




在深度学习语言模型(LSTM、Transformer)出现之前,统计语言模型(Statistical Language Model, SLM)长期占据 NLP 主流地位。它们通过对大量语料进行统计,来估计词序列的概率,是最早被广泛应用于机器翻译、语音识别等系统的语言模型形式。
其中最经典、最重要的统计语言模型就是 n-gram 模型。
1. n-gram 的基本思想
根据概率论中的链式法则,长度为TTT的词序列x1,⋯ ,xTx_1, \cdots, x_Tx1,⋯,xT的联合概率可以写成:
p(x1,⋯ ,xT)=∏t=1TP(xt∣x1:t−1) p(x_1, \cdots, x_T)=\prod_{t=1}^{T} P(x_t \mid x_{1:t-1}) p(x1,⋯,xT)=t=1∏TP(xt∣x1:t−1)
也就是说,如果我们能够正确建模每一个词在给定前文的情况下出现的概率,就能计算整句的概率。然而,这里会遇到一个致命问题:条件依赖长度太长!。xtx_txt要依赖前面所有词,但真实语料根本不可能覆盖如此巨大的组合空间。
于是,n-gram 模型引入了简化假设:马尔可夫假设。
(1) 马尔可夫假设
-
一个词的出现只依赖它前面的n−1n-1n−1个词,而不是整个历史。
-
基于这一假设,我们将复杂的条件概率近似为:
P(xt∣x1:t−1)≈P(xt∣xt−n+1:t−1) P(x_{t}|x_{1:t-1}) \approx P(x_t|x_{t-n+1:t-1}) P(xt∣x1:t−1)≈P(xt∣xt−n+1:t−1)
这样,原本需要完整上下文的模型就简化成了只依赖固定长度窗口的模型,也就是 n-gram 模型。
(2) n-gram 的概率估计
Maximum Likelihood Estimation
n-gram 的核心是计算:
P(xt∣xt−n+1,⋯ ,xt−1) P(x_t|x_{t-n+1}, \cdots, x_{t-1}) P(xt∣xt−n+1,⋯,xt−1)
用最大似然估计(MLE)可以直接通过计数求得:
P(xt∣xt−n+1,⋯ ,xt−1)=Count(xt−n+1,⋯ ,xt−1,xt)Count(xt−n+1,⋯ ,xt−1) P(x_t|x_{t-n+1},\cdots,x_{t-1}) = \frac{\mathcal{Count}(x_{t-n+1}, \cdots, x_{t-1}, x_{t})}{\mathcal{Count}(x_{t-n+1}, \cdots, x_{t-1})} P(xt∣xt−n+1,⋯,xt−1)=Count(xt−n+1,⋯,xt−1)Count(xt−n+1,⋯,xt−1,xt)
nnn的阶数越高,对应的依赖关系就越长。
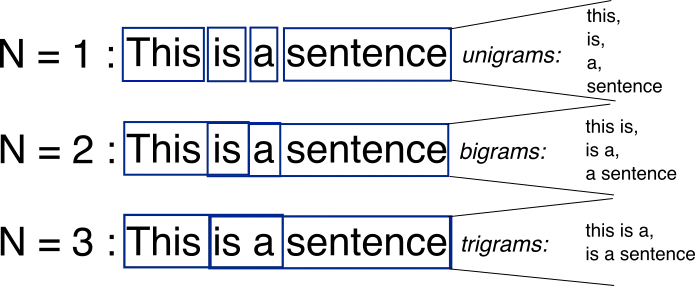
-
1-gram(Unigram)
Unigram 假设所有词独立出现,因此整句概率为:
P(x1,⋯ ,xt)=∏i=1tP(xi) P(x_1, \cdots, x_t) = \prod_{i=1}^t P(x_i) P(x1,⋯,xt)=i=1∏tP(xi)
此模型忽略了所有上下文信息,效果通常最差。 -
2-gram(Bigram)
基于一阶马尔可夫假设
Bigram 是最常用的基础 n-gram 模型,它假设每个词只依赖前一个词:
P(x1,⋯ ,xt)=P(x1)∏i=2tP(xi∣xi−1) P(x_1, \cdots, x_t) = P(x_1)\prod_{i=2}^t P(x_i|x_{i-1}) P(x1,⋯,xt)=P(x1)i=2∏tP(xi∣xi−1<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 957
957

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









