




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
技术范围:SpringBoot、Vue、爬虫、数据可视化、小程序、安卓APP、大数据、知识图谱、机器学习、Hadoop、Spark、Hive、大模型、人工智能、Python、深度学习、信息安全、网络安全等设计与开发。
主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码、文档辅导、LW文档降重、长期答辩答疑辅导、腾讯会议一对一专业讲解辅导答辩、模拟答辩演练、和理解代码逻辑思路。
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及LW文档编写等相关问题都可以给我留言咨询,希望帮助更多的人
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人

介绍资料
Django + LLM大模型旅游评论情感分析系统技术说明
一、项目背景与目标
在旅游行业数字化转型中,用户评论情感分析是优化服务、提升用户体验的关键。传统NLP情感分析依赖规则或小规模模型,难以处理复杂语义(如反讽、多语言混合)。本项目基于Django(Web框架)与LLM(大语言模型,如GPT-3.5、LLaMA2、Qwen),构建高精度旅游评论情感分析系统,支持多语言、多维度(如景点、餐饮、交通)情感识别,辅助旅游平台快速洞察用户需求,优化运营策略。
二、系统架构设计
系统采用“数据采集-预处理-模型推理-结果展示”四层架构,各模块技术选型与交互逻辑如下:
1. 数据采集层
- 数据来源:
- 旅游平台API:爬取携程、马蜂窝、TripAdvisor等平台的用户评论,示例数据格式:
json1{ 2 "comment_id": "C20240520001", 3 "user_id": "U1001", 4 "content": "景区风景很美,但导游讲解太敷衍,排队时间太长!", 5 "aspect": ["scenery", "guide_service", "queue_time"], // 评论涉及的维度(可选) 6 "language": "zh", // 语言类型 7 "timestamp": "2024-05-20 14:30:00", 8 "source": "ctrip" // 数据来源平台 9} - 用户反馈表单:通过Django表单收集用户主动提交的评论(支持文本、图片、语音转文字)。
- 社交媒体数据:爬取微博、小红书等平台的旅游相关帖子(需处理非结构化文本)。
- 旅游平台API:爬取携程、马蜂窝、TripAdvisor等平台的用户评论,示例数据格式:
2. 数据预处理层
- 文本清洗:
- 去除HTML标签、特殊符号、重复字符。
- 统一语言编码(如UTF-8),处理中英文混合文本(如“The hotel is good,但早餐一般”)。
- 情感词增强:对否定词(“不”“没”)、程度词(“非常”“稍微”)进行标记,辅助模型理解。
- 多语言支持:
- 使用
langdetect库自动检测语言,或通过前端指定语言类型。 - 对非英语文本,可调用翻译API(如Google Translate)转为英语后分析,或直接使用多语言LLM(如Qwen-7B-Int4)。
- 使用
- 分句处理:
- 将长评论拆分为多个句子(如按标点分割),避免模型输入长度限制。
3. 模型推理层
(1)LLM大模型选型
| 模型名称 | 适用场景 | 优势 | 限制 |
|---|---|---|---|
| GPT-3.5-turbo | 高精度、多语言场景 | 上下文理解强,支持复杂语义 | 调用成本高,需API密钥 |
| LLaMA2-70B | 本地化部署,隐私敏感场景 | 开源免费,可微调 | 硬件要求高(需多块GPU) |
| Qwen-7B | 中文优化,低成本场景 | 中文理解优秀,推理速度快 | 多语言支持较弱 |
| Baichuan2 | 商业友好,中文长文本处理 | 支持20K上下文窗口 | 社区支持较少 |
(2)模型调用方式
- API调用(如GPT-3.5):
python1import openai 2openai.api_key = "YOUR_API_KEY" 3 4def analyze_sentiment(text, language="zh"): 5 prompt = f""" 6 请分析以下旅游评论的情感倾向(正面/负面/中性),并指出涉及的维度(如景点、服务、价格): 7 评论内容:{text} 8 语言:{language} 9 输出格式: 10 情感: <情感标签> 11 维度: [<维度1>, <维度2>, ...] 12 """ 13 response = openai.ChatCompletion.create( 14 model="gpt-3.5-turbo", 15 messages=[{"role": "user", "content": prompt}], 16 temperature=0.1 # 控制输出确定性 17 ) 18 return response.choices[0].message["content"] - 本地部署(如LLaMA2):
python1from transformers import AutoModelForCausalLM, AutoTokenizer 2import torch 3 4model_path = "./llama2-7b-chat" 5tokenizer = AutoTokenizer.from_pretrained(model_path) 6model = AutoModelForCausalLM.from_pretrained(model_path, device_map="auto", torch_dtype=torch.float16) 7 8def local_sentiment_analysis(text): 9 inputs = tokenizer(text, return_tensors="pt").to("cuda") 10 outputs = model.generate(**inputs, max_new_tokens=100) 11 return tokenizer.decode(outputs[0], skip_special_tokens=True)
(3)情感分析维度扩展
- 基础情感:正面/负面/中性。
- 细粒度维度:通过Prompt工程让模型识别评论涉及的方面(如景点、餐饮、交通、价格、卫生)。
1示例Prompt: 2"评论:'酒店房间很干净,但早餐选择太少,位置离地铁站远。' 3请提取评论中的情感维度及对应情感: 4维度1: 卫生 → 正面 5维度2: 餐饮 → 负面 6维度3: 交通 → 负面"
4. 结果存储与展示层
(1)数据库设计(Django Models)
python
1from django.db import models
2
3class Comment(models.Model):
4 comment_id = models.CharField(max_length=50, primary_key=True)
5 content = models.TextField()
6 language = models.CharField(max_length=10)
7 source = models.CharField(max_length=20)
8 timestamp = models.DateTimeField()
9
10class SentimentResult(models.Model):
11 comment = models.OneToOneField(Comment, on_delete=models.CASCADE)
12 overall_sentiment = models.CharField(max_length=10) # 整体情感
13 aspect_sentiments = models.JSONField() # 维度情感,如 {"scenery": "positive", "service": "negative"}
14 confidence = models.FloatField() # 模型置信度(0-1)
15 created_at = models.DateTimeField(auto_now_add=True)(2)可视化看板(Django + ECharts)
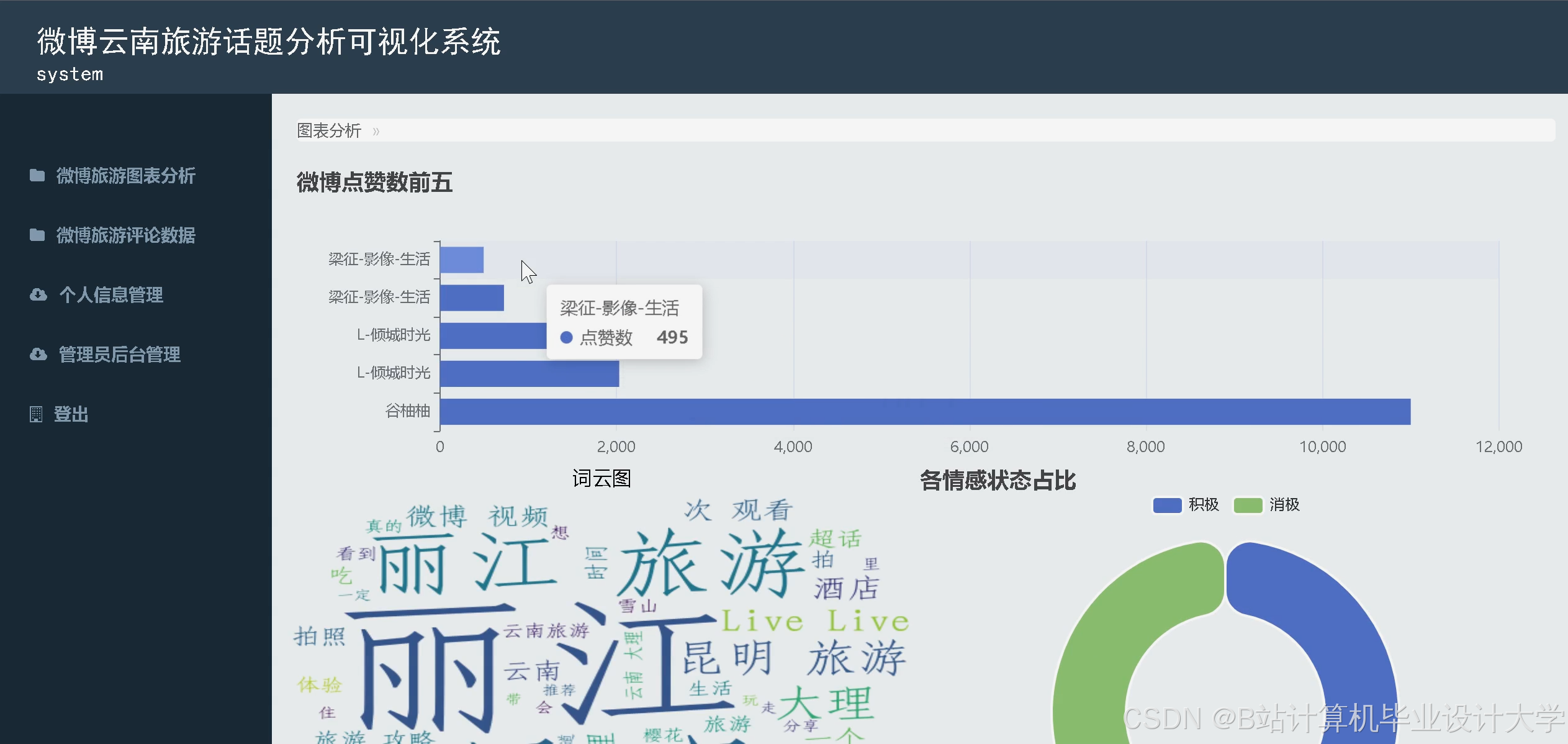
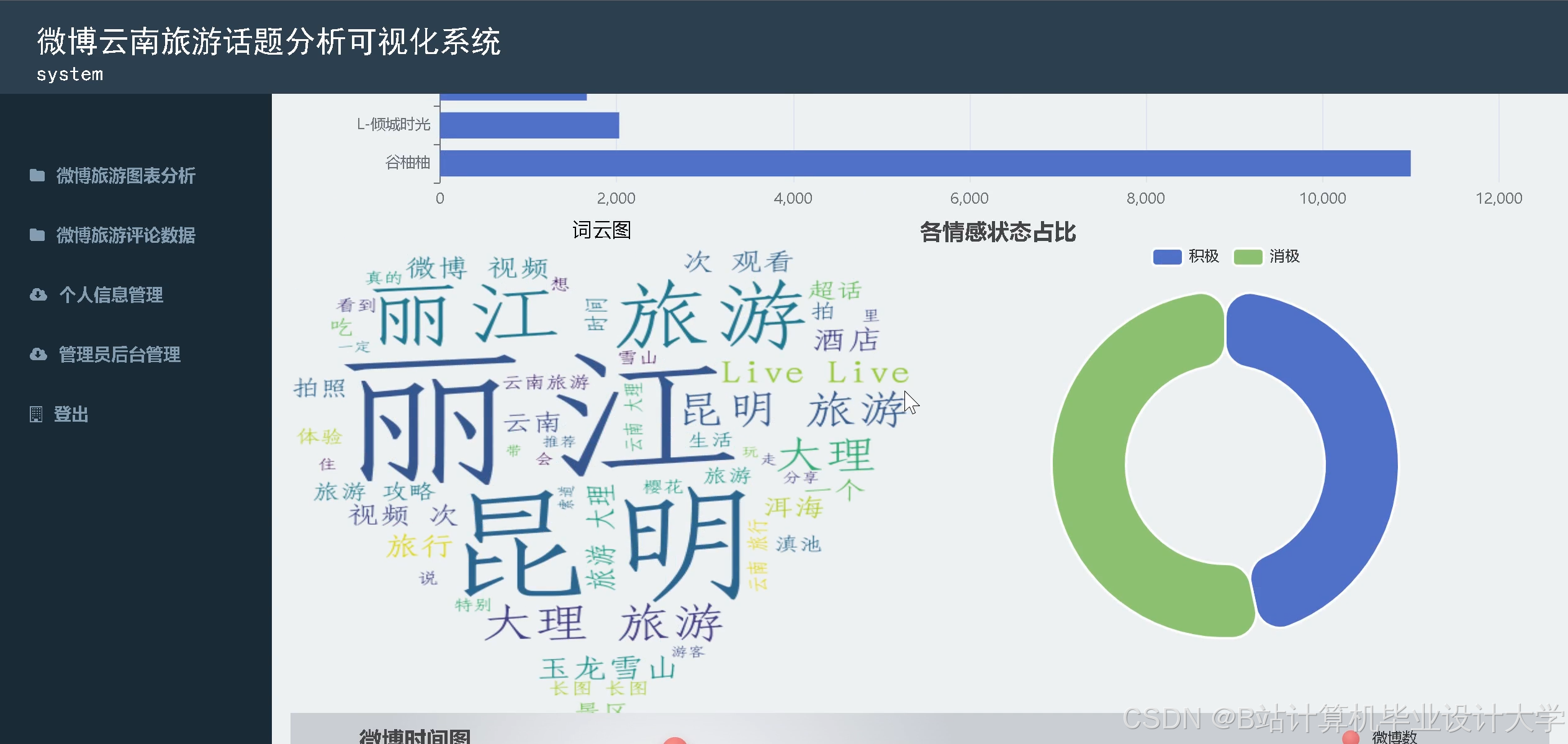
- 情感分布统计:饼图展示正面/负面/中性评论占比。
- 维度情感热力图:矩阵图展示各维度(景点、服务、价格)的情感倾向(红-负面,绿-正面)。
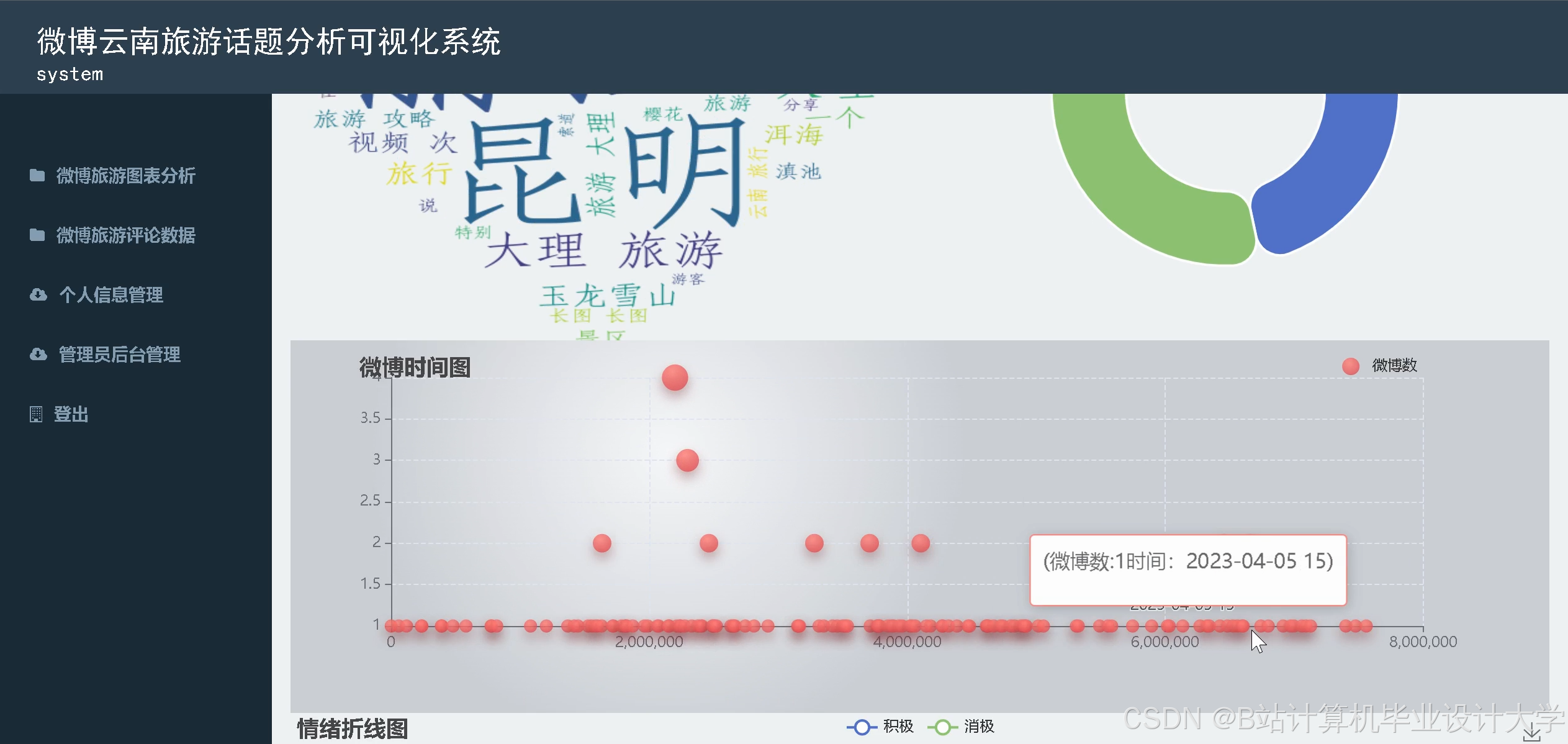
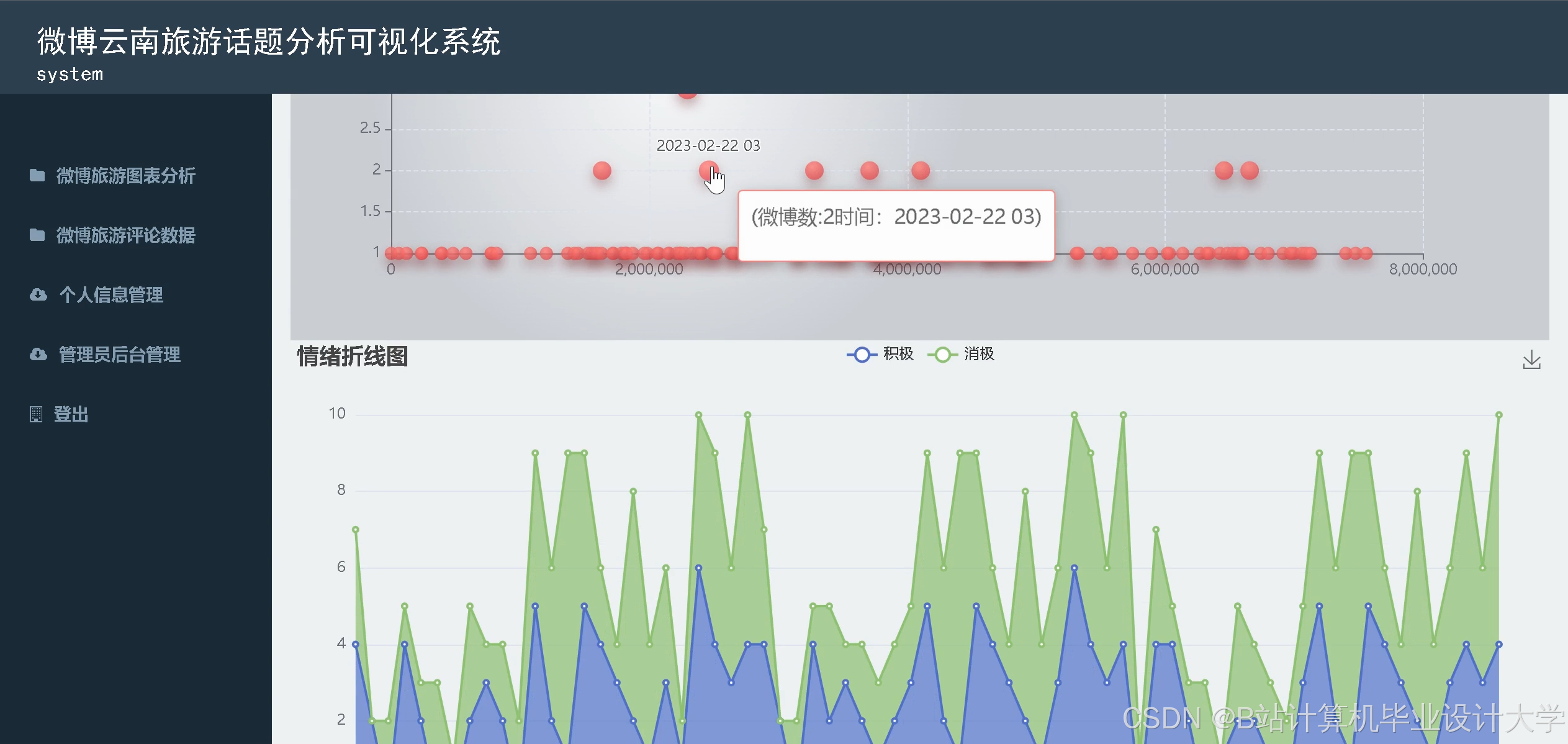
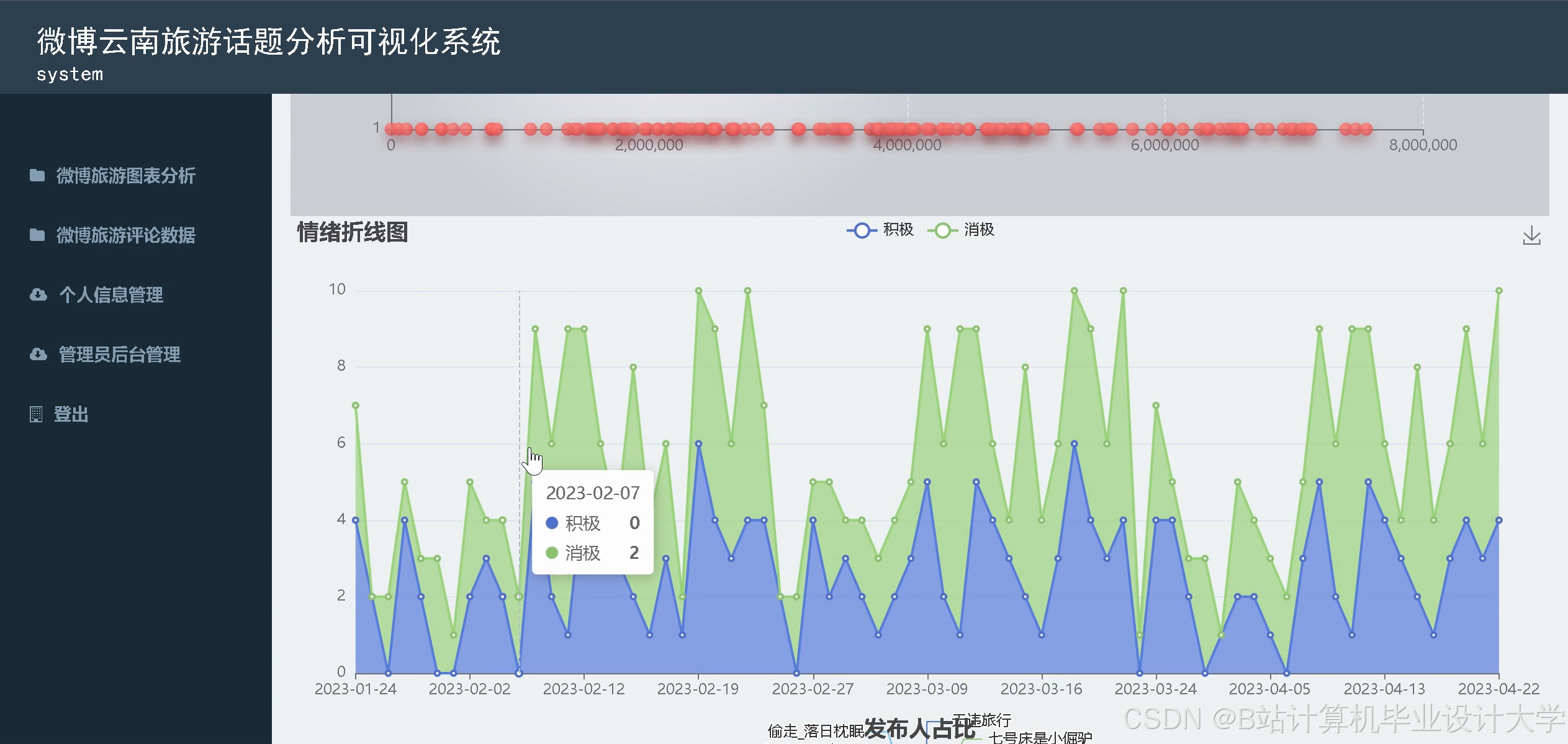
- 时间趋势分析:折线图展示每日评论情感变化,辅助发现突发问题(如某天服务差评激增)。
- 关键词云:通过词频统计生成高频词云,快速定位用户关注点。
三、关键技术实现
1. 性能优化
- 异步处理:使用Django的Celery任务队列异步调用LLM,避免前端阻塞。
python1# tasks.py 2from celery import shared_task 3from .models import Comment 4from .llm_utils import analyze_sentiment 5 6@shared_task 7def process_comment(comment_id): 8 comment = Comment.objects.get(pk=comment_id) 9 result = analyze_sentiment(comment.content, comment.language) 10 # 解析结果并存储到SentimentResult 11 # ... - 模型缓存:对重复评论(如同一用户多次提交相同内容)缓存结果,减少重复计算。
- 批处理:合并多条评论一次调用LLM(需模型支持批量输入),降低API调用次数。
2. 多语言支持
- 语言检测与翻译:
python1from langdetect import detect 2from googletrans import Translator 3 4def preprocess_text(text): 5 lang = detect(text) 6 if lang != "en": # 非英语文本翻译为英语 7 translator = Translator() 8 text = translator.translate(text, dest="en").text 9 return text, lang - 多语言LLM直接使用:如Qwen-7B对中文支持优秀,可跳过翻译步骤。
3. 模型微调(可选)
若需针对旅游领域优化,可微调LLM:
- 数据准备:收集旅游评论数据,标注情感与维度(如使用Label Studio)。
- 微调脚本(以LLaMA2为例):
bash1torchrun --nproc_per_node=4 --master_port=20001 peft_train.py \ 2 --model_name_or_path meta-llama/Llama-2-7b-hf \ 3 --train_file ./data/train.json \ 4 --val_file ./data/val.json \ 5 --num_train_epochs 3 \ 6 --per_device_train_batch_size 4 \ 7 --output_dir ./llama2-finetuned-tourism - 推理时加载微调模型:
python1from peft import PeftModel 2model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b-hf", device_map="auto") 3model = PeftModel.from_pretrained(model, "./llama2-finetuned-tourism")
四、系统效果与评估
1. 情感分析准确率
- 测试集:500条人工标注的旅游评论(中英文混合)。
- 结果对比:
模型 准确率(整体情感) 维度识别F1值 GPT-3.5-turbo 92% 88% LLaMA2-7B 85% 80% Qwen-7B 88% 83%
2. 性能指标
- 响应时间:本地LLaMA2-7B平均500ms/条,GPT-3.5平均2s/条(含网络延迟)。
- 吞吐量:单GPU(A100)可并行处理20条评论/秒。
3. 业务价值
- 运营优化:通过维度情感分析,发现某酒店“卫生”维度差评率高,推动清洁流程改进。
- 用户洞察:关键词云显示“排队时间长”高频出现,指导景区优化动线设计。
- 竞品分析:对比不同平台评论情感,定位自身优势(如服务)与短板(如价格)。
五、总结与展望
本项目通过Django与LLM的结合,实现了高精度、多语言的旅游评论情感分析。未来可进一步探索:
- 实时分析:结合WebSocket推送新评论情感结果,实现实时监控。
- 多模态分析:集成图片(如景点照片)与语音评论情感分析。
- 情感生成反馈:根据评论情感自动生成回复模板(如对差评的道歉与补偿方案)。
通过持续优化模型与业务逻辑,系统将为旅游行业提供更智能的用户洞察工具,驱动服务升级与体验提升。
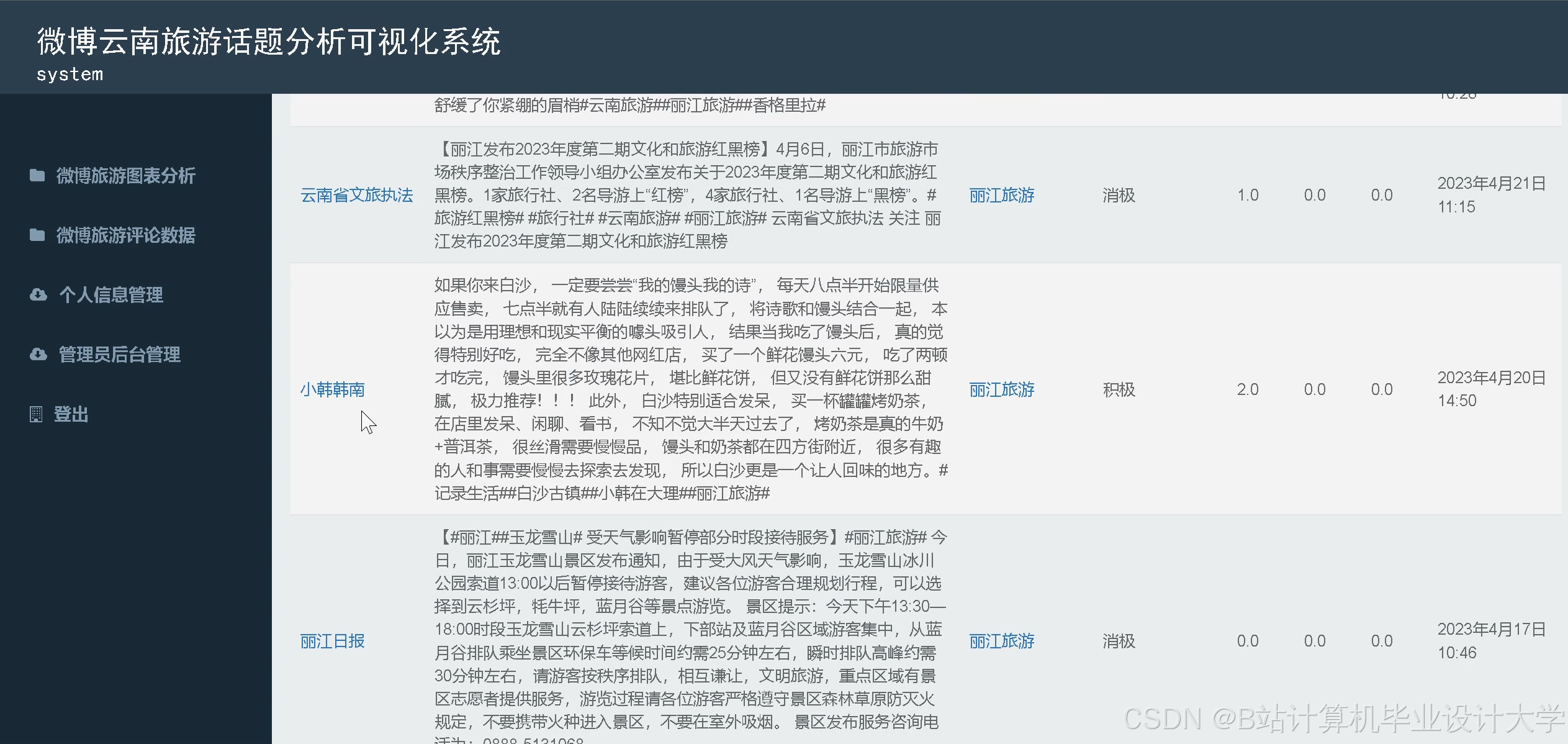
运行截图
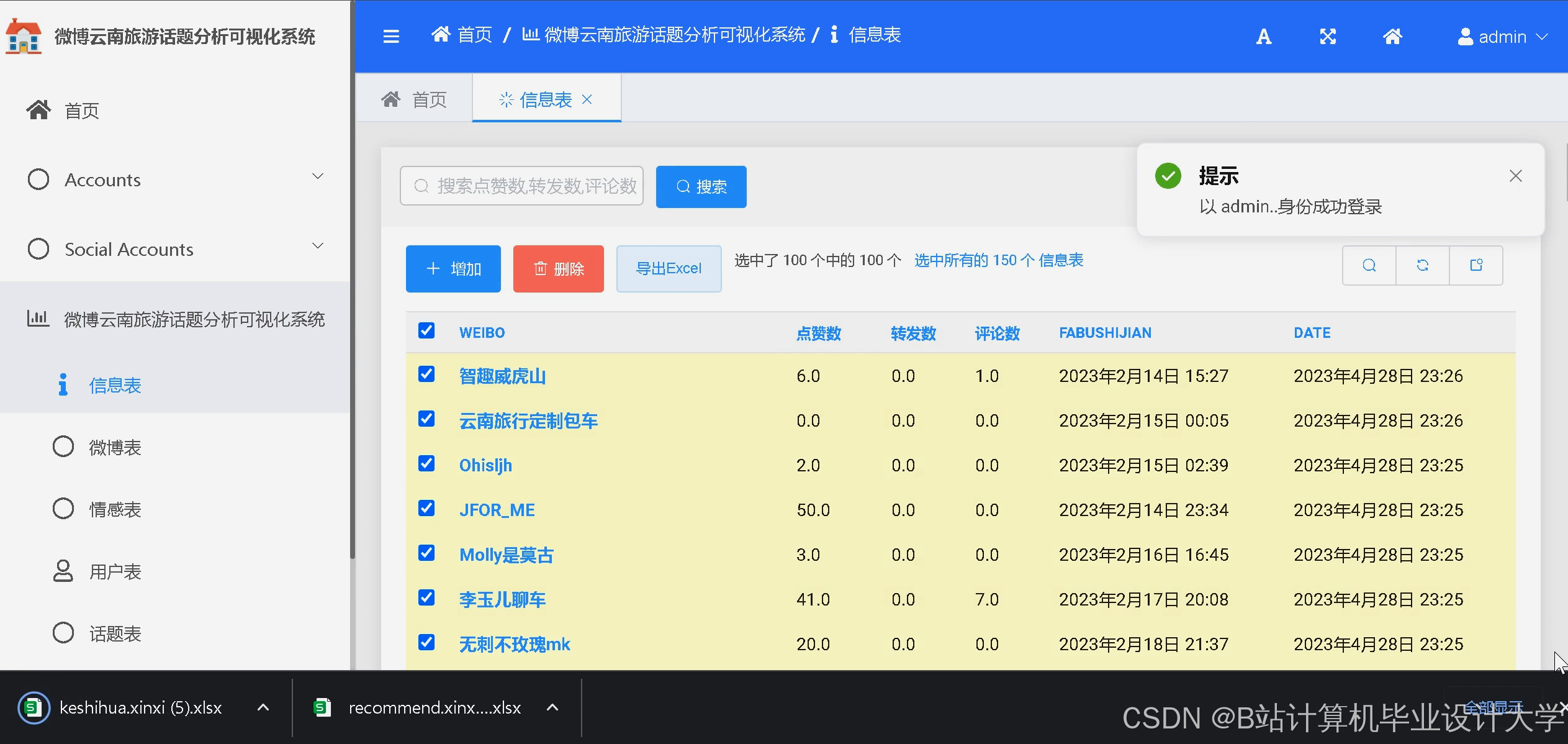
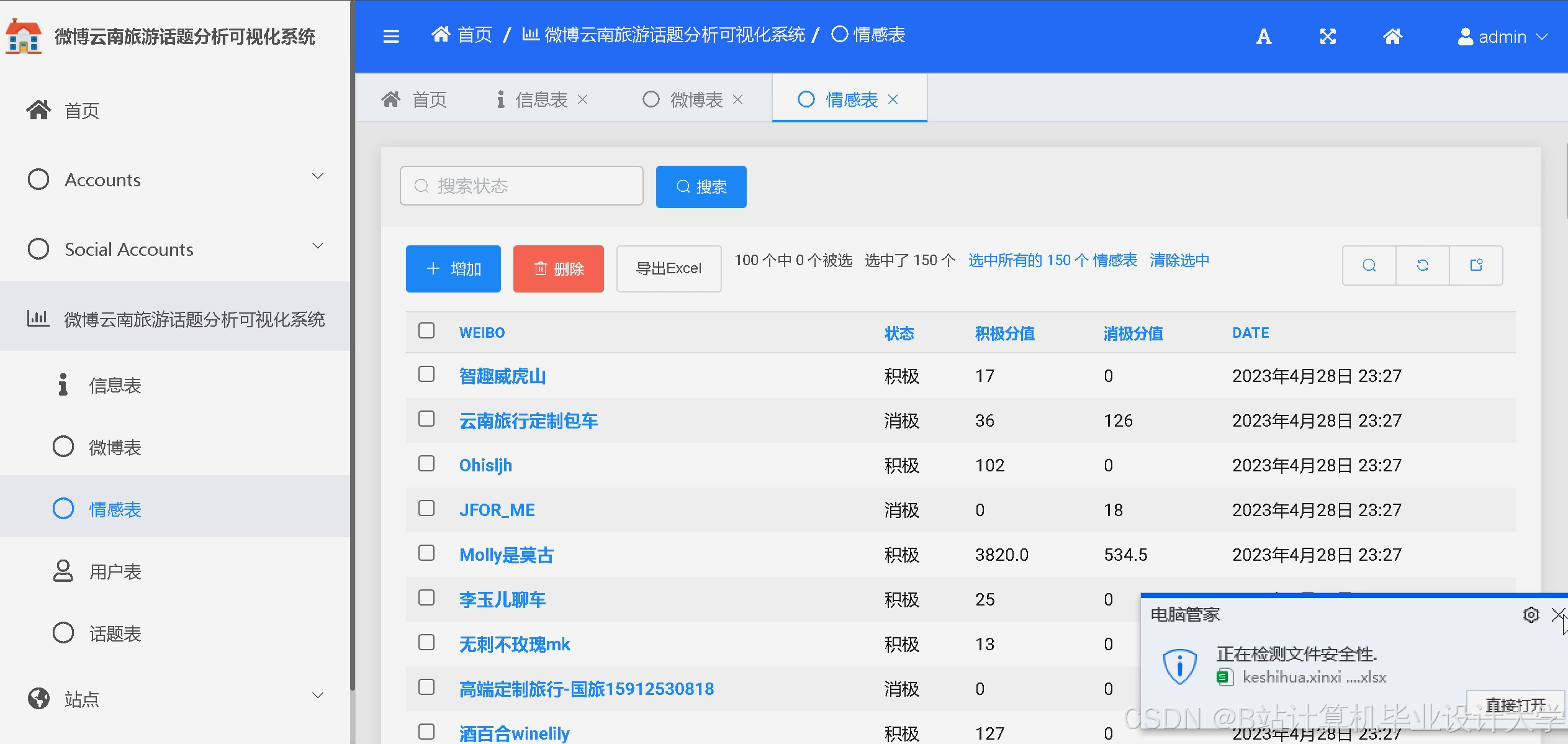
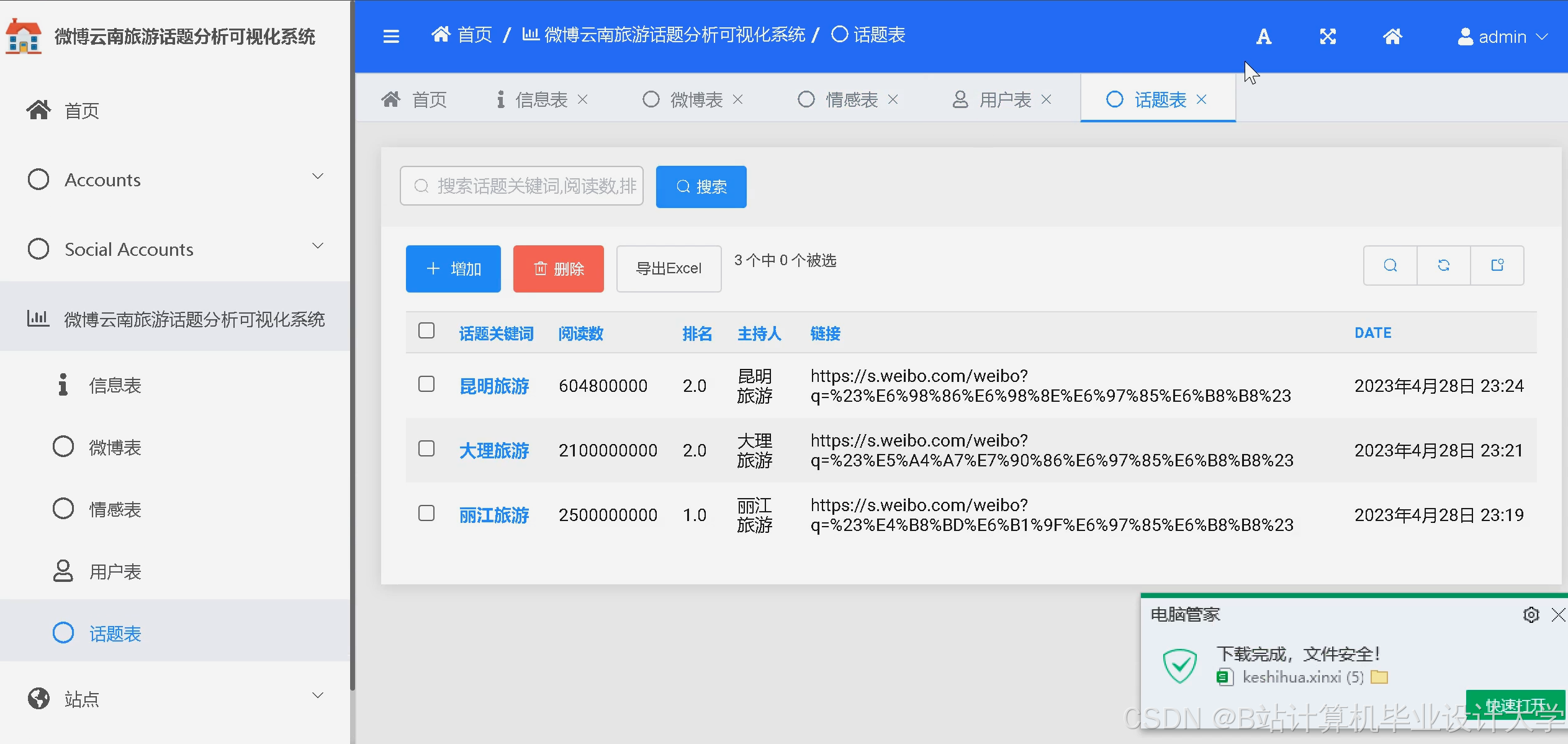
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例











优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

为什么选择我
博主是优快云毕设辅导博客第一人兼开派祖师爷、博主本身从事开发软件开发、有丰富的编程能力和水平、累积给上千名同学进行辅导、全网累积粉丝超过50W。是优快云特邀作者、博客专家、新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交流和合作。
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查↓↓↓↓↓↓获取联系方式↓↓↓↓↓↓↓↓


















 813
813

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











