate] -
5:Filter(6:Scan_Vertipaq, Sales[OrderDate] < Calendar[Date])
从 6# 的数据中筛选出 Sales[OrderDate]<Calendar[Date] 的数据 -
4:Filter(5:FILTER, Sales[ShipDate] > Calendar[Date])
从 5# 的结果中中继续筛选出 Sales[ShipDate]>Calendar[Date] 的数据 -
3:CountRows(4:Filter)
对 4# 的结果进行行计数 -
2:Scan_Vertipaq
从 SE 获取数据 VQ2,即:Calendar[Date] -
1:AddColumns(2:Scan_Vertipaq, 3:CountRows)
基于 2# 、3# 的数据,构造最终的结果
尽管逻辑查询计划与原始 DAX 代码比较相似,但它并不代表底层运算顺序,而且在这个案例中,逻辑查询计划并没有提供值得关注的信息。
物理查询计划
引擎会根据逻辑查询计划生成实际可行的物理查询计划,所以分析物理查询计划才是重点。
物理查询计划如下:
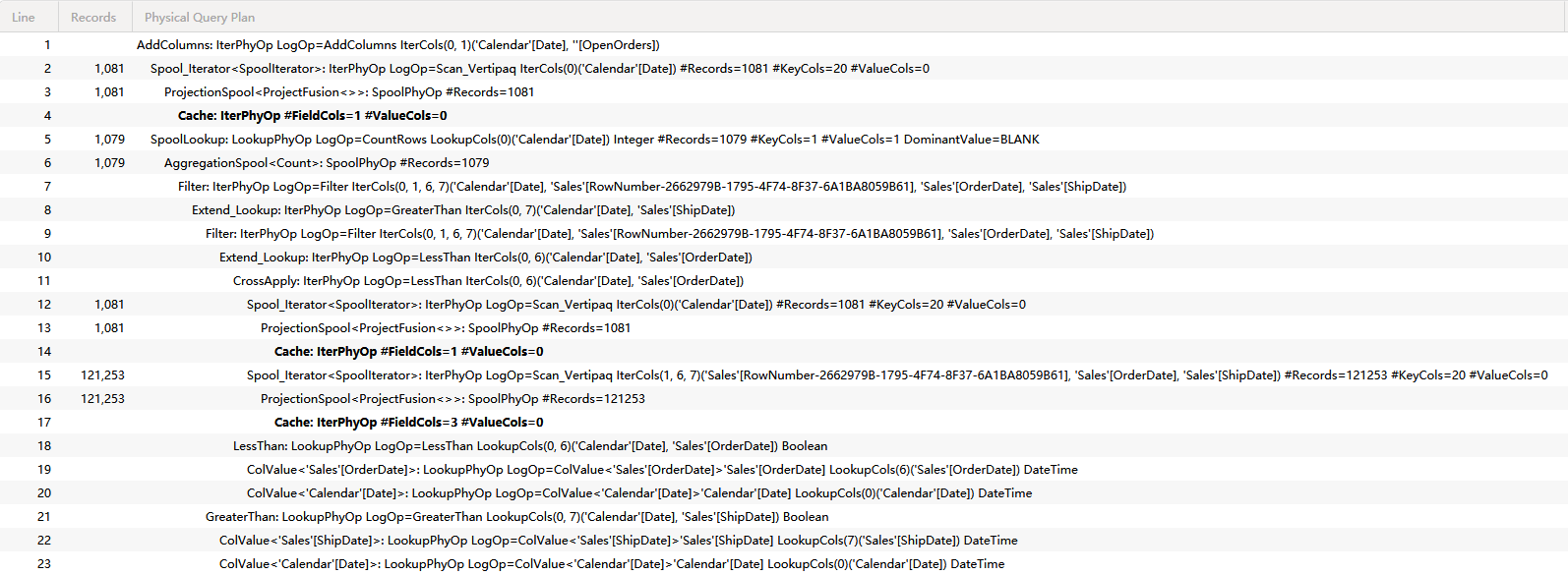
为了展示层级,暂且把 Line、Records 先去掉,删除 LogOp 内容,根据缩进级别添加层级结构线后,代码如下:
AddColumns: IterPhyOp IterCols(0, 1)('Calendar'[Date], ''[OpenOrders])
├── Spool_Iterator<SpoolIterator>: IterPhyOp IterCols(0)('Calendar'[Date]) #Records=1081 #KeyCols=20 #ValueCols=0
│ └── ProjectionSpool<ProjectFusion<>>: SpoolPhyOp #Records=1081
│ └── Cache: IterPhyOp #FieldCols=1 #ValueCols=0
└── SpoolLookup: LookupPhyOp LookupCols(0)('Calendar'[Date]) Integer #Records=1079 #KeyCols=1 #ValueCols=1 DominantValue=BLANK
└── AggregationSpool<Count>: SpoolPhyOp #Records=1079
└── Filter: IterPhyOp IterCols(0, 1, 6, 7)('Calendar'[Date], 'Sales'[RowNumber], 'Sales'[OrderDate], 'Sales'[ShipDate])
└── Extend_Lookup: IterPhyOp IterCols(0, 7)('Calendar'[Date], 'Sales'[ShipDate])
├── Filter: IterPhyOp IterCols(0, 1, 6, 7)('Calendar'[Date], 'Sales'[RowNumber], 'Sales'[OrderDate], 'Sales'[ShipDate])
│ └── Extend_Lookup: IterPhyOp IterCols(0, 6)('Calendar'[Date], 'Sales'[OrderDate])
│ ├── CrossApply: IterPhyOp IterCols(0, 6)('Calendar'[Date], 'Sales'[OrderDate])
│ │ ├── Spool_Iterator<SpoolIterator>: IterPhyOp IterCols(0)('Calendar'[Date]) #Records=1081 #KeyCols=20 #ValueCols=0
│ │ │ └── ProjectionSpool<ProjectFusion<>>: SpoolPhyOp #Records=1081
│ │ │ └── Cache: IterPhyOp #FieldCols=1 #ValueCols=0
│ │ └── Spool_Iterator<SpoolIterator>: IterPhyOp IterCols(1, 6, 7)('Sales'[RowNumber], 'Sales'[OrderDate], 'Sales'[ShipDate]) #Records=121253 #KeyCols=20 #ValueCols=0
│ │ └── ProjectionSpool<ProjectFusion<>>: SpoolPhyOp #Records=121253
│ │ └── Cache: IterPhyOp #FieldCols=3 #ValueCols=0
│ └── LessThan: LookupPhyOp LookupCols(0, 6)('Calendar'[Date], 'Sales'[OrderDate]) Boolean
│ ├── ColValue<'Sales'[OrderDate]>: LookupPhyOp LookupCols(6)('Sales'[OrderDate]) DateTime
│ └── ColValue<'Calendar'[Date]>: LookupPhyOp LookupCols(0)('Calendar'[Date]) DateTime
└── GreaterThan: LookupPhyOp LookupCols(0, 7)('Calendar'[Date], 'Sales'[ShipDate]) Boolean
├── ColValue<'Sales'[ShipDate]>: LookupPhyOp LookupCols(7)('Sales'[ShipDate]) DateTime
└── ColValue<'Calendar'[Date]>: LookupPhyOp LookupCols(0)('Calendar'[Date]) DateTime
把关键步骤用流程图梳理一下
也可以再简化下,把 Cache 对应的 xmSQL 查询标记出来,把 Filter 的条件缩写到一个块里,没有分支的 SpoolLookup 与其下 Count 合写在一起。
底层计算过程
理清物理查询计划后,复盘这段 DAX 查询在底层是如何执行的,从最下往上追溯
- 向 SE 发送数据查询请求
14:Cache(VQ2) 和17:Cache(VQ1) 得到数据 VQ2 和 VQ1,11:CrossApply 计算 VQ2 和 VQ1 的交叉表(笛卡尔积),等同于CROSSJOIN(VQ2,VQ1)
计算结果包含如下几列:
Calendar[Date], Sales[RowNumber], Sales[OrderDate], Sales[ShipDate]
VQ2 有 1081 行,VQ1 有 101253,两者的交叉表的数据行数,理论上为 1081 × 101253 = 109,454,493
-
9:Filter 对11:CrossApply的结果进行筛选,条件为 Sales[OrderDate] < Calendar[Date],筛选出 37,848,676 行数据
-
7:Filter 对9:Filter 的结果进行筛选,条件为 Sales[ShipDate] > Calendar[Date],筛选出 714,840 行数据
- 将
7:Filter 的结果以 Calendar[Date] 列为分组依据,进行行计数
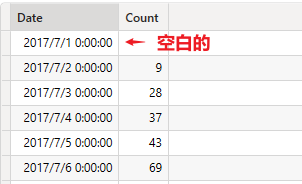
结果表包含两列 Calendar[Date], [Count],共 1079 行数据,注意这里 1079 行数据小于 Calendar 表中的行数 1081
- 向 SE 发送数据查询请求
4:Cache(VQ1),得到 VQ1 ,1.AddColumns以 VQ1 中的 Calendar[Date] 为基准,从 4# 的结果表中根据每个 Calendar[Date]的值找出对应的[Count] 值,构造最终结果表
以 4:Cache(VQ2)的1081行数据为基准,从7:Filter的1079行数据中匹配对应日期的 [Count] 值,所以有2行是空白的,这2个日期没有 open orders,比如 2017-7-1 这天,没有符合 OrderDate < 2017-7-1 < ShipDate 的订单。
性能瓶颈分析
存储引擎(SE)虽然运行在多线程下,但是本案例中它只执行了两个 xmSQL 查询,而且都是初级数据,还需要公式引擎(FE)执行大量运算来转换成最终结果。所以我们之前测试看到整个计算过程中,SE 耗时非常短,占总时长的比例相当小。
通过查看物理查询计划并复盘可以看到,步骤 1 中 将 VQ1(101253行) 和 VQ2(1081)行做交叉表,得到数量非常庞大的数据表(109,454,493行),这需要耗费大量内存。后续又对该数据表进行两次 FILTER 操作,这些操作都通过公式引擎(FE)完成,而公式引擎是单线程的,耗费了大量时间。因此整个计算过程中,大量时间都耗在了 FE 部分。
这便是该 DAX 查询计算效率不高的原因。
改进方向分析
找到性能瓶颈后,返回到 DAX 查询代码中,注意这一部分
FILTER (
Sales, // 注意此处
Sales[OrderDate] < 'Calendar'[Date] &&
Sales[ShipDate] > 'Calendar'[Date]
)
这里相对比较好理解,用基础 DAX 理论分析也可以看到 FILTER 函数使用 Sales 表作为迭代对象,会将对整个 Sales 表的 101253 行逐一扫描,分别读取每行的 [OrderDate] 和 [ShipDate] 与行上下文中的 Calendar[Date] 进行比较。
而且 FILTER 筛选计算发生在 ADDCOLUMNS 中,ADDCOLUMNS 本身也是迭代器,其遍历的对象 Calendar[Date] 也有 1081 行,每一行都要执行 FILTER 去扫描 Sales 的 101253 行数据,总共需要扫描的数据行便是 1081 × 101253 = 109,454,493,对应底层执行过程第一个步骤 11:CrossApply 介绍的交叉表。
当然在理解了物理查询计划之后,我们应该认识到:在底层执行时,实际上并没有逐行扫描,也没有从行上下文中去读取 Calendar[Date],而是采用了直接将两表求笛卡尔积的方式,将所有的 Calendar[Date] 和 {Sales[OrderDate],Sales[ShipDate]} 值对全部进行了穷举,这是迭代器的底层算法实现,与 DAX 理论中的迭代器计算方式本质是一样的。
因此,改进的方向是:
为了减少交叉表的数据量,我们需要想办法减少 FILTER 一参表的势(或者叫基数,即不重复值的数量)。
其他
一
直接将数据量非常大的表作为迭代对象,在底层执行时可能会形成数量非常庞大的交叉表,导致计算性能下降耗时更长,这也是为什么关于 FILTER 的最佳实践指南中,总是会提到:“尽量不要使用整表作为 FILTER 的一参,而是使用真正需要参与计算的列作为迭代对象”的底层原因之一。
比如权威指南第二版提到,
应当避免使用表筛选器,这样做通常开销巨大,Sales 表可能非常大,逐行对其进行扫描将耗费大量时间。

二
初始方案应用了最直接的计算思路,写出的 DAX 查询对应的查询计划,是白皮书里介绍的几种方案中最简单的,物理查询计划中出现的操作符和流程还算简单。后续的改进方案中,物理查询计划中的流程更复杂,操作符更多,但的确可以使计算性能提醒明显,值得学习。
三
当前官方没有提供物理查询计划操作符的详细说明,笔者也只能结合实践观察进行猜测,对很多的操作符认识不足,解读不一定正确。

















 2459
2459

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









