




上一篇文章中介绍了初始方案的查询计划,找到了性能瓶颈来自 FILTER 的一参使用 Sales 整表,在底层执行时需要计算数据量巨大的交叉表,导致公式引擎部分耗费大量时间,确定了改进方向是想法提高 FILTER 的性能,减少迭代对象的势。不过白皮书给出的第一个方案并没有直接从减少 FILTER 迭代对象的势入手,而是采取了 CALCULATE+FILTER 的写法,这也是许多初学者可能采取的方案。那么本篇文章将继续通过理解查询计划,了解其底层执行过程,分析其优劣势。
运行环境、模拟数据、计算要求与上一篇相同。
研究《DAX查询计划 白皮书》中的案例(一)初始方案
研究《DAX查询计划 白皮书》中的案例(二)优化方案1
研究《DAX查询计划 白皮书》中的案例(三)优化方案(番外)
研究《DAX查询计划 白皮书》中的案例(四)优化方案2
研究《DAX查询计划 白皮书》中的案例(四)优化方案3
优化方案1
DAX 查询
// 优化方案1
EVALUATE
ADDCOLUMNS (
VALUES ( 'Calendar'[Date] ),
"OpenOrders",
CALCULATE (
COUNTROWS ( Sales ),
FILTER ( sales, sales[OrderDate] < 'Calendar'[Date] ),
FILTER ( sales, sales[ShipDate] > 'Calendar'[Date] )
) // 白皮书这里给的方案就是两个 FILTER
)
运行效率
以连续5次冷启动的结果进行统计:
- 环境1
平均总耗时 290.4 毫秒,标准差 26.07 毫秒
其中 SE(存储引擎)平均耗时 4.80 毫秒,标准差 1.48 毫秒
SE/总耗时 = 1.653%
- 环境2
平均总耗时 300 毫秒,标准差 2.88 毫秒
其中 SE(存储引擎)平均耗时 5.80 毫秒,标准差 3.19 毫秒
SE/总耗时 = 1.929%
与之前的原始方案做比较:
| 环境 | 参数 | 初始方案 | 优化方案1 | 提升幅度 |
|---|---|---|---|---|
| 环境1 | 平均总耗时 | 4389.4 | 290.4 | 93.38% |
| SE耗时 | 14.4 | 4.8 | 66.67% | |
| SE占比 | 0.328% | 1.653% | 403.83% | |
| 环境2 | 平均总耗时 | 4017.0 | 300.60 | 92.52% |
| SE耗时 | 17.2 | 5.8 | 66.28% | |
| SE占比 | 0.428% | 1.929% | 350.62% |
与初始方案对比,优化方案1带来的性能提升非常明显,平均总耗时从 4389.4 毫秒缩减到 290.4 毫秒,计算效率提升约 90% 以上, SE 耗时占比也大幅提高。
从 DAX 代码来看,FILTER 仍然使用整个 Sales 表作为迭代对象,与初始方案的区别并不大,究竟是哪个部分使其获得了性能提升,它是如何解决超大交叉表的性能瓶颈的,本篇继续通过查看查询计划来一探究竟。
存储引擎部分
存储引擎这次执行了 4 个 xmSQL 查询,分别是:
1、VQ1:从 Sales 表中以 [OrderDate] 分组,返回 [OrderDate] 列的不重复值,该查询返回 1081 行数据
// VQ1
SELECT
'Sales'[OrderDate]
FROM 'Sales';
2、VQ2:从 Calendar 表中以 [Date] 分组,返回 [Date] 列的不重复值,该查询返回 1081 行数据
// VQ2
SELECT
'Calendar'[Date]
FROM 'Calendar';
3、VQ3:从 Sales 表中以 [ShipDate] 分组,返回 [ShipDate] 列的不重复值,该查询返回 1075 行数据
// VQ3
SELECT
'Sales'[ShipDate]
FROM 'Sales';
4、VQ4:该 xmSQL 与之前的有些区别,先看看代码
// VQ4
SELECT
'Sales'[OrderDate],
'Sales'[ShipDate],
COUNT ( )
FROM 'Sales'
WHERE
'Sales'[OrderDate] IN ( 43768.000000, 43809.000000, 43850.000000, 43893.000000, 43934.000000, 43975.000000, 43014.000000, 43426.000000, 43468.000000, 43513.000000..[1,080 total values, not all displayed] ) VAND
'Sales'[ShipDate] IN ( 43775.000000, 43816.000000, 43857.000000, 43900.000000, 43941.000000, 43982.000000, 43028.000000, 43433.000000, 43475.000000, 43520.000000..[1,074 total values, not all displayed] ) ;
该 xmSQL 查询的 WHERE 子句中有许多字符,限定了 Sales[OrderDate] 和 Sales[ShipDate] 的值范围,
‘Sales’[OrderDate] IN ( 43768.000000, 43809.000000, 43850.000000, 43893.000000, 43934.000000, 43975.000000, 43014.000000, 43426.000000, 43468.000000, 43513.000000…[1,080 total values, not all displayed] ) VAND
‘Sales’[ShipDate] IN ( 43775.000000, 43816.000000, 43857.000000, 43900.000000, 43941.000000, 43982.000000, 43028.000000, 43433.000000, 43475.000000, 43520.000000…[1,074 total values, not all displayed] )
WHERE 子句将 Sales[Order] 限定在 1080 个值的列表中,Sales[ShipDate] 限定在 1074 个值的列表中。这些列表怎么来的,后面的物理查询计划会给出答案。
整个 xmSQL 查询以 Sales[OrderDate]、Sales[ShipDate]为分组依据,从符合 WHERE 子句条件的 Sales 表数据中返回 {[OrderDate]、[ShipDate]} 的非重复值对,并计算每组值对出现的次数,共 1079 行,包括3列:
Sales[OrderDate], Sales[ShipDate], [COUNT]
可以借用这段 DAX 查询,来理解该 xmSQL 查询的结果:
// DAX
DEFINE
VAR OrderDateList = ...
VAR ShipDateList = ...
EVALUATE
CALCULATETABLE (
ADDCOLUMNS (
SUMMARIZE ( Sales, Sales[OrderDate], sales[ShipDate] ),
"COUNT", CALCULATE ( COUNTROWS ( Sales ) )
),
orderDatelist,
shipdatelist
)
公式引擎部分
逻辑查询计划
逻辑查询计划的代码和流程图如下:
AddColumns: RelLogOp DependOnCols()() 0-1 RequiredCols(0, 1)('Calendar'[Date], ''[OpenOrders])
├── Scan_Vertipaq: RelLogOp DependOnCols()() 0-0 RequiredCols(0)('Calendar'[Date])
└── Calculate: ScaLogOp DependOnCols(0)('Calendar'[Date]) Integer DominantValue=BLANK
├── Count_Vertipaq: ScaLogOp DependOnCols(0)('Calendar'[Date]) Integer DominantValue=BLANK
│ └── Scan_Vertipaq: RelLogOp DependOnCols(0)('Calendar'[Date]) 31-45 RequiredCols(0)('Calendar'[Date])
├── Filter: RelLogOp DependOnCols(0)('Calendar'[Date]) 1-15 RequiredCols(0, 6)('Calendar'[Date], 'Sales'[OrderDate])
│ ├── Scan_Vertipaq: RelLogOp DependOnCols()() 1-15 RequiredCols(6)('Sales'[OrderDate])
│ └── LessThan: ScaLogOp DependOnCols(0, 6)('Calendar'[Date], 'Sales'[OrderDate]) Boolean DominantValue=NONE
│ ├── 'Sales'[OrderDate]: ScaLogOp DependOnCols(6)('Sales'[OrderDate]) DateTime DominantValue=NONE
│ └── 'Calendar'[Date]: ScaLogOp DependOnCols(0)('Calendar'[Date]) DateTime DominantValue=NONE
└── Filter: RelLogOp DependOnCols(0)('Calendar'[Date]) 16-30 RequiredCols(0, 22)('Calendar'[Date], 'Sales'[ShipDate])
├── Scan_Vertipaq: RelLogOp DependOnCols()() 16-30 RequiredCols(22)('Sales'[ShipDate])
└── GreaterThan: ScaLogOp DependOnCols(0, 22)('Calendar'[Date], 'Sales'[ShipDate]) Boolean DominantValue=NONE
├── 'Sales'[ShipDate]: ScaLogOp DependOnCols(22)('Sales'[ShipDate]) DateTime DominantValue=NONE
└── 'Calendar'[Date]: ScaLogOp DependOnCols(0)('Calendar'[Date]) DateTime DominantValue=NONE
图示结构图:
上一篇已经讲过,逻辑查询计划通常与原始 DAX 代码相似,本篇也没有出现例外,与 DAX 查询代码几乎完全一致,并没有提供足够有用的信息,继续往下查看物理查询计划。
物理查询计划
优化方案1的物理查询计划相对上一篇长了不少,截图如下

为了便于展示结构,删除 Lines 和 Records,加上层级结构线如下:
AddColumns: IterPhyOp LogOp=AddColumns IterCols(0, 1)('Calendar'[Date], ''[OpenOrders])
├── Spool_Iterator<SpoolIterator>: IterPhyOp LogOp=Scan_Vertipaq IterCols(0)('Calendar'[Date]) #Records=1081 #KeyCols=26 #ValueCols=0
│ └── ProjectionSpool<ProjectFusion<>>: SpoolPhyOp #Records=1081
│ └── Cache: IterPhyOp #FieldCols=1 #ValueCols=0
└── SpoolLookup: LookupPhyOp LogOp=Count_Vertipaq LookupCols(0)('Calendar'[Date]) Integer #Records=1079 #KeyCols=1 #ValueCols=1 DominantValue=BLANK
└── AggregationSpool<AggFusion<Sum>>: SpoolPhyOp #Records=1079
└── CrossApply: IterPhyOp LogOp=Count_Vertipaq IterCols(0)('Calendar'[Date])
├── Spool_UniqueHashLookup: IterPhyOp LogOp=Filter LookupCols(0, 22)('Calendar'[Date], 'Sales'[ShipDate]) #Records=583719 #KeyCols=2 #ValueCols=0
│ └── AggregationSpool<GroupBy>: SpoolPhyOp #Records=583719
│ └── Filter: IterPhyOp LogOp=Filter IterCols(0, 22)('Calendar'[Date], 'Sales'[ShipDate])
│ └── Extend_Lookup: IterPhyOp LogOp=GreaterThan IterCols(0, 22)('Calendar'[Date], 'Sales'[ShipDate])
│ ├── CrossApply: IterPhyOp LogOp=GreaterThan IterCols(0, 22)('Calendar'[Date], 'Sales'[ShipDate])
│ │ ├── Spool_Iterator<SpoolIterator>: IterPhyOp LogOp=Scan_Vertipaq IterCols(0)('Calendar'[Date]) #Records=1081 #KeyCols=26 #ValueCols=0
│ │ │ └── ProjectionSpool<ProjectFusion<>>: SpoolPhyOp #Records=1081
│ │ │ └── Cache: IterPhyOp #FieldCols=1 #ValueCols=0
│ │ └── Spool_Iterator<SpoolIterator>: IterPhyOp LogOp=Scan_Vertipaq IterCols(22)('Sales'[ShipDate]) #Records=1075 #KeyCols=26 #ValueCols=0
│ │ └── ProjectionSpool<ProjectFusion<>>: SpoolPhyOp #Records=1075
│ │ └── Cache: IterPhyOp #FieldCols=1 #ValueCols=0
│ └── GreaterThan: LookupPhyOp LogOp=GreaterThan LookupCols(0, 22)('Calendar'[Date], 'Sales'[ShipDate]) Boolean
│ ├── ColValue<'Sales'[ShipDate]>: LookupPhyOp LogOp=ColValue<'Sales'[ShipDate]>'Sales'[ShipDate] LookupCols(22)('Sales'[ShipDate]) DateTime
│ └── ColValue<'Calendar'[Date]>: LookupPhyOp LogOp=ColValue<'Calendar'[Date]>'Calendar'[Date] LookupCols(0)('Calendar'[Date]) DateTime
├── Spool_MultiValuedHashLookup: IterPhyOp LogOp=Filter LookupCols(6)('Sales'[OrderDate]) IterCols(0)('Calendar'[Date]) #Records=583740 #KeyCols=2 #ValueCols=0
│ └── AggregationSpool<GroupBy>: SpoolPhyOp #Records=583740
│ └── Filter: IterPhyOp LogOp=Filter IterCols(0, 6)('Calendar'[Date], 'Sales'[OrderDate])
│ └── Extend_Lookup: IterPhyOp LogOp=LessThan IterCols(0, 6)('Calendar'[Date], 'Sales'[OrderDate])
│ ├── CrossApply: IterPhyOp LogOp=LessThan IterCols(0, 6)('Calendar'[Date], 'Sales'[OrderDate])
│ │ ├── Spool_Iterator<SpoolIterator>: IterPhyOp LogOp=Scan_Vertipaq IterCols(0)('Calendar'[Date]) #Records=1081 #KeyCols=26 #ValueCols=0
│ │ │ └── ProjectionSpool<ProjectFusion<>>: SpoolPhyOp #Records=1081
│ │ │ └── Cache: IterPhyOp #FieldCols=1 #ValueCols=0
│ │ └── Spool_Iterator<SpoolIterator>: IterPhyOp LogOp=Scan_Vertipaq IterCols(6)('Sales'[OrderDate]) #Records=1081 #KeyCols=26 #ValueCols=0
│ │ └── ProjectionSpool<ProjectFusion<>>: SpoolPhyOp #Records=1081
│ │ └── Cache: IterPhyOp #FieldCols=1 #ValueCols=0
│ └── LessThan: LookupPhyOp LogOp=LessThan LookupCols(0, 6)('Calendar'[Date], 'Sales'[OrderDate]) Boolean
│ ├── ColValue<'Sales'[OrderDate]>: LookupPhyOp LogOp=ColValue<'Sales'[OrderDate]>'Sales'[OrderDate] LookupCols(6)('Sales'[OrderDate]) DateTime
│ └── ColValue<'Calendar'[Date]>: LookupPhyOp LogOp=ColValue<'Calendar'[Date]>'Calendar'[Date] LookupCols(0)('Calendar'[Date]) DateTime
└── Cache: IterPhyOp #FieldCols=2 #ValueCols=1
├── Spool_Iterator<SpoolIterator>: IterPhyOp LogOp=Filter IterCols(0, 6)('Calendar'[Date], 'Sales'[OrderDate]) #Records=583740 #KeyCols=2 #ValueCols=0
│ └── AggregationSpool<GroupBy>: SpoolPhyOp #Records=583740
│ └── Filter: IterPhyOp LogOp=Filter IterCols(0, 6)('Calendar'[Date], 'Sales'[OrderDate])
│ └── Extend_Lookup: IterPhyOp LogOp=LessThan IterCols(0, 6)('Calendar'[Date], 'Sales'[OrderDate])
│ ├── CrossApply: IterPhyOp LogOp=LessThan IterCols(0, 6)('Calendar'[Date], 'Sales'[OrderDate])
│ │ ├── Spool_Iterator<SpoolIterator>: IterPhyOp LogOp=Scan_Vertipaq IterCols(0)('Calendar'[Date]) #Records=1081 #KeyCols=26 #ValueCols=0
│ │ │ └── ProjectionSpool<ProjectFusion<>>: SpoolPhyOp #Records=1081
│ │ │ └── Cache: IterPhyOp #FieldCols=1 #ValueCols=0
│ │ └── Spool_Iterator<SpoolIterator>: IterPhyOp LogOp=Scan_Vertipaq IterCols(6)('Sales'[OrderDate]) #Records=1081 #KeyCols=26 #ValueCols=0
│ │ └── ProjectionSpool<ProjectFusion<>>: SpoolPhyOp #Records=1081
│ │ └── Cache: IterPhyOp #FieldCols=1 #ValueCols=0
│ └── LessThan: LookupPhyOp LogOp=LessThan LookupCols(0, 6)('Calendar'[Date], 'Sales'[OrderDate]) Boolean
│ ├── ColValue<'Sales'[OrderDate]>: LookupPhyOp LogOp=ColValue<'Sales'[OrderDate]>'Sales'[OrderDate] LookupCols(6)('Sales'[OrderDate]) DateTime
│ └── ColValue<'Calendar'[Date]>: LookupPhyOp LogOp=ColValue<'Calendar'[Date]>'Calendar'[Date] LookupCols(0)('Calendar'[Date]) DateTime
└── Spool_Iterator<SpoolIterator>: IterPhyOp LogOp=Filter IterCols(0, 22)('Calendar'[Date], 'Sales'[ShipDate]) #Records=583719 #KeyCols=2 #ValueCols=0
└── AggregationSpool<GroupBy>: SpoolPhyOp #Records=583719
└── Filter: IterPhyOp LogOp=Filter IterCols(0, 22)('Calendar'[Date], 'Sales'[ShipDate])
└── Extend_Lookup: IterPhyOp LogOp=GreaterThan IterCols(0, 22)('Calendar'[Date], 'Sales'[ShipDate])
├── CrossApply: IterPhyOp LogOp=GreaterThan IterCols(0, 22)('Calendar'[Date], 'Sales'[ShipDate])
│ ├── Spool_Iterator<SpoolIterator>: IterPhyOp LogOp=Scan_Vertipaq IterCols(0)('Calendar'[Date]) #Records=1081 #KeyCols=26 #ValueCols=0
│ │ └── ProjectionSpool<ProjectFusion<>>: SpoolPhyOp #Records=1081
│ │ └── Cache: IterPhyOp #FieldCols=1 #ValueCols=0
│ └── Spool_Iterator<SpoolIterator>: IterPhyOp LogOp=Scan_Vertipaq IterCols(22)('Sales'[ShipDate]) #Records=1075 #KeyCols=26 #ValueCols=0
│ └── ProjectionSpool<ProjectFusion<>>: SpoolPhyOp #Records=1075
│ └── Cache: IterPhyOp #FieldCols=1 #ValueCols=0
└── GreaterThan: LookupPhyOp LogOp=GreaterThan LookupCols(0, 22)('Calendar'[Date], 'Sales'[ShipDate]) Boolean
├── ColValue<'Sales'[ShipDate]>: LookupPhyOp LogOp=ColValue<'Sales'[ShipDate]>'Sales'[ShipDate] LookupCols(22)('Sales'[ShipDate]) DateTime
└── ColValue<'Calendar'[Date]>: LookupPhyOp LogOp=ColValue<'Calendar'[Date]>'Calendar'[Date] LookupCols(0)('Calendar'[Date]) DateTime
用流程图来说明层级结构(注意一下 7:CrossApply的子级,按先后顺序应该是 8:Spool_UniqueHashLookup、22:Spool_MultiValuedHashLookup、36:Cache(VQ4),但是用 Mermaid 画出来22:Spool_MultiValuedHashLookup 跑到最左边去了,如果有谁知道在 Mermaid 中怎么控制这些块的排布顺序,将8:Spool_UniqueHashLookup调到最左侧,请指导一下,谢谢)
在这次的物理查询计划中,有部分行内容是重复的,上图中用 T1 和 T2 和方框做了标记,各部分作用如下:
-
T1:将 VQ2(Calendar[Date])(1081行) 与 VQ3(Sales[ShipDate])(1075行) 求交叉表(1081×1075=1162075行),从中筛选出 Sales[ShipDate] > Calendar[Date] 的数据,共 583719 行,有两列,Sales[ShipDate] 和 Calendar[Date],后文用
T1(Sales[ShipDate],Calendar[Date])表示T1的结果 -
T2:将 VQ2 (Calendar[Date])(1081行)与 VQ1(Sales[OrderDate]) (1081行) 求交叉表(1081×1081=1168561行),从中筛选出 Sales[OrderDate] < Calednar[Date] 的数据,共 583740 行,有两列,Sales[OrderDate] 和 Calendar[Date],后文用
T2(Sales[OrderDate],Calendar[Date])表示T2的结果
这种通过求交叉表再进行筛选的操作,在上一篇初始方案的查询计划中已经见到过了,在 DAX 底层这是一种常见操作。
将重复的步骤合并后,把流程图简化一下:
现在来回答前面 VQ4 xmSQL 中 WHERE 子句中的值列表怎么来的,VQ4 的代码再贴一下
// VQ4
SELECT
'Sales'[OrderDate],
'Sales'[ShipDate],
COUNT ( )
FROM 'Sales'
WHERE
'Sales'[OrderDate] IN ( 43768.000000, 43809.000000, 43850.000000, 43893.000000, 43934.000000, 43975.000000, 43014.000000, 43426.000000, 43468.000000, 43513.000000..[1,080 total values, not all displayed] ) VAND
'Sales'[ShipDate] IN ( 43775.000000, 43816.000000, 43857.000000, 43900.000000, 43941.000000, 43982.000000, 43028.000000, 43433.000000, 43475.000000, 43520.000000..[1,074 total values, not all displayed] ) ;
从上面物理查询计划的流程图可知,36:Cache(VQ4) 使用了 T1 和 T2,这便是 VQ4 的 xmSQL 中 WHERE 子句部分的来源:
-
WHERE 子句将 Sales[OrderDate] 限定在 1080 个值列表中,这 1080 个值来自 T2 结果中 [ShipDate] 的不重复值。
-
WHERE 子句将 Sales[ShipDate] 限定在 1074 个值列表中, 这 1074 个值来自 T1 结果中 [ShipDate] 的不重复值。
在 DAX Studio 中可以验证一下 1074 这个数值。
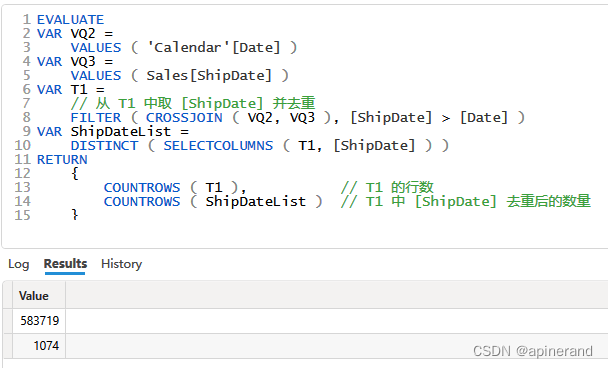
据此可知,VQ4 分别限定了 Sales[OrderDate] 和 Sales[ShipDate] 的值范围,使其满足 Sales[OrderDate] < Calednar[Date] 和 Sales[ShipDate] > Calendar[Date] 两个条件,对 Sales 表进行筛选,并将符合的数据行以 Sales[OrderDate] 和 Sales[ShipDate] 分组,计算出每个分组的行数 [Count]。后文以 VQ4(Sales[OrderDate], Sales[ShipDate], [COUNT])表示 VQ4 的结果
底层计算过程
由于没有找到关于操作符 Spool_UniqueHashLookup 和 Spool_MultiValuedHashLookup的说明,根据最终结果、结合实践做一些方案推理,目前我找到一个可能的理解,暂未遇到能够推翻该理解的反例,姑且认为是正确,那么现在可以把优化方案1的底层计算过程梳理出来了:
1、SE 执行 xmlSQL 查询: VQ2 和 VQ1,操作符CrossApply 对VQ2 和 VQ1求交叉表即 Calendar[Date] 和 Sales[OrderDate] 的交叉表,操作符FILTER从该交叉表中筛选出 Sales[OrderDate]<Calendar[Date] 的数据,得到 T1(Sales[ShipDate],Calendar[Date])
2、SE 执行 xmlSQL 查询: VQ2 和 VQ3,操作符CrossApply 对VQ2 和 VQ3 求交叉表 即 Calendar[Date] 和 Sales[ShipDate] 的交叉表,操作符FILTER从该交叉表中筛选出 Sales[ShipDate]> Calendar[Date] 的数据,得到 T2(Sales[OrderDate],Calendar[Date])
3、 T1 和 T2 中的 Sales[ShipDate] 和 Sales[OrderDate] 去重后构成 VQ4 WHERE 子句中的值列表,SE 执行 VQ4,得到VQ4(Sales[OrderDate], Sales[ShipDate], [COUNT])
4、22:Spool_MultiValuedHashLookup将VQ4(Sales[OrderDate], Sales[ShipDate], [COUNT])与T2(Sales[OrderDate],Calendar[Date]) 以共有的 Sales[OrderDate] 作为匹配列进行连接(类似 PowerQuery 里的合并查询),得到含有4列(Sales[OrderDate], Sales[ShipDate], [Count], Calendar[Date])的表,该表中的数据仅满足计算要求中的单个条件: Sales[OrderDate] < Calendar[Date] 这一个条件。
5、8:Spool_UniqueHashLookup将 4# 的结果与T1(Sales[ShipDate],Calendar[Date]) 以 Calendar[Date] 和 Sales[ShipDate] 作为匹配列进行内连接,包含4列(Sales[OrderDate], Sales[ShipDate], [Count], Calendar[Date])。该结果中的数据满足了计算要求中的两个条件:Sales[OrderDate] < Calendar[Date] 和 Sales[ShipDate] > Calendar[Date]
6、6:SUM将 5# 的结果以 Calendar[Date] 分组并将 [Count] 进行累加,得到一张仅有2列(Calendar[Date], [SUM])的表,其中 [SUM] 的值便是当日包含的 OpenOrders 数量
7、1:AddColumns以 4:Cache(VQ2)中的 Calendar[Date] 列为基准,从 6# 的结果中查询对应的 [SUM] 值,作为新添加的 [OpenOrders] 列的值,得到最终结果
性能瓶颈分析比较
优势
既然优化方案1相较原始方案将性能提升了 9 成,那么一定部分克服了上一篇中分析的性能瓶颈,回顾一下上一篇中原始方案的瓶颈:
SE 执行了 2 个查询,且都是初级数据,FE 执行大量运算来转换成最终结果。
FE 执行过程中,需要将 VQ1(101253行) 和 VQ2(1081)行做交叉表,得到数量非常庞大的数据表(109,454,493行),这需要耗费大量内存。后续又对该数据表进行两次 FILTER 操作,耗费了大量时间。
上一篇的分析中, VQ1(101253行) 和 VQ2(1081)交叉表数据量非常庞大,原因是原始方案中 VQ1 存在一个特殊列 Sales[RowNumber] 使得该查询返回了 Sales 表中全部 101253 行中的 [OrderDate] 和 [ShipDate]
// 原始方案中的 VQ1
SELECT
'Sales'[RowNumber], //注意此处
'Sales'[OrderDate],
'Sales'[ShipDate]
FROM 'Sales';
xmSQL 与标准 SQL 有一个重大的区别:xmSQL 始终对 SELECT 子句中的列进行分组运算,而标准 SQL 必须使用 GROUP BY 来设置分组。下面两段代码是等价的:
// xmSQL
SELECT Product[Color]
FROM Product
// 标准 ANSI SQL
SELECT Color
FROM Product
GROUP BY Color
[RowNumber] 是引擎在底层自动给表添加的唯一标识列,当 xmSQL 需要获取表中每一行的数据时,就会将 [RowNumber] 添加到 SELECT 子句中,由于 [RowNumber] 每一行都有不同的值,对其进行分组的实际效果等价于不分组。因此,原始方案中的 VQ1 返回了 101253 行数据。
而本篇的优化方案1,存储引擎执行的与 Sales 有关的 3 个 xmSQL 查询中, SELECT 子句中都没有出现 [RowNumber],分别如下:
// VQ1
SELECT
'Sales'[OrderDate]
FROM 'Sales';
// VQ3
SELECT
'Sales'[ShipDate]
FROM 'Sales';
// VQ4
SELECT
'Sales'[OrderDate],
'Sales'[ShipDate],
COUNT ( )
FROM 'Sales'
WHERE
'Sales'[OrderDate] IN ( 43768.000000, 43809.000000, 43850.000000, 43893.000000, 43934.000000, 43975.000000, 43014.000000, 43426.000000, 43468.000000, 43513.000000..[1,080 total values, not all displayed] ) VAND
'Sales'[ShipDate] IN ( 43775.000000, 43816.000000, 43857.000000, 43900.000000, 43941.000000, 43982.000000, 43028.000000, 43433.000000, 43475.000000, 43520.000000..[1,074 total values, not all displayed] ) ;
VQ1 等价于标准 SQL:
// ANSI SQL
SELECT OrderDate
FROM Sales
GROUP BY OrderDate
VQ4 等价于标准 SQL
// ANSI SQL
SELECT OrderDate, ShipDate, COUNT (*)
FROM Sales
WHERE OrderDate IN ... AND ShipDate IN ...
GROUP BY OrderDate, ShipDate
Sales 表中[OrderDate] 和 [ShipDate] 列都存在大量重复值,进行分组后,实际返回的数据量并不包含重复值,使得数据量大幅减少。
DAX 引擎在底层执行 FILTER 的判断条件时会先计算交叉表,比较两个方案的情况:
原始方案:
- 将 Sales 所有行(101253行)与 Calendar[Date](1081行) 做交叉表(109,454,493行)
优化方案1:
- 将去重后的 Sales[OrderDate](1081行)与 Calendar[Date](1081行)做交叉表(1,168,561行)
- 将去重后的 Sales[ShipDate](1075行)与 Calendar[Date](1081行)做交叉表(1,162,075行)
优化方案1 将交叉表的势,从亿级(108 )降到了百万级(106),减少了2个数量级,因此获得了相应的性能提升。
劣势
白皮书提供了3个优化方案,本篇的优化方案1是性能提升最小的一个。
单从本篇分析的底层执行过程来看,不容易找到哪里存在劣势。待研究完其他方案后,再通过比较来发现优化方案1的劣势吧。
思考总结
一
本篇介绍的优化方案1所采用的算法,本质上仍然是基于对计算要求的直接理解,并没有刻意使用任何能够减少迭代对象的势从而减少计算量的方法,计算效率得到提升,源自 DAX 底层对 CALCULATE + FILTER 进行过优化。
二
DAX 使用者从中能获取的实践经验,表面上看,有以下几点
-
在 DAX 引擎底层,CALCULATE 中的筛选器会被作为 WHERE 子句放到 xmSQL 中,而直接使用 FILTER 则不会,尤其在 FILTER 的一参中使用整表作为迭代对象时,还会在 xmSQL 中使用 [RowNumber],使查询结果的势等于整张表的总行数
-
即便在 FILTER 的一参中使用整表作为迭代对象,存储引擎执行的相关 xmSQL 时只会包含跟条件有关的列,并不会将一参中所有列都列进来。比如原始方案虽然写了
FLTER(Sales,...),从 DAX 理论来看,FILTER 会遍历 Sales 所有行上的行上下文,包括全部 14 列,但实际执行的 xmSQL,VQ1 中 SELECT 子句中只有’Sales’[RowNumber], ‘Sales’[OrderDate], ‘Sales’[ShipDate] 3列,并没有包含其他列,这也是 DAX 底层进行优化的结果 -
在某些数据模型中, 将 COUNTROWS( FILTER( Sales, …)) 的写法改成 CALCULATE + FILTER 的组合可能会计算得更快
说这是表面的经验,是因为 DAX 优化并不是只需要考虑代码如何写,而是需要先了解数据模型中的各列的势、列上的数据分布、数据类型等等因素,并不存在套用在任何数据模型中都能取得性能提升的通用经验写法。比如笔者看到过在某些数据模型中使用 CALCULATE 的写法导致产生数量庞大的 xmSQL 查询(比如生成99个 xmSQL 查询),反而拖慢计算速度。
DAX 使用者不应该追求找到某种通用的经验代码,而是应该先了解影响计算效率的因素,掌握分析方法,分析出性能瓶颈原因后,再结合数据模型改进写法,并通过测试判断是否实现了计算效率提升。
三
我不太明白为什么优化案例1中 CALCULATE 的参数中要写 2 个 FILTER,很显然它们可以合并成一个 FILTER,我测试了将 2 个 FILTER 合并的写法,计算速度会更快一些。
由于白皮书后面给出的另外两个优化方案不再是基于对计算要求的直接理解,改用了不同的算法,完全没有探讨将 FILTER 分开和合并的区别,我打算在继续写白皮书给的其他优化方案之前,先分析研究下 FILTER 合并后性能提升的原因。

















 1005
1005

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









