



大模型正悄悄改变着我们的生活和工作。就像当年的智能手机一样,谁先用好,谁就能抢占先机。今天咱们就来个大模型“摸底考”,看看这些大佬们都有啥绝活,谁家又适合你的业务。
一、技术背景与核心架构对比:谁是真高手?
咱们先从最核心的技术说起,看看这些大模型到底藏着啥“绝活”,谁又能帮你在业务上“冲锋陷阵”。

1. GPT系列(OpenAI):万亿参数的“全能冠军”
- 背景:
微软力挺的OpenAI研发,GPT-3验证了“规模越大,能力越强”。到了GPT-4,更是引入了“混合专家系统”(MoE),简单讲,就是把一个超级大的模型拆成很多个小专家,有任务来了,只让最擅长的小专家出来干活,效率高,成本还低。
- 技术亮点:
- MoE加持:
GPT-4采用稀疏激活的MoE架构,1.8万亿参数中每次只激活约10%的子网络,实现了万亿级参数的高效推理,训练成本降低40%。这就像一个巨大的公司,每次只调动最相关的小组去完成任务,避免了“大而全”的低效。
- 多模态实时交互:GPT-4o
支持文本、图像、音频同步输入输出,响应延迟低至232ms,能进行实时情感分析和跨模态理解(比如通过呼吸频率识别用户情绪)。这让AI交流更像人与人对话。
- MoE加持:
- 生态合作与优势:
- 微软Copilot:
最成功的案例就是微软的Copilot,将GPT能力深度融入Office、Azure等产品。它让Excel分析数据、Word写报告、PowerPoint做演示都变得超级简单。
- 行业绑定优势:
通过与微软庞大且成熟的生态系统深度绑定,OpenAI的模型得以触达海量企业和个人用户,加速了AI技术的普及和应用。这意味着企业可以在熟悉的微软环境下,直接获得顶尖AI能力,极大地降低了AI应用的门槛和部署成本。
- 微软Copilot:
2. Gemini(Google):原生多模态的“多面手”

- 背景:
谷歌DeepMind团队出品,全球首个原生多模态大模型,从一开始就为了同时处理文本、图像、音频、视频等多种数据而生。
- 技术亮点:
- Pathways统一架构:
统一处理文本、图像、音频、视频,多模态推理延迟降低50%。这就像一个大脑能同时处理视觉、听觉等多种信息。
- TPU v5优化:
结合谷歌自研芯片,算力超强,MMLU测试得分90.0%,首次超越人类专家。
- 轻量化部署:Nano版本
仅18亿参数,能在移动设备上运行,内存占用<2GB,功耗低于1W。这意味着AI能力能直接“装进”手机。
- Pathways统一架构:
- 生态合作与优势:
- Google Cloud AI:
Gemini与Google Cloud紧密结合,为企业提供强大的AI解决方案。零售商可用Gemini分析视频监控优化店面,媒体公司可自动生成内容。
- 行业绑定优势:
作为谷歌云服务生态的核心组成部分,Gemini拥有强大的数据处理能力和云计算资源。对于需要处理大量多模态数据(如视频分析、内容创作)的企业,Gemini提供了端到端且高效的AI服务,其轻量化版本也为移动端应用提供了独特优势。
- Google Cloud AI:
3. AWS Bedrock(Anthropic):安全合规的“企业卫士”

- 背景:
Anthropic开发的Claude模型,通过AWS Bedrock平台提供服务,主打安全合规。
- 技术亮点:
- 宪法AI框架:
通过自我监督学习和人类反馈循环,有害内容生成率降低至0.02%,并通过ISO 27001合规认证。对数据敏感行业是福音。
- 无缝集成AWS生态:
支持与S3(存储)、Lambda(计算)、DynamoDB(数据库)联动,实现数据存储→处理→推理全流程自动化。
- 低成本微调:
基于SageMaker的模型微调方案,企业定制化训练成本降低70%。
- 宪法AI框架:
- 应用场景与客户:
- 高盛(金融合规):
采用Bedrock私有化部署,实现交易风险实时监测,误报率<0.5%。
- 梅奥诊所(医疗文档处理):
使用Claude模型自动生成患者诊疗报告,准确率98%。
- 高盛(金融合规):
- 生态合作与优势:
- 行业绑定优势:
AWS Bedrock与亚马逊庞大的云计算生态系统深度融合,为客户提供了安全、可扩展且易于部署的大模型服务。对于对数据安全、隐私保护和合规性有极高要求的金融、医疗等行业,Bedrock是优选。它能确保AI应用在受控且高度安全的环境下运行,最大限度降低潜在风险。
- 行业绑定优势:
4. DeepSeek(深度求索):性价比之王

- 背景:
深度求索团队打造,以极高的成本效益和卓越性能著称。
- 技术亮点:
- 动态MoE架构:
6710亿参数中仅激活37亿,推理成本仅为GPT-3的1/8,支持128K上下文处理。省钱又高效!
- 时序数据分析引擎:
金融场景中股价预测误差率<3%,支持多因子联合建模(如宏观经济指标+行业数据)。
- 工业级多模态:
图像缺陷检测精度达99.7%,漏检率<0.3%(宁德时代电池产线实测)。工业界“火眼金睛”!
- 动态MoE架构:
- 应用场景与客户:
- 某银行(金融风控):
信贷报告生成成本从1.2元/份降至0.15元/份,日均处理10万+笔申请。
- 北京协和医院(医疗诊断):
引入DeepSeek-R1模型,相似病例检索准确率提升45%。
- 某银行(金融风控):
- 生态合作与优势:
- 行业绑定优势:
DeepSeek凭借其卓越的成本效益和垂直行业(金融、工业)解决方案,在特定领域展现出强大竞争力。它为企业提供了高性能、低成本的AI能力,帮助企业在复杂业务场景中实现精细化管理和决策优化,直接驱动降本增效。
- 行业绑定优势:
5. 百度文心(ERNIE):最懂中文的“智囊团”

- 背景:
百度研发,在中文领域有深厚积累,主打知识增强。
- 技术亮点:
- 知识增强预训练:
融合5500亿实体知识图谱,中文事实性错误率降至3.2%。更靠谱,不“胡说”!
- 检索增强生成(RAG):
通过搜索引擎实时获取时效性数据,问答准确率提升25%(如股票价格查询)。信息实时更新!
- 零样本生成:
无需示例即可生成合规内容,企业场景适配效率提升70%。快速上手!
- 知识增强预训练:
- 应用场景与客户:
- 京东(电商客服):
采用文心大模型实现商品详情页自动生成,转化率提升18%。
- 北京市政务系统(政务问答):
接入文心一言,日均处理3万+市民咨询,解决率92%。
- 京东(电商客服):
- 生态合作与优势:
- 行业绑定优势:
百度文心在中文语境下拥有无可比拟的优势,其深度融合知识图谱和实时检索能力,为中文用户和企业提供了精准、高效的AI服务。在政务、电商、媒体等需要处理大量中文内容和知识的领域,文心大模型通过智能化解决方案,帮助企业提升效率和用户体验,尤其适合中国本土市场。
- 行业绑定优势:
6. 阿里通义(Qwen):多语言的“翻译官”
- 背景:
阿里云出品,强调多语言覆盖和高效语音处理。
- 技术亮点:
- 混合推理架构:
支持“深度思考”与“即时响应”双模式,复杂任务处理时间缩短60%(如供应链优化)。
- 多语言覆盖:
支持119种语言交互,阿拉伯语客服场景响应准确率95%。跨境业务必备!
- Paraformer语音模型:
非自回归端到端识别,语音转写效率提升10倍,错误率<2%。会议纪要神器!
- 混合推理架构:
- 应用场景与客户:
- SHEIN(跨境电商):
使用通义千问实现多语言客服自动化,人力成本降低50%。
- 钉钉(会议记录):
集成通义听悟,实时生成会议纪要与待办事项,用户覆盖超1000万企业。
- SHEIN(跨境电商):
- 生态合作与优势:
- 行业绑定优势:
阿里通义凭借其强大的多语言处理能力和与阿里自身生态(电商、企业协作)的深度集成,成为跨境业务和企业内部协作领域的佼佼者。它为客户提供了高效的自动化解决方案,帮助企业拓展全球市场,提升内部沟通效率,尤其在国际化运营和大型企业协同中优势明显。
- 行业绑定优势:
7. 商汤日日新(SenseNova):工业视觉的“火眼金睛”

- 背景:
商汤科技,在计算机视觉领域深耕多年,其大模型系列主打视觉处理和多模态融合。
- 技术亮点:
- 原生模态融合:
通过逆渲染与语义生成技术合成多模态训练数据,图文联合理解准确率提升35%。
- 工业级视觉处理:
支持0.01mm级缺陷检测(如汽车焊接点质检),误报率<0.3%。精度达到极致!
- 低延迟推理:
自动驾驶场景响应时间<200ms,支持实时障碍物识别与路径规划。反应速度快!
- 原生模态融合:
- 应用场景与客户:
- 三一重工(智能制造):
采用日日新模型实现设备预测性维护,故障预测准确率92%。
- 工商银行(金融文档处理):
部署日日新系统,合同审查效率提升8倍。
- 三一重工(智能制造):
- 生态合作与优势:
- 行业绑定优势:
商汤日日新在工业视觉处理和高精度检测方面表现卓越,与智能制造、工业自动化和安防行业高度契合。商汤科技深厚的计算机视觉和工程落地经验,使得日日新能为企业提供精准、高效的视觉AI解决方案,帮助企业实现生产过程的智能化升级,提升良品率和设备稼动率。
- 行业绑定优势:
8. MiniMax:创意无限的“内容工厂”

- 背景:
MiniMax专注于多模态生成和长文本处理,在内容创作领域表现突出。
- 技术亮点:
- 闪电注意力机制:
线性复杂度处理128K长文本,推理速度提升3倍,成本降低90%。
- 视频生成优化:
支持1080P视频生成,单帧渲染时间<50ms(对比Sora降低70%)。生成视频又快又好!
- 多模态对齐:
文本→图像→音频跨模态生成一致性达89%,支持方言语音合成(如四川话)。创作更生动!
- 闪电注意力机制:
- 应用场景与客户:
- 某电商平台(广告创意):
使用MiniMax生成500+广告变体,点击率提升23%。
- 爱奇艺(影视制作):
引入video-01模型,短视频制作周期从3天压缩至2小时。
- 某电商平台(广告创意):
- 生态合作与优势:
- 行业绑定优势:
MiniMax以其高效的内容生成能力和多模态创作优势,成为广告、影视、媒体和创意产业的“秘密武器”。它帮助企业快速生成高质量、多样化的内容,提升营销效果和生产效率,尤其在个性化内容营销和短视频制作方面优势明显。
- 行业绑定优势:
9. 智谱(GLM):开源世界的“先行者”
- 背景:
智谱AI研发,国内首个全栈开源的大模型系列,强调低幻觉率和轻量化部署。
- 技术亮点:
- 全栈开源:
国内首个开源基座模型+多模态+智能体框架,支持私有化部署与二次开发。开放性强,可定制!
- 低幻觉率:
通过知识蒸馏与参数约束,事实性错误率国内最低(<1.5%)。不“胡说八道”!
- 轻量化Agent:
GLM-PC智能体内存占用<500MB,支持本地化运行(如工业边缘设备)。
- 全栈开源:
- 应用场景与客户:
- 成都“诸葛大模型”(政务智能化):
实现政务流程自动化,日均处理10万+审批事项。
- 开发者生态:
70万开发者通过开放平台调用GLM API,日均tokens调用量120亿。
- 成都“诸葛大模型”(政务智能化):
- 生态合作与优势:
- 行业绑定优势:
智谱以其开源策略和极低的幻觉率,吸引了大量开发者和企业。它为客户提供了高度灵活和可定制的AI解决方案,特别适合那些希望自主掌控技术栈、进行深度二次开发或私有化部署的企业。在政务、金融等对数据主权和准确性要求高的领域,智谱的优势尤为突出。
- 行业绑定优势:
对比参数表图(仅供参考,详见官网数据)
|
服务商 |
代表模型 |
性能:Tokens/秒 (t/s) 和响应延迟 (例如,TTFT,单位:秒) |
定价模型:每Token (输入/输出,美元/MTok) |
|
OpenAI |
GPT-4o, GPT-4.1, GPT-4.1 mini, GPT-4.1 nano |
GPT-4o: ~100-180 t/s; ~0.5-0.6秒 TTFT。 GPT-4.1: ~103-133 t/s; ~0.52-0.81秒 TTFT (极大上下文时更长)。 GPT-4.1 mini: ~238 t/s。 GPT-4.1 nano: ~115-280 t/s; ~0.47秒 TTFT。 (性能因提供商/基准测试而异) |
GPT-4o: $2.50 / $10.00。 GPT-4.1: $2.00 / $8.00 (缓存输入: $0.50)。 GPT-4.1 mini: $0.40 / $1.60 (缓存输入: $0.10)。 GPT-4.1 nano: $0.10 / $0.40 (缓存输入: $0.025)。 GPT-4: $30/$60或更高。 GPT-3.5 Turbo: ~$0.50/$1.50。 |
|
Google Gemini (谷歌 Gemini) |
Gemini 2.5 Pro |
Gemini 2.5 Pro (Google直供): ~153 t/s; ~33秒 TTFT (其他模型如Flash快得多,例如~0.25秒 TTFT) |
Gemini 2.5 Pro: $2.50 / $15.00。 Gemini 2.0 Flash (2025年5月): $0.26/MTok (混合)。 Gemini 1.5 Flash: $0.35 / $0.70 (针对<128k上下文,存在其他层级)。 |
|
Anthropic Claude |
Claude Opus 4, Claude Sonnet 4, Claude 3 Haiku |
Sonnet 4:性能可能与Claude 3.5 Sonnet相似或更好 (~80 t/s; ~0.7-1.6秒 TTFT)。 Opus 4:性能可能与Claude 3 Opus相似或更好 (~25-55 t/s; ~1-2.7秒 TTFT)。 Claude 4模型的具体t/s和TTFT在先前数据中尚未进行基准测试,但定位为功能更强。 |
Claude Opus 4: $15.00 / $75.00。 Claude Sonnet 4: $3.00 / $15.00。 Claude 3 Haiku: $0.25 / $1.25。 |
|
AWS (Bedrock) (亚马逊云科技 Bedrock) |
托管各种模型 (例如, Claude 4, Llama, Titan, Cohere, Mistral, Amazon Nova) |
因模型而异。例如,Amazon Nova Pro: ~167 t/s; ~0.36秒 TTFT。 |
因模型提供商而异。例如,Titan Text Lite: $0.0003/$0.0006。 Llama 3 8B: $0.0004/$0.0004。 Bedrock上的Claude Sonnet 4: $3.00/$15.00。 Bedrock上的Claude Opus 4: $15.00/$75.00。(输入/输出每1k/1M Tokens,按需转换) |
|
Alibaba Cloud (阿里云) |
Qwen系列 (例如, Qwen2.5-Max, Qwen-Long) |
阿里云Qwen3 235B: ~52 t/s; ~1.23秒 TTFT。 Qwen2.5 Max: ~42 t/s, ~1.29秒 TTFT。 |
Qwen-Long: ~$0.07/MTok。Qwen-Max: $1.60 / $6.40。Qwen-VL-Max: ~$0.42/MTok。价格可能迅速变化。 |
|
Baidu (百度) |
ERNIE系列 (例如, ERNIE 4.5, Speed, Lite, X1) |
ERNIE 4.5的性能据称与GPT-4.5持平或更高。API的具体t/s和延迟信息不一致。 |
ERNIE 4.5: $0.55 / $2.20。ERNIE X1: $0.28 / $1.12。ERNIE Speed 和 Lite模型于2024年5月宣布免费使用 (API)。 |
|
Zhipu AI (智谱AI) |
GLM系列 (例如, GLM-4-Plus, GLM-4-Long, GLM-4-Air) |
GLM-Z1-32B-0414声称达到200 t/s (在消费级GPU上,不一定是API性能)。其他API性能t/s和延迟未指明。 |
GLM-4-Plus: ~$0.70/MTok。 GLM-4-Air: ~$0.07/MTok。GLM-4-Long: ~$0.14/MTok。 GLM-4-FlashX: ~$0.014/MTok。 部分模型免费 (GLM-4-Flash)。 |
|
MiniMax (名之梦) |
MiniMax-Text-01 |
~30 t/s; ~0.93秒 TTFT |
MiniMax-Text-01: 混合价格$0.42/MTok。(输入/输出细分未指明) |
|
SenseTime (商汤科技) |
SenseNova 5.0 / 5.5 |
边缘模型 (SenseChat Lite-5.5): 90.2 字/秒; 0.19秒推理时间。云API t/s和延迟未指明。 |
SenseChat (网页版) 免费。API通过云平台进行商业化。 “Project $0 Go”为企业提供50M Token的免费套餐。 边缘模型:约$1.39/设备/年。具体的API $/MTok未详细说明。 |
需求类型对比表
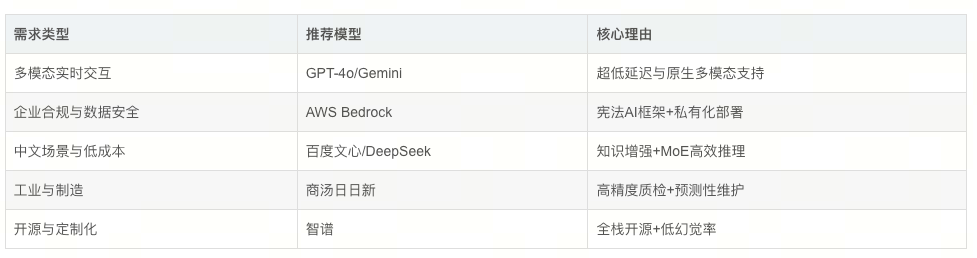
二、行业应用场景深度解析:你的业务,该选谁?
了解了模型特点,再看看它们在真实行业里是怎么大显身手的。
1. 企业级服务场景:效率与合规并重
- AWS Bedrock(Claude):
- 合规文档处理:
支持200+法律条款自动比对,金融合同审核效率提升6倍。想想银行、律所每天海量的合同,这能省多少事!
- 私有化部署案例:
摩根士丹利采用Bedrock私有化方案,风控模型推理延迟**<50ms**。速度就是金钱,尤其在金融领域。
- 合规文档处理:
2. 工业智能化场景:精度与预测是关键
- 商汤日日新:
- 工业质检:
在宁德时代电池产线实现0.01mm级缺陷检测,误报率<0.3%。肉眼难辨的瑕疵,AI能精准发现。
- 预测性维护:
三一重工设备故障预测准确率达92%,运维成本降低40%。提前预知设备“生病”,避免停产大损失。
- 工业质检:
3. 内容创作场景:创意与速度双赢
- MiniMax:
- 短视频生成:
支持1080P视频+AI配音+字幕自动生成,单条内容制作耗时从3小时压缩至10分钟。MCN机构和营销团队的福音!
- 广告投放优化:
通过AIGC生成500+创意变体,某电商CTR(点击率)提升23%。直接提升了营销效果。
- 短视频生成:
三、选型建议
1. 技术选型决策树
是否需要多模态?
├─ 是 → Gemini/日日新
└─ 否 →
是否强调中文能力?
├─ 是 → 文心/智谱
└─ 否 →
是否要求低成本?
├─ 是 → DeepSeek
└─ 否 → GPT-4/Claude
2. 性能调优建议:针对性选择,效果更好
- 长文本处理:
如果你的业务需要处理大量文本(比如法律文档、研究报告),优先选择支持128K上下文的MiniMax。
- 实时性要求:
如果是自动驾驶、实时客服这种对响应速度有极高要求的场景,商汤日日新在200ms级响应,非常适合。
- 合规性要求:
如果你的行业(比如医疗、金融、政务)对数据安全和合规性有严格要求,**AWS Bedrock(ISO 27001认证)和智谱(低幻觉率,支持私有化)**更值得信赖。
大模型的真正价值,在于它如何与具体行业的需求深度绑定,如何解决实际痛点,并最终创造出实实在在的商业价值。
行业绑定的优势:不仅是效率,更是变革
那么,这种深度绑定,到底给行业带来了哪些优势呢?
首先,是效率的极致提升。无论是客服、文档处理、内容生成,还是工业质检、金融风控,大模型都能以远超人类的速度和精度完成任务,从而大幅降低人力成本,缩短业务周期。信贷报告从1.2元降到0.15元,会议纪要从3小时到10分钟,这些都是直观的体现。
其次,是决策的智能化与精准化。大模型能从海量数据中提炼洞察,辅助企业做出更科学的决策。金融领域的风险预测、工业领域的设备维护预警,都让企业从“亡羊补牢”走向“未雨绸缪”。
第三,是创新的加速与拓展。当重复性工作被AI接管,人类的精力得以解放,可以投入到更具创造性、更需要人文关怀的工作中。MiniMax在广告创意上的表现,就是大模型赋能内容创新的一个缩影。它让“千人千面”的个性化营销成为可能。
最后,也是最深刻的一点,是行业生态的重塑。大模型不再仅仅是工具,它正在成为一种新型的生产要素和基础设施。谁能更好地利用大模型,谁就能在未来的竞争中占据优势。这不仅仅是技术之争,更是生态位之争。

















 1021
1021

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









