




作者:孟繁续,北大博士生
https://zhuanlan.zhihu.com/p/1899780517433421976
加入青稞AI技术交流群,与青年AI研究员/开发者交流最新AI技术
文章链接: https://arxiv.org/abs/2502.07864
代码链接:https://github.com/fxmeng/TransMLA
开源模型:https://huggingface.co/collections/fxmeng
作者:孟繁续,汤平之,唐小娟,姚增伟,孙星,张牧涵
前言
年初我们发布了初版的TransMLA,理论证明了DeepSeek中使用的Multi-Head Latent Attention(MLA)的表达能力超过目前广泛使用的Group-Query Attention(GQA)。证明思路为GQA能够等价转换为MLA,反之无法用GQA表示所有的MLA。文章将GQA模型等价转化为MLA模型,然后分别微调GQA和MLA模型,发现MLA能够获得更好的微调效果,实验验证了MLA和GQA的表达能力差异。
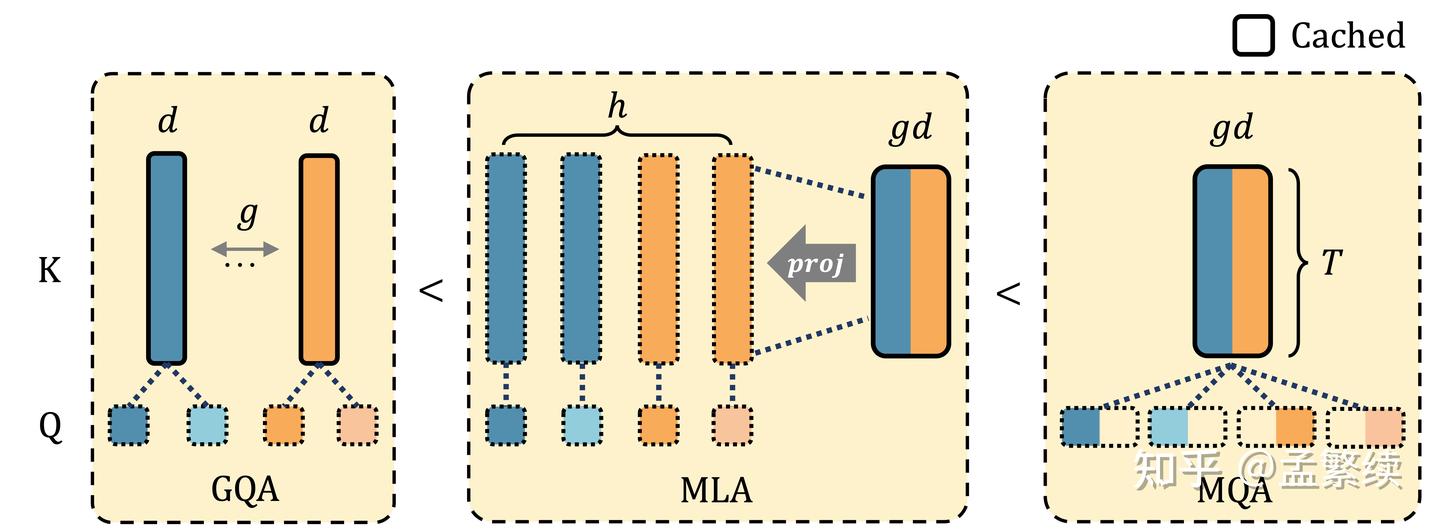
初版TransMLA获得了很好的社区反馈。在取得了一些关注后,我们继续挖掘TransMLA的价值。初版TransMLA并不减少模型的KV Cache,因此并不能提升推理速度,只能通过等价变换提升GQA模型的表达能力,阻碍了TransMLA的实际应用价值。
本次更新,我们实现了三大目标:
- 1)压缩大部分的KV Cache;
- 2)尽可能减少性能损失;
- 3)直接使用DeepSeek的代码进行推理,不依赖特殊的优化即在任何硬件上实现加速。
在TransMLA之前,其实Palu已经达成了1)和2)两个目标,Palu直接将k_proj和v_proj拼接起来,进行低秩压缩,得到kv_a_proj和k_b_proj以及v_proj进行attention计算。然而,RoPE的存在,阻碍了Palu实现目标3)。Palu需要将RoPE放在升维后的k_b_proj每个头之后,阻止了k_b_proj吸收进q_proj中。因此推理时必须将key还原为多个头,导致更多的访存操作。
另外由于不能合并进KV Cache中,每生成一个token均需要对所有K执行RoPE这一碎片化操作,也拖慢了计算速度。和TransMLA同时期的工作MHA2MLA,同样尝试将MHA转为MLA,但却遗憾未能实现目标2)和3)。
TransMLA
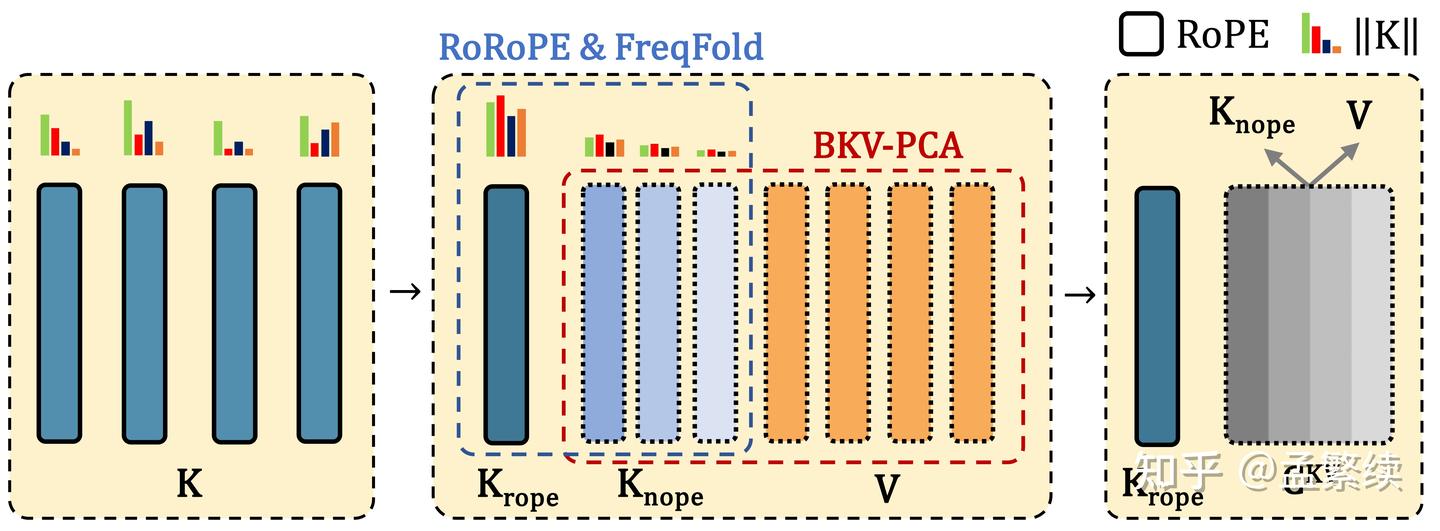
TransMLA能够实现1)2)3)三个目标,归功于如图所示的三项创新技术:RoRoPE和FreqFold用于去除 K中大部分head的位置编码;BKV-PCA能够将 K n o p e K_{nope} Knope 与V联合进行低秩压缩。
Grouped Heads to a Latent Representation
证明MLA的表达能力大于GQA的核心以及TransMLA的第一步,是将GQA中分组的多个注意力头,合并为一个MLA的潜在表示。
[
c
t
K
;
c
t
V
]
=
c
t
K
V
=
W
D
K
V
x
t
,
W
D
K
V
=
[
W
K
;
W
V
]
∈
R
2
g
d
×
D
,
[\mathbf{c}_{t}^{K}; \mathbf{c}_{t}^{V}]=\mathbf{c}_{t}^{KV} = W^{DKV} \mathbf{x}_{t},~~W^{DKV} = [W^K; W^V] \in \mathbf{R}^{2gd\times D},
[ctK;ctV]=ctKV=WDKVxt, WDKV=[WK;WV]∈R2gd×D,
[
q
t
,
1
;
q
t
,
2
;
.
.
.
;
q
t
,
h
]
=
q
t
=
W
Q
x
t
,
W
Q
∈
R
h
d
×
D
,
\\ [\mathbf{q}_{t, 1};\mathbf{q}_{t, 2};...;\mathbf{q}_{t, h}] = \mathbf{q}_{t} = {W^{Q}} \mathbf{x}_{t}, ~~{W^{Q}}\in \mathbf{R}^{hd\times D},
[qt,1;qt,2;...;qt,h]=qt=WQxt, WQ∈Rhd×D,
W
i
U
K
[
:
,
k
]
=
{
I
d
if
k
∈
[
j
d
,
(
j
+
1
)
d
)
,
j
=
⌈
i
h
/
g
⌉
−
1
0
otherwise
,
W
i
U
K
∈
R
d
×
g
d
,
\\ W^{UK}_i[:, k]= \begin{cases} I_d & \text{if } k \in [jd, (j{+}1)d),\ j = \left\lceil \frac{i}{h/g} \right\rceil - 1 \\ 0 & \text{otherwise} \end{cases}, \quad W^{UK}_i \in \mathbb{R}^{d \times gd},
WiUK[:,k]={Id0if k∈[jd,(j+1)d), j=⌈h/gi⌉−1otherwise,WiUK∈Rd×gd,
q
^
t
,
i
R
=
RoPE
^
t
(
W
i
U
K
⊤
q
t
,
i
)
,
k
^
t
R
=
RoPE
^
t
(
c
t
K
)
,
v
^
t
=
c
t
V
,
\\ \mathbf{\hat{q}}_{t, i}^R = \widehat{\text{RoPE}}_t\left(W_i^{{UK}^\top}\mathbf{q}_{t, i}\right), ~~\mathbf{\hat{k}}_t^R=\widehat{\text{RoPE}}_t\left(\mathbf{c}_{t}^K\right),~~\mathbf{\hat{v}}_t=\mathbf{c}_{t}^V,
q^t,iR=RoPE
t(WiUK⊤qt,i), k^tR=RoPE
t(ctK), v^t=ctV,
o
^
t
,
i
=
∑
j
=
1
t
softmax
j
(
q
^
t
,
i
R
⊤
k
^
j
R
d
)
v
^
j
,
\\ \mathbf{\hat{o}}_{t, i} = \sum_{j=1}^{t} \text{softmax}_j\left(\frac{\mathbf{\hat{q}}_{t, i}^{R^\top}\mathbf{\hat{k}}_{j}^R}{\sqrt{d}}\right) \mathbf{\hat{v}}_{j},
o^t,i=j=1∑tsoftmaxj
dq^t,iR⊤k^jR
v^j,
y t = W O [ W 1 U V o ^ t , 1 ; . . . ; W h U V o ^ t , h ] , W i U V = W i U K ∈ R d × g d . \\ \mathbf{y}_{t} = W^{O} [W^{UV}_1\mathbf{\hat{o}}_{t, 1};...;W^{UV}_h\mathbf{\hat{o}}_{t, h}], \quad W^{UV}_i=W^{UK}_i\in \mathbb{R}^{d \times gd}. yt=WO[W1UVo^t,1;...;WhUVo^t,h],WiUV=WiUK∈Rd×gd.
其中 W i U K W^{UK}_i WiUK 将第 i i i 个 Q Q Q 和第 j = ⌈ i h / g ⌉ − 1 j = \left\lceil \frac{i}{h/g} \right\rceil - 1 j=⌈h/gi⌉−1 个K映射到一起, W i U V W^{UV}_i WiUV 也采用同样的初始化方式,一起起到GQA中repeat_kv的作用。由于所有的K现在已经被合并,对应的RoPE也要整合为一个统一的算子,记作 RoPE ^ \widehat{\text{RoPE}} RoPE 。由于原来每个头使用的是相同的 RoPE 模式,$ \widehat{\text{RoPE}}$ 实质上只是在每隔 d 维重复相同的操作。其中, W i U K W^{UK}_i WiUK 和 q t , i 相乘, W i U V a n d o ^ t , i \mathbf{q}_{t, i}相乘,W^{UV}_i and \mathbf{\hat{o}}_{t, i} qt,i相乘,WiUVando^t,i 相乘,从而保证转换完的模型能够支持MLA的absorb操作,在计算密集和访存密集模式之间自由切换。
Head-wise Rotation for Decoupled RoPE
直接将Grouped Heads 转换为 Latent Representation不会减少KV Cache,因此也不能提升推理速度。利用MLA的高表达能力,对其进行低秩压缩,从而能够达成效率和效果的平衡。然而由于RoPE对不同的token和维度乘上不同的系数,直接对KV使用主成分分析进行旋转,会破坏模型的效果。 RoRoPE证明可以在 RoPE ^ \widehat{\text{RoPE}} RoPE 两端对QK进行旋转,只要满足:
- 1)旋转只发生在不同K head的相同维度
- 2) RoPE ^ \widehat{\text{RoPE}} RoPE 的实部和虚部对应的维度需要使用相同的旋转方式。
RoRoPE通过这一特殊旋转方式将K的主成分集中到一个注意力头中,重新使用一个标准的RoPE表示位置信息。
如图3所示,由于多个head已经合并,改变其维度的计算顺序并不会影响结果,因此将相同的频率放在一起进行计算:
q ^ t , i R ⊤ k ^ j = ∑ l = 1 d / 2 RoPE ^ t ( [ q ^ t , i [ 2 l − 1 : : d ] ; q ^ t , i [ 2 l : : d ] ] ) ⊤ RoPE ^ t ( [ k ^ j [ 2 l − 1 : : d ] ; k ^ j [ 2 l : : d ] ] ) . \mathbf{\hat{q}}_{t, i}^{R^\top}\mathbf{\hat{k}}_{j} = \sum_{l=1}^{d/2} \widehat{\text{RoPE}}_t\left(\left[ {\mathbf{\hat{q}}_{t, i}}^{[2l-1::d]}; \mathbf{\hat{q}}_{t, i}^{[2l::d]} \right]\right)^\top \widehat{\text{RoPE}}_t\left(\left[\mathbf{\hat{k}}_j^{[2l-1::d]}; \mathbf{\hat{k}}_j^{[2l::d]} \right]\right). q^t,iR⊤k^j=l=1∑d/2RoPE t([q^t,i[2l−1::d];q^t,i[2l::d]])⊤RoPE t([k^j[2l−1::d];k^j[2l::d]]).
这里符号 [ 2 l − 1 : : d ] 和 [ 2 l : : d ] [2l-1::d]和[2l::d] [2l−1::d]和[2l::d] 类似 Python 切片语法,分别表示每个head的奇数维度(实部)和偶数维度(虚部)。带入RoPE的定义得到:
RoPE ^ t ( [ q ^ t , i [ 2 l − 1 : : d ] ; q ^ t , i [ 2 l : : d ] ] ) = cos t θ l [ q ^ t , i [ 2 l − 1 : : d ] ; q ^ t , i [ 2 l : : d ] ] + sin t θ l [ − q ^ t , i [ 2 l : : d ] ; q ^ t , i [ 2 l − 1 : : d ] ] , RoPE ^ t ( [ k ^ j [ 2 l − 1 : : d ] ; k ^ j [ 2 l : : d ] ] ) = cos j θ l [ k ^ j [ 2 l − 1 : : d ] ; k ^ j [ 2 l : : d ] ] + sin j θ l [ − k ^ j [ 2 l : : d ] ; k ^ j [ 2 l − 1 : : d ] ] . \begin{align} \widehat{\text{RoPE}}_t\left(\left[\hat{\mathbf{q}}_{t,i}^{[2l-1::d]}; \hat{\mathbf{q}}_{t,i}^{[2l::d]}\right]\right) &= \cos t \theta_l \left[ \hat{\mathbf{q}}_{t,i}^{[2l-1::d]}; \hat{\mathbf{q}}_{t,i}^{[2l::d]} \right] + \sin t \theta_l \left[-\hat{\mathbf{q}}_{t,i}^{[2l::d]}; \hat{\mathbf{q}}_{t,i}^{[2l-1::d]} \right], \\ \widehat{\text{RoPE}}_t\left(\left[{ \hat{\mathbf{k}}_j^{[2l-1::d]} }; { \hat{\mathbf{k}}_j^{[2l::d]} }\right]\right) &= \cos j \theta_l \left[ \hat{\mathbf{k}}_j^{[2l-1::d]}; \hat{\mathbf{k}}_j^{[2l::d]} \right] + \sin j \theta_l \left[-\hat{\mathbf{k}}_j^{[2l::d]}; \hat{\mathbf{k}}_j^{[2l-1::d]} \right]. \end{align} \\ RoPE t([q^t,i[2l−1::d];q^t,i[2l::d]])RoPE t([k^j[2l−1::d];k^j[2l::d]])=costθl[q^t,i[2l−1::d];q^t,i[2l::d]]+sintθl[−q^t,i[2l::d];q^t,i[2l−1::d]],=cosjθl[k^j[2l−1::d];k^j[2l::d]]+sinjθl[−k^j[2l::d];k^j[2l−1::d]].
用任意正交矩阵 U l ∈ R g × g \mathbf{U}_l \in \mathbb{R}^{g \times g} Ul∈Rg×g 旋转 q ^ t , i 和 k ^ j \mathbf{\hat{q}}_{t, i} 和 \mathbf{\hat{k}}_j q^t,i和k^j 的第 2 l − 1 2l-1 2l−1 维和第 2 l 2l 2l 维时,结果与 q ^ t , i R ⊤ k ^ j \mathbf{\hat{q}}_{t, i}^{R^\top}\mathbf{\hat{k}}_{j} q^t,iR⊤k^j 相等。具体地:
∑ l = 1 d / 2 RoPE ^ t ( [ U l q ^ t , i [ 2 l − 1 : : d ] ; U l q ^ t , i [ 2 l : : d ] ] ) ⊤ RoPE ^ t ( [ U l k ^ j [ 2 l − 1 : : d ] ; U l k ^ j [ 2 l : : d ] ] ) = q ^ t , i R ⊤ k ^ j R . \sum_{l = 1}^{d / 2} \widehat{\text{RoPE}}_t\left( \left[ \mathbf{U}_l \hat{\mathbf{q}}_{t,i}^{[2l-1::d]}; \mathbf{U}_l \hat{\mathbf{q}}_{t,i}^{[2l::d]} \right] \right)^\top \widehat{\text{RoPE}}_t\left( \left[ \mathbf{U}_l \hat{\mathbf{k}}_j^{[2l-1::d]}; \mathbf{U}_l \hat{\mathbf{k}}_j^{[2l::d]} \right]\right) = \mathbf{\hat{q}}^{R^\top}_{t,i} \mathbf{\hat{k}}_j^R. l=1∑d/2RoPE t([Ulq^t,i[2l−1::d];Ulq^t,i[2l::d]])⊤RoPE t([Ulk^j[2l−1::d];Ulk^j[2l::d]])=q^t,iR⊤k^jR.
由于相同的旋转参数(即 cos t θ l \cos t\theta_l costθl 和 sin t θ l \sin t\theta_l sintθl )被一致地应用到每个注意力 head 的第 l l l 个 2D 子空间中的所有维度,因此任何正交变换 U l ⊤ U l = I \mathbf{U}_l^\top \mathbf{U}_l = \mathbf{I} Ul⊤Ul=I 在同一子空间内作用也不会改变内积 q ^ t , i R ⊤ k ^ j R \mathbf{\hat{q}}^{R^\top}_{t,i} \mathbf{\hat{k}}_j^R q^t,iR⊤k^jR 。
RoRoPE使用小规模数据集,提取K输出,计算其主成分投影矩阵 { U l } l = 1 d / 2 \{\mathbf{U}_l\}_{l=1}^{d/2} {Ul}l=1d/2 ,并按上述方法对 W K W^K WK 和 W U K W^{UK} WUK 进行旋转。 该旋转使得越靠近开头的K head越重要。
至此,将Grouped Heads合并为Latent representation和RoRoPE均为等价操作,不改变模型的效果。为了对KV Cache进行压缩,接下来我们将 K K K 切分为一个重要的 K r o p e H e a d K_{rope} Head KropeHead 和其他不重要的 K n o p e K_{nope} Knope 。 K n o p e K_{nope} Knope 对位置编码的影响很小,直接移除其上的RoPE,模型损失很小。
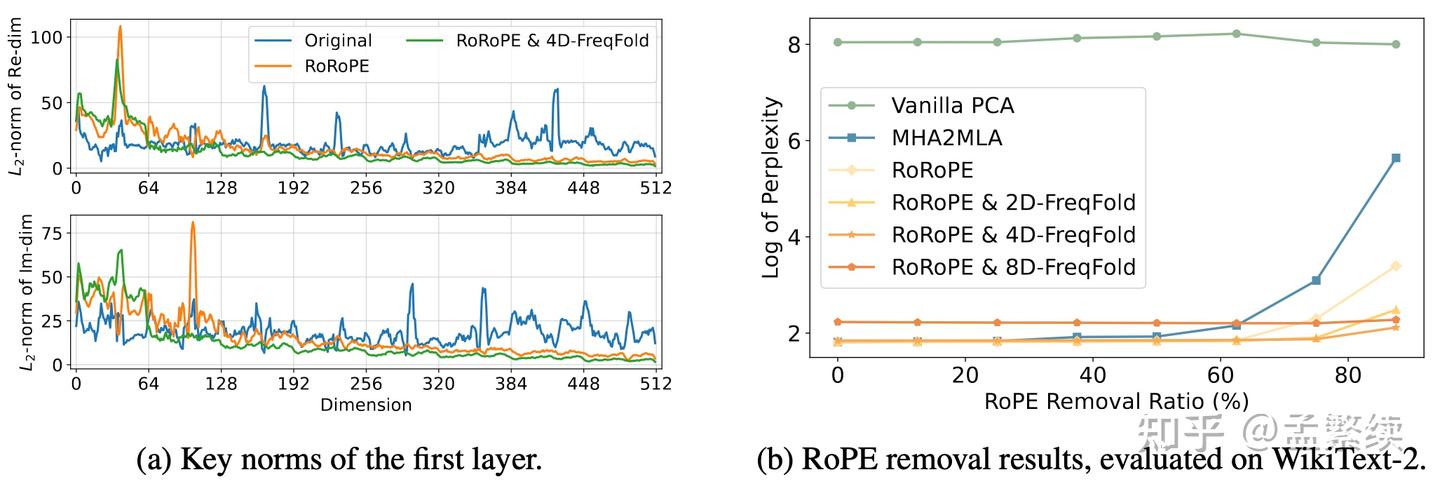
作为对比,MHA2MLA不进行主成分提取,直接去除 ∥ q ∥ ∥ k ∥ \|q\|\|k\| ∥q∥∥k∥ 相对小的维度的位置编码。这一做法不仅误差大,选出来的维度也不规则,因此很难实现加速效果。 如图4(a)所示,使用RoRoPE后输出分布集中在原来的第一个K head。如图4(b)所示,直接使用跨过RoPE进行旋转会显著破坏模型能力;使用RoRoPE裁剪至一个128维的效果显著好于没有进行主成分提取的MHA2MLA。
Frequency Folding
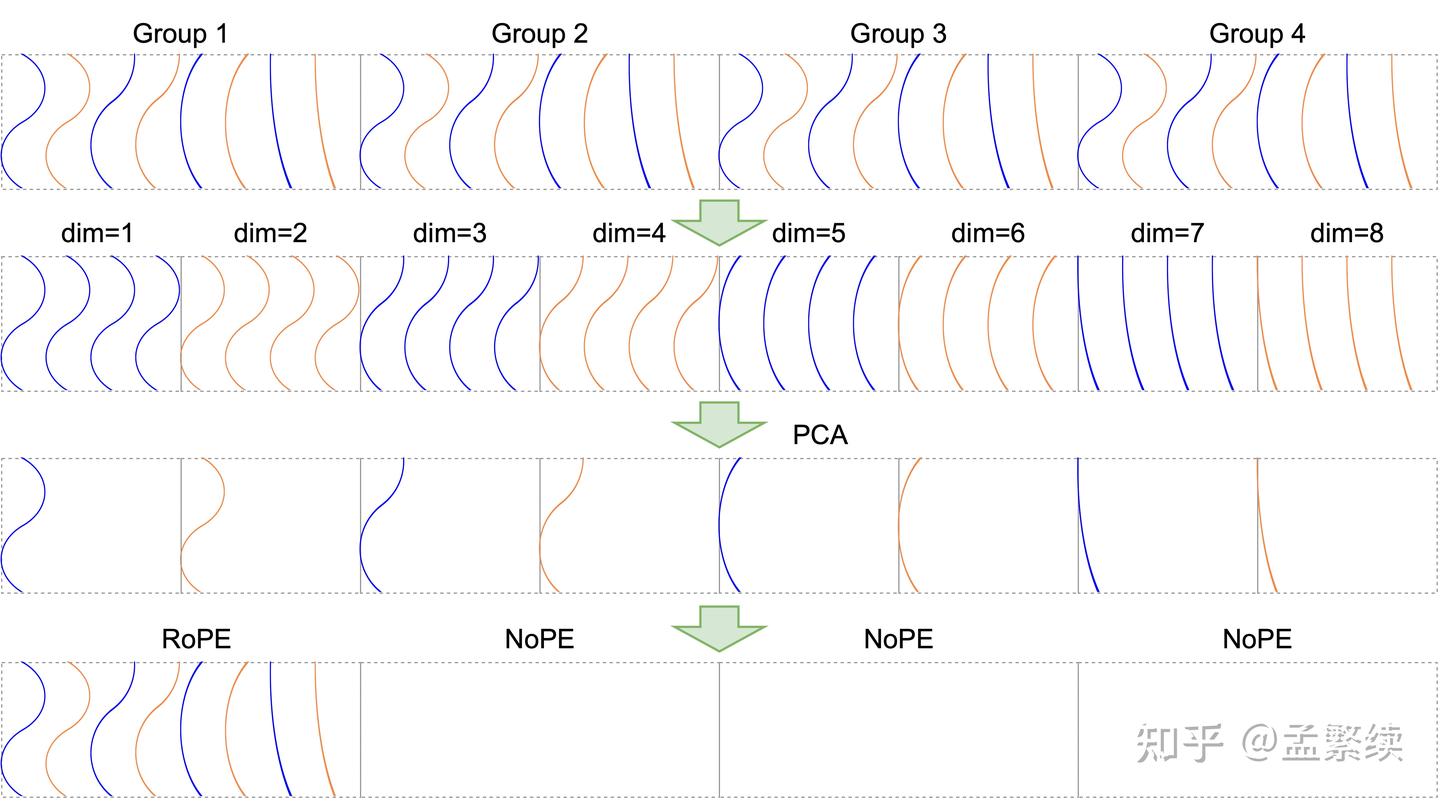
RoRoPE将所有注意力的信息尽可能的集中到第一个注意力头的对应维度,然而使用一维空间表示所有头的信息,加上需要对实部虚部取公共主成分,会存在表达能力不足的情况,为了仍然只使用一个注意力头,却能用更多的维度来存储信息,我们提出了FreqFold方法。如图5所示,FreqFold在相邻的RoPE中频率相近的相邻维度上进行RoRoPE操作,使用更大的空间表示相邻频率的特征。
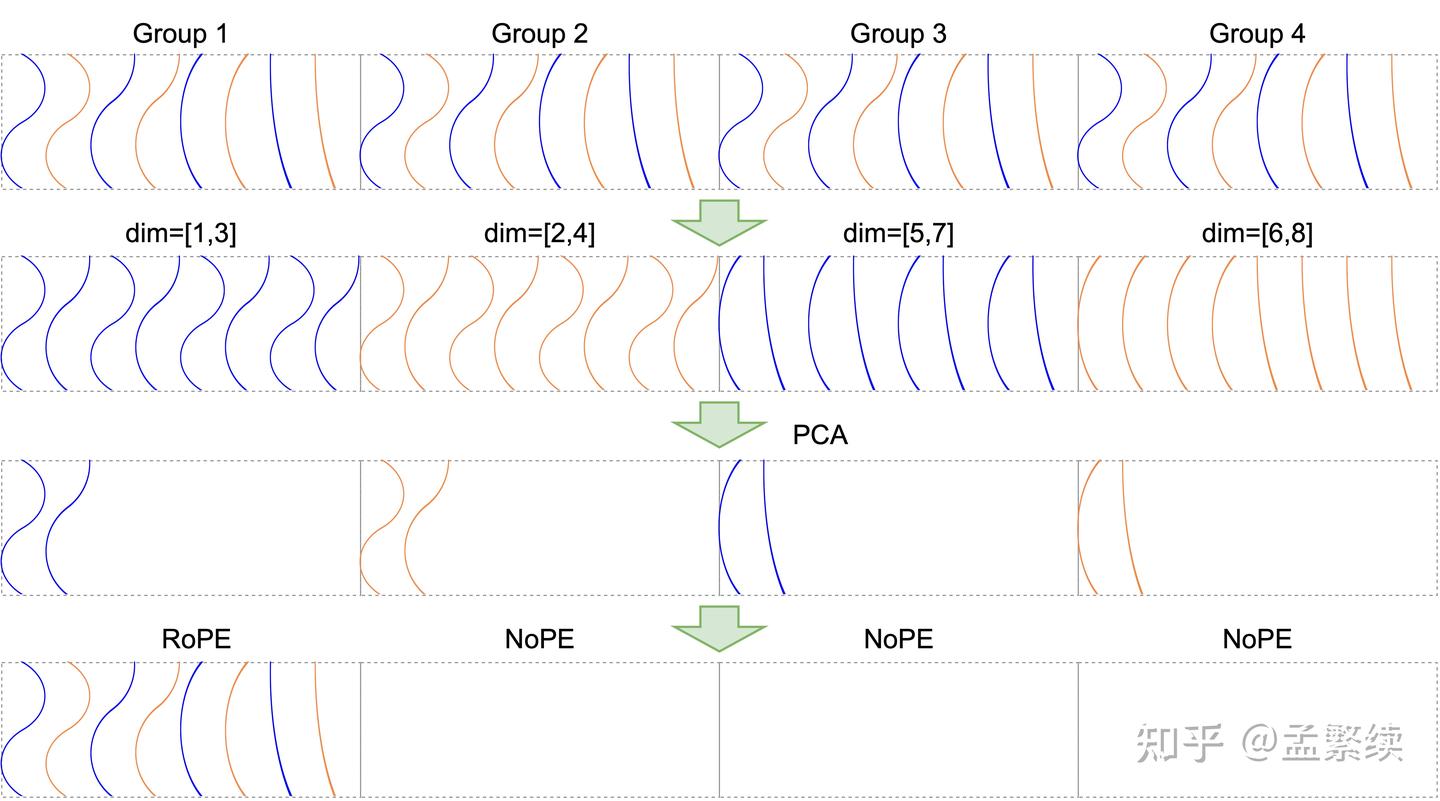
注意FreqFold并不是等价变换,然而由于相邻频率位置编码近似的损失小于直接去掉位置编码的损失,FreqFold能够显著提升RoRoPE的效果。如图4(a)所示,使用FreqFlod后输出分布更集中在原来的第一个 K h e a d K head Khead 了。如图4(b)所示,使用4个相邻频率的维度近似的FreqFold达到了最好的效果;但并不是引入的相邻频率越多越好,当引入8个相邻频率时,由于这8个频率相似度较低,未进行裁剪的时候损失就已经大于4D-FreqFold了。
BKV-PCA
去除RoPE后,需要将 K r o p e K_{rope} Krope 与 V V V 联合进行PCA。但是如图6(a)上所示,我们使用少量数据统计出的 K r o p e K_{rope} Krope 中的向量norm远大于 V V V ,直接进行PCA会导致提取出来的主成分方向都是 K r o p e K_{rope} Krope 的方向, V V V 的信息会大量丢失。因此我们先给 W n o p e D K W^{DK}_{nope} WnopeDK 除掉 α = E t [ ∥ W nope D K x t ∥ 2 ] E t [ ∥ W D V x t ∥ 2 ] \alpha = \frac{\mathbb{E}_t[\|W^{DK}_{\text{nope}} \mathbf{x}_t\|_2]}{\mathbb{E}_t[\|W^{DV} \mathbf{x}_t\|_2]} α=Et[∥WDVxt∥2]Et[∥WnopeDKxt∥2] 。如如图6(a)下, α \alpha α 使 K r o p e K_{rope} Krope 的norm约等于 V V V。为了不改变模型功能,需要在 W U K W^{UK} WUK 乘以 α \alpha α 。
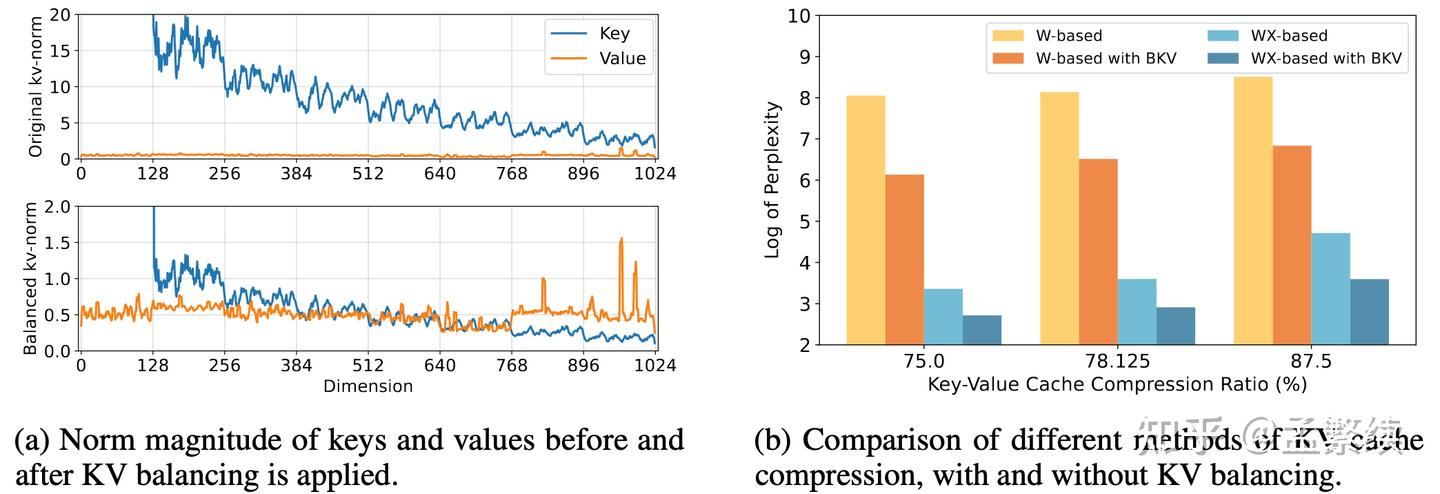
如图6(b)在各种压缩率下,使用KV平衡的方法好于不使用KV平衡的方法。对 K n o p e K_{nope} Knope 和 V V V 进行压缩的方法好于对 W n o p e K W^K_{nope} WnopeK 和 W V W^V WV 压缩的方法。
实验
TransMLA减少转换过程的性能损失,能够轻易通过训练恢复效果
我们在SmolLM-1.7B和LLaMA-2-7B上验证TransMLA的效果,使用同期工作MHA2MLA作为对比。
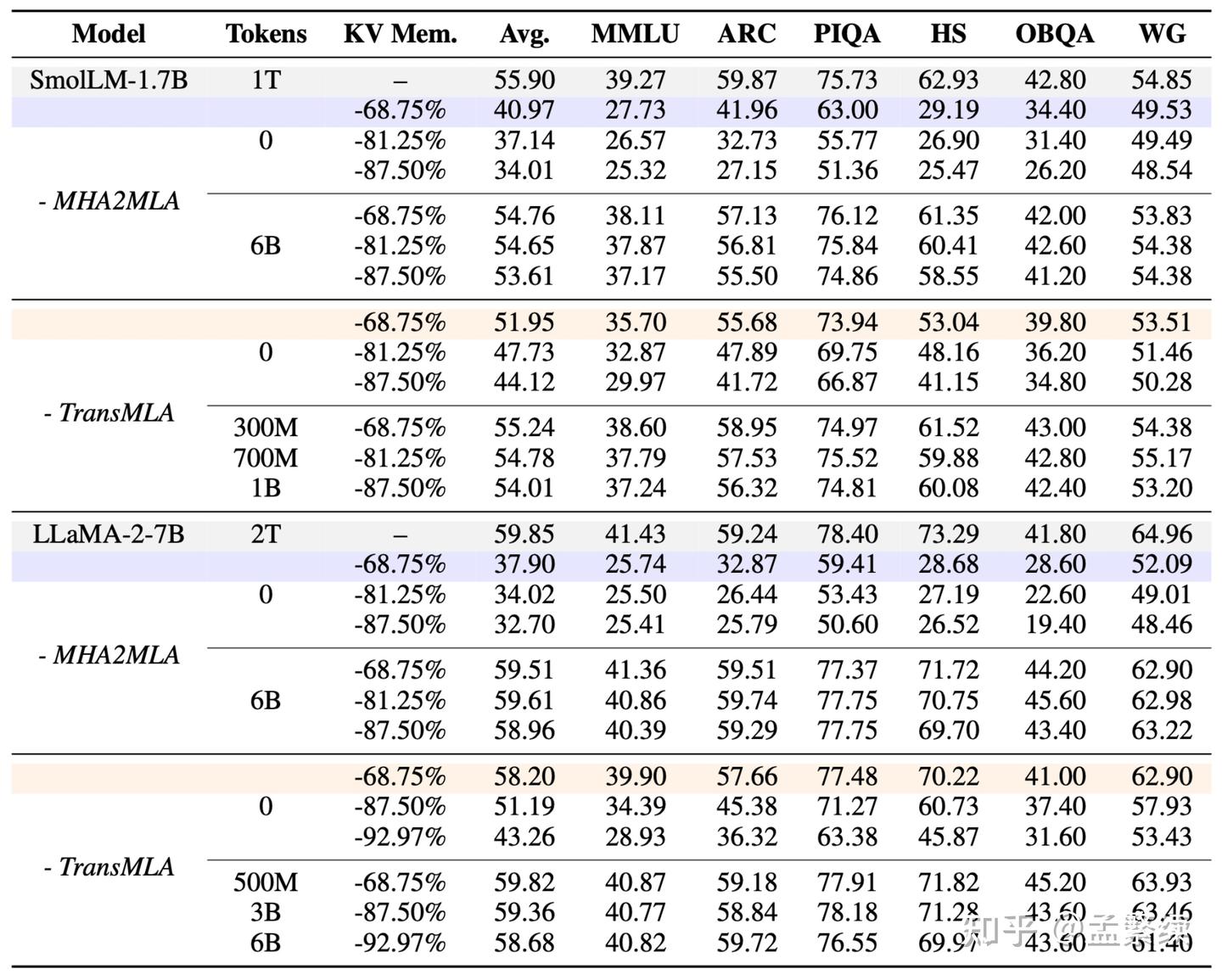
如表1,裁剪LLaMA-2-7B 68.75%的KV Cache,无需训练,在6个benchmark上只损失1.65%的效果,而MHA2MLA则损失约21.85%的效果。TransMLA转换后对模型的破坏更小,因此只使用500M Tokens的训练即可超过使用6B Tokens训练的MHA2MLA。
TransMLA能将GQA模型直接转为DeepSeek模型,轻易的使用vllm加速
不同于其他KV Cache压缩方法需要专门定制推理框架,TransMLA将所有的模型都统一转换为DeepSeek模型。利用其丰富的生态,只要能支持DeepSeek的硬件和环境,就能支持TransMLA的推理加速。目前我们实现了Transformers和vllm版本的代码,未来将会在SGLang等其他框架上进行测试。
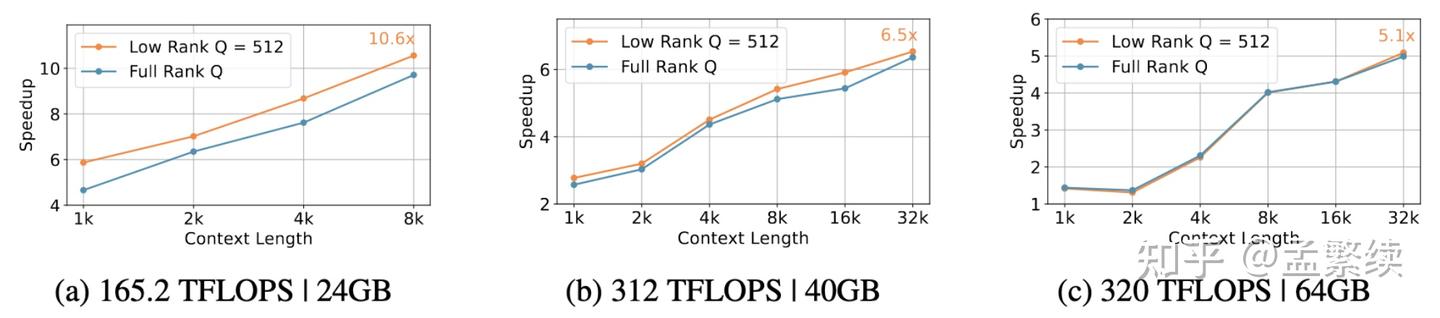
如图7所示,在未使用量化,动态tokens稀疏,投机推理等方法的情况下,仅仅将LLaMA-2-7B转为MLA,就带来了最多10.6x推理加速。未来我们将会结合DeepSeek的混合精度量化,MTP等技术进一步优化模型推理速度。
TransMLA已经支持了主流的模型
TransMLA能够能够轻易支持各种MHA/GQA的模型结构转换,未来将会支持更多模型的转换。转换的代码已经开源,用户也可以自行转换。我们拥有充足的计算资源,可以支持预训练级别的实验开发。近期将通过训练恢复主流模型效果,发布MLA加速版本的基座模型,供开源社区使用。以及在TransMLA上进行各种下游任务,提供高效,强大的领域模型。
| Model Family | Model | Original ppl | PoRoPE+FreqFold ppl | BKV-PCA ppl |
|---|---|---|---|---|
| Llama2 | Llama-2-7B | 5.4735 | 8.9903 | 25.7731 |
| Llama3 | Llama-3-8B | 6.1371 | 8.3997 | 18.3500 |
| Qwen2 | Qwen2.5-7B-Instruct | 8.3541 | 8.0734 | 9.1957 |
| Qwen2.5-72B-Instruct | 4.2687 | 4.9650 | 7.3850 | |
| Gemma2 | gemma-2-9b-it | 10.1612 | 11.4207 | 21.6260 |
| Mistral | Mistral-7B-v0.3 | 5.3178 | 5.5915 | 7.0251 |
| Mixtral | Mixtral-8x7B-v0.1 | 3.8422 | 4.1407 | 5.8374 |
TransMLA支持Grouped Latent Attention(GLA)
近期flash attention和Mamba作者发布的GLA充分发挥了tensor parallel的优势,GLA的推理速度能比MLA快2倍。然而他们将这一方法定位为一个从头预训练的架构,从头训练GLA需要巨大的成本。我们指出,MLA模型,包括DeepSeek以及使用TransMLA转化的模型,通通可以转化为GLA模型。
DeepSeek-V2-Lite原始模型在wikitext2上的ppl为6.3102,直接使用原始GLA的实现加载的ppl为21.0546,这可能是其未提供直接加载DeepSeek模型效果的原因。我们通过解决tensor parallel时RMSNorm和Softmax分割的问题,将ppl降低到了7.2416。这一损失已经足够小,可以轻易的恢复。具体细节将在文章中更新。
接下来我们将会在DeepSeek V3/R1上进行实验,尝试尽量维持满血DeepSeek能力,同时加速推理速度。
总结与展望
年初第一版TransMLA,我们证明了MLA的表达能力大于GQA,希望给基座模型转MLA架构提供一个理由。然而一个季度过去了,一些最新发布的模型仍然采用GQA。其中一个原因是这些企业已经在GQA模型上投入了巨量资金,没有动力抛弃现有架构从头训练MLA模型。新版TransMLA的发布,帮助企业将现有的主流模型转换为MLA模型,只需少量训练即可恢复模型效果,而推理速度能够大大提升。希望这次能够为推动MLA结构的广泛应用提供一点点的助力。
另一个原因是,GQA模型在训练时相比MLA模型对硬件优化的要求更低,需要投入的资源更少。基于这一诉求,接下来TransMLA将会探索预训练的范式,对比从头训练一个DeepSeek和先训练一个GQA模型,再使用TransMLA方法转化为DeepSeek,以及在哪个节点转换,能更好的平衡训练效率和效果。此外将会完善GQA/MHA/MLA转GLA的方法,尝试突破DeepSeek的能力边界。
加入我们
我们是北京大学张牧涵团队:

张牧涵,北京大学人工智能研究院助理教授、研究员、博士生导师、院长助理。首届国家级青年人才项目(海外)获得者,北京大学博雅青年学者、未名青年学者。主持多项国自然、科技部、地方政府项目和课题。主要研究方向包括图机器学习、大语言模型推理和高效微调技术、智慧司法等。Google Scholar总引用量超过9000次,其中两篇一作文章引用量分别达到2500+和2000+次,入选Elsevier全球前2%顶尖科学家。

孟繁续,北京大学张牧涵老师博士生(2022年入学-2026年毕业),哈尔滨工业大学(深圳)优秀硕士毕业生,曾任腾讯优图研究员。孟繁续关注模型压缩领域,擅长模型结构转换(Structure Transfer):TransMLA将GQA结构变为MLA结构;CLOVER(ICML2025)将注意力头吸收再分解,参数正交化提升剪枝率;PiSSA(NeurIPS 2024 spotlight)将模型连带参数主成分分割为adapter,训练收敛快,效果好,量化误差小;Pruning Filter in Filter(NeurIPS 2020)改变卷积计算顺序从而支持结构化裁剪卷积核形状;Filter Grafting(CVPR2020)通过多模型互相嫁接激活无效滤波器,提升训练效果。

汤平之,北京大学元培学院通班二年级本科生,张牧涵组实习生。TransMLA共同一作,参与CLOVER,MuteLoRA,HD-PiSSA等研究工作。曾获得北京大学二等奖学金,优秀学生称号,宋庆龄未来奖学金。
如果您对TransMLA、模型压缩感兴趣,想要设计或训练自己的基座模型。无论您是高年级本科生/研究生想要申请博士学位,还是应届硕士生、博士生想要找实习或工作,都欢迎联系我们。这里有负责任的导师,经验丰富的学长,优秀的合作者,丰富的计算资源。感兴趣的同学请将简历发送至 fxmeng@stu.pku.edu.cn,主题为读博/工作(二选一)+姓名+学校+学历+研究方向。

















 1414
1414

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









