



DeepWisdom团队 投稿
量子位 | 公众号 QbitAI
视频模型能不能通过生成视频来解决推理问题?——
答案是能。尤其在空间类任务(比如走迷宫)上,比图文模型更擅长,更稳。
DeepWisdom研究团队提出:视频生成模型不仅能画画,更能推理。

它们通过生成连续的视频帧来进行时空规划,这种能力在处理复杂空间任务时,甚至超越了GPT-5和Gemini 2.5 Pro等顶尖的多模态大模型。
为了验证这一观点,团队推出了VR-Bench——这是首个通过迷宫任务评估视频模型空间推理(spatial reasoning)能力的基准测试。
那团队是如何提出这一观点的呢?
视频生成模型真的懂逻辑吗?
试想你在玩一个超复杂的3D迷宫游戏。作为人类,大脑绝不会把这事拆成一串枯燥的文字指令,一边走一边在心里念:“往前走两步”“看到灰墙停下”“再左转九十度”。
这种纯靠文字推理的方式,其实是在对丰富的现实世界进行降维。
三维空间里连续的纵深感、各种物理规律,被硬生生挤压成干瘪的符号,就像你在电话里给朋友指路:你说“在红房子那儿左转”,对方追问“深红还是粉红”;你说“再往前走一点”,对方不知道是五米还是五十米。路线一复杂,信息在语言转译中不断丢失,双方很快会迷路。
而真实情况是,你在脑海中构建的是一个动态的视觉场景。
每一帧画面都承载着大量信息:你不仅看到路怎么走,还能直觉到墙壁的质感、光线明暗,以及前方通道有多深。你会像放电影一样在脑中预演路线,这种连续画面天然地把空间连贯性和因果关系串起来。
于是,你甚至还没迈出第一步,就已经“看见”哪条路是死胡同,凭直觉就能完成复杂的空间规划,而不必费劲把画面翻译成文字。

目前的AI领域正处于一个十字路口:大语言模型(LLM)通过“思维链”(CoT)学会了用文字进行逻辑推理,那么视频生成模型呢?
Sora和Veo3生成的视频虽然逼真,但它们真的理解物理空间和因果逻辑吗?还是仅仅在通过概率“猜”下一帧的像素?
问题到底出在哪?
让我们先看看现有方案的局限性。
长期以来,视频生成模型的评测标准一直停留在“好不好看”上——画质是否清晰、动作是否流畅、是否符合文本描述以及物理规律。
这导致我们忽略了视频模型作为World Simulator的核心潜能:对物理世界动态演变的预测与规划能力。
另一方面,目前主流的视觉推理依赖于“视觉语言模型”(VLM)。
它们的做法是“Reasoning via Text”——将看到的图像转化为文本描述,然后在语言的潜在空间里进行推理。
而本论文指出,这种方式在面对复杂的空间导航时存在天然缺陷:当迷宫变大、维度变高(如3D)时,描述环境所需的文本量呈指数级爆炸,导致模型“上下文饱和”,最终迷失方向。
视频帧就是推理的脚手架
基于这个困境,VR-Bench提出了一个新范式:Reasoning via Video。
在这个范式中,视频模型不是在生成结果,而是在生成过程。
每一帧画面的生成,实际上就是模型在进行一步推理。连续的视频帧构成了“帧链”(Chain-of-Frame),它天然地包含了空间的一致性和时间的因果性。
为了系统性地衡量这种能力,VR-Bench构建了一个包含7920个程序化生成视频的庞大测试场,涵盖五大类高难度空间任务:
常规迷宫 (Regular Maze):基础的空间导航与路径规划。
不规则迷宫 (Irregular Maze):摒弃网格,使用曲线路径,考验纯视觉感知而非坐标记忆。
3D迷宫 (3D Maze):引入高度与遮挡,测试模型在立体空间中的推理能力。
陷阱场 (Trapfield):要求模型不仅要由起点到终点,还必须避开特定的陷阱区域,考验反向约束逻辑。
推箱子 (Sokoban):最高难度的逻辑任务,模型必须理解物体间的相互作用力与推动规则。
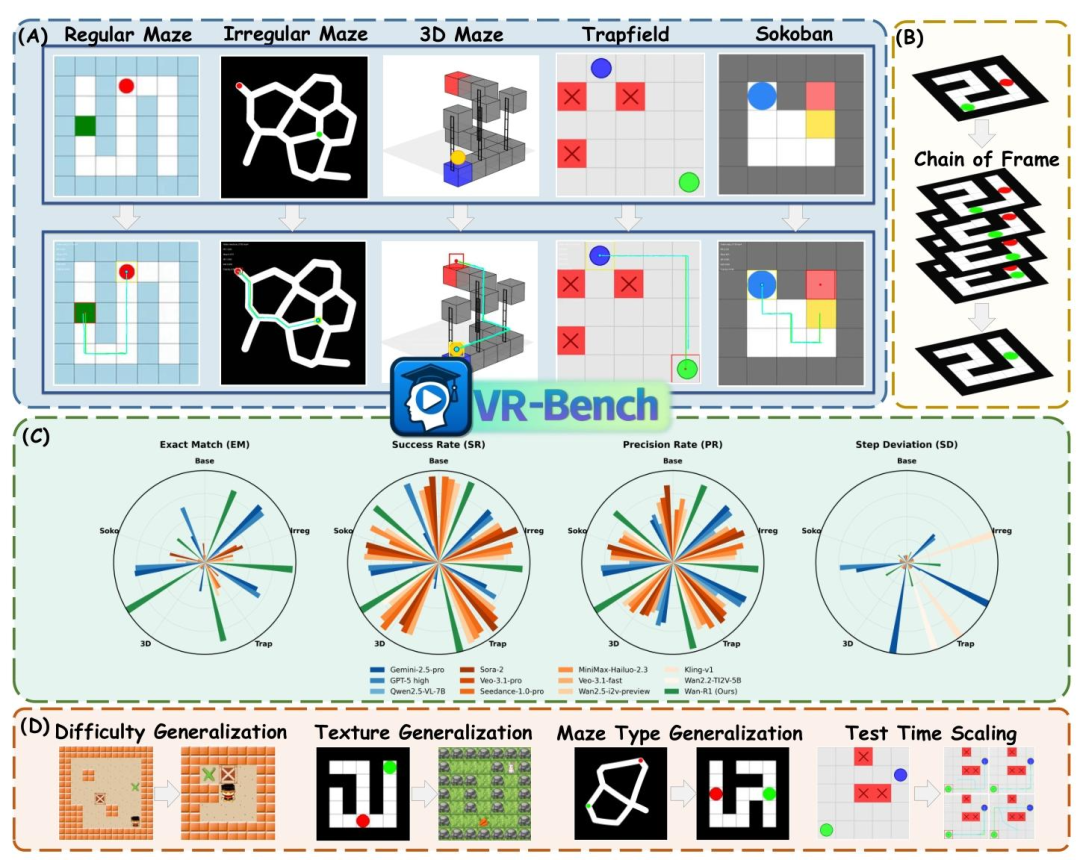
有了“裁判”,才能有“进化”:为视频模型构建客观的奖赏机制
为什么 LLM 能通过强化学习学会复杂的数学推理?
核心在于答案是唯一的,对就是对,错就是错。Jason之前提出了一个Verifier Rule,即训练AI解决某项任务的难易程度与该任务的可验证性成正比。
但在视频生成领域,我们长期缺乏这种硬指标。
模型生成了一段视频,到底逻辑对不对?以往我们只能模糊地说“看着不错”,这导致模型难以获得明确的奖励信号来进行评估。
VR-Bench填补了这块空白。它不看颜值,看轨迹。通过像自动驾驶系统一样追踪视频中物体的运动路径,并将其与最优路径进行比对,我们为视频模型建立了一套像数学题一样客观的评分体系:
成功率 (Success Rate, SR):这是最基础的结果奖励。它只看一点:你有没有到达终点?哪怕你是利用模型 Bug “穿墙”过去的,或者瞬移过去的,只要到了终点就算成功。这保证了模型至少要有完成任务的驱动力。·
精确匹配率 (Exact Match, EM):这是最严苛的稀疏奖励,对应数学推理中的过程结果全对。它要求模型不仅要到终点,还必须严丝合缝地走在最优路径上,一步走错即为零分。
精确率 (Precision Rate, PR):这是过程奖励。它告诉模型“你在第几步开始走歪的”。这种反馈能让模型知道自己错在哪,从而更细致地修正策略。
步骤偏差 (Step Deviation, SD):这是效率奖励。类似于外卖骑手规划路线,不仅要送到,还要不绕路。它量化了路径的冗余程度,要求模型又快又准。
这一设计的深远意义在于:它构建了一个完美的“奖励机制”。
VR-Bench 首次将视频评测从视觉鉴赏转为理性的路径验证。这套清晰的信号系统,为未来引入强化学习、让视频模型探索空间规律铺平了道路。
有了这套机制,视频生成模型也有望迎来属于它们的“R1时刻”。
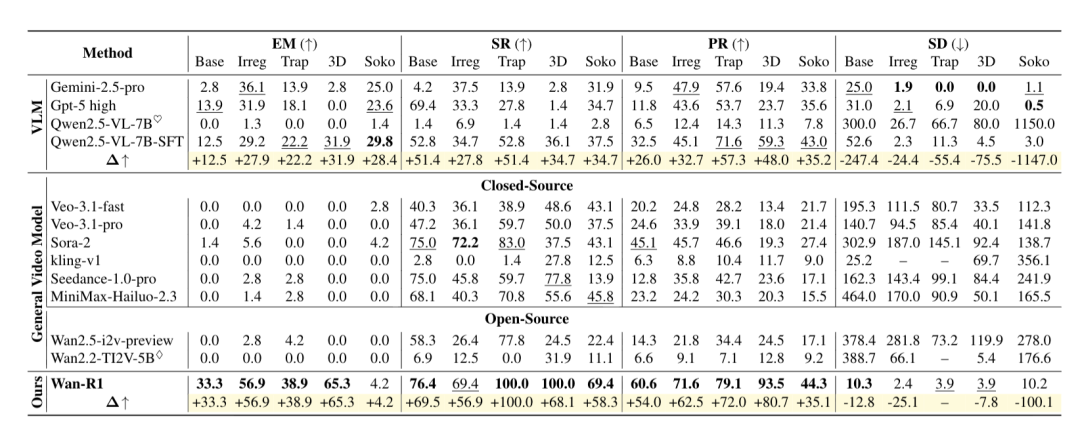
视频模型在空间推理上有巨大优势
VR-Bench的实验结果揭示了视频模型在空间推理上的巨大优势。
推理性能的飞跃
在处理简单的迷宫任务时,像GPT-5 High或Gemini 2.5 Pro这样的VLM确实能与顶尖的视频模型分庭抗礼,甚至在某些指标上略胜一筹 。
但一旦我们将迷宫难度提升到困难模式,VLM的性能就会遭遇断崖式下跌。
相比之下,视频生成模型展现出了令人惊讶的泛化鲁棒性。
在面对大规模、高难度的迷宫挑战时,Sora-2和Seedance-1.0-pro等视频模型全面超越了GPT-5等顶尖VLM。
这种逆袭并非偶然,而是源于底层推理范式的根本差异:VLM试图将静态视觉转化为文本Token,随着迷宫规模扩大,海量的Token迅速导致上下文饱和,从而阻断了长程推理能力。
反观视频模型,它们通过构建时空连贯的Chain-of-Frame进行推理,这种“视觉动力学”机制保证了无论场景多么复杂,每帧的视觉 Token 密度都保持稳定,从而天然地维持了空间连续性。
数据更是揭示了一个反直觉的现象:Sora-2在不规则迷宫的高难度设定下,其成功率(SR)甚至出现了不降反升的趋势。
这一发现强有力地证明,视频生成不仅仅是视觉模拟,更是一种比文本更具可扩展性的、原生的空间推理范式。
更符合物理直觉的路径
实验还发现了一个有趣的现象:即便VLM偶尔能找到终点,它们规划的路径往往也是扭曲且冗余的。
数据显示,VLM 的步骤偏差(Step Deviation)极高,意味着它们在瞎走冤枉路。而视频模型生成的路径则平滑、高效,紧贴最优解。这说明视频模型真正理解了空间结构,而不是在瞎猜。
Wan-R1:不仅仅是微调
为了验证这种推理能力是否可以被高效学习,作者团队基于开源的Wan2.2-TI2V-5B进行了监督微调(SFT),训练出了 Wan-R1。
值得注意的是,团队进行了一项严苛的对比实验:在完全相同的训练数据和接近的训练设置下,同时微调了Wan2.2-TI2V-5B 和 Qwen2.5-VL-7B。
结果显示,Wan-R1展现出了远超VLM的卓越潜力,证明了“Reasoning via Video”在学习时空逻辑上的天然优势。
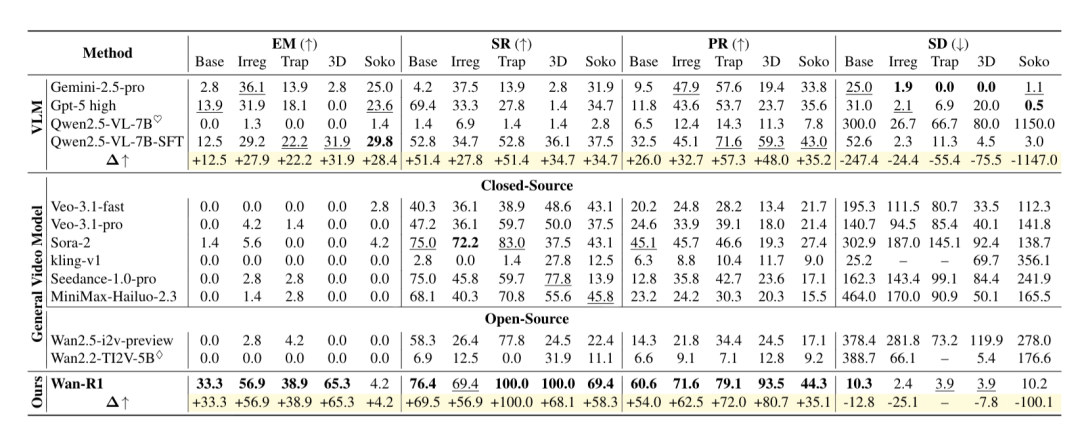
压倒性的成功率:在陷阱场(Trapfield)任务中,Wan-R1 实现了100.0% 的完美成功率,而同样经过微调的 Qwen2.5-VL-7B-SFT 仅为52.8%,差距接近一倍。
更精准的路径匹配:在复杂的3D迷宫中,Wan-R1的精确匹配率(Exact Match)达到了65.3%,而Qwen2.5-VL-7B-SFT仅为31.9%。这也印证了视频模型能更好地学习时间推理和高效路径规划,而VLM即使经过微调,改进也相对有限。
此外,Wan-R1 的表现还证明了泛化能力的真实存在:
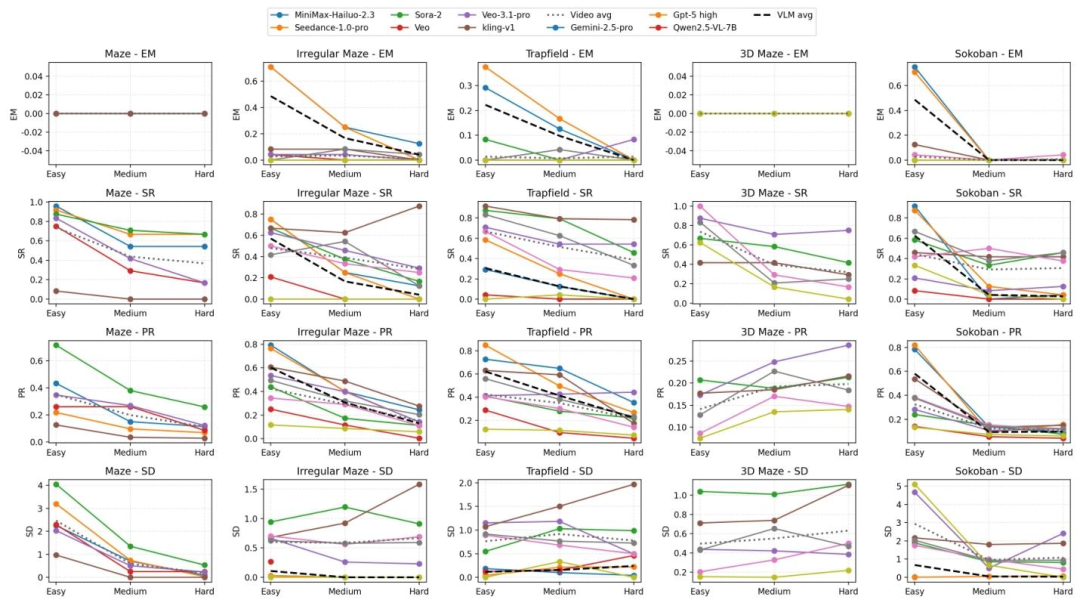
难度泛化:仅用简单难度的迷宫训练,模型竟然学会了解决困难迷宫,并没有止步于记忆简单模式。
材质泛化:训练时只见过一种皮肤,测试时面对从未见过的全新纹理背景(如草地、金属地板),依然能稳定推理。
任务泛化:在某一类迷宫上训练后,模型在未见过的其他类型迷宫上也表现出了性能提升,表明其学到可迁移的空间推理能力。
这有力地反驳了“模型只是记住了地图”的质疑,证明了模型确实内化了通用的空间规划与物理模拟逻辑。
这篇论文引人深思的发现在于视频模型也存在类似于大语言模型的Test-Time Scaling效应。
在大语言模型中,我们知道通过增加推理时的计算量(如Self-Consistency)可以提升准确率。VR-Bench发现,视频模型同理。
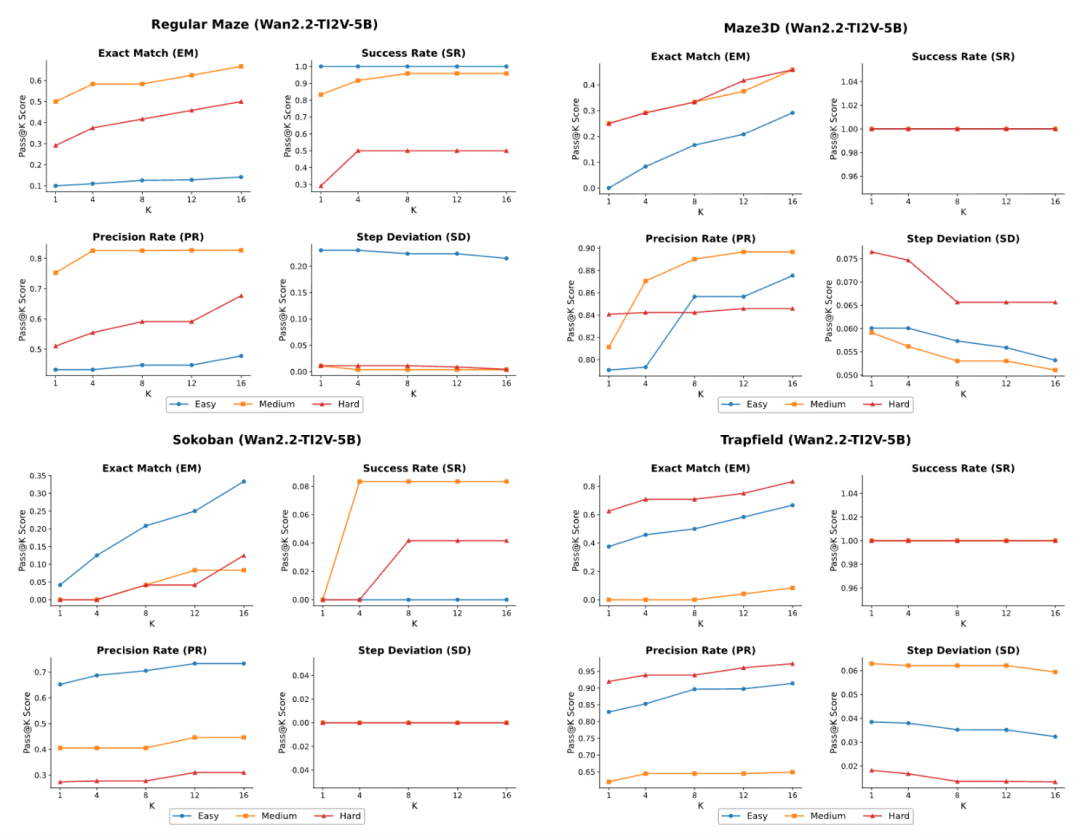
当研究人员让视频模型对同一个任务进行多次生成(增加采样数K),并从中通过算法筛选最优解时,模型的推理性能呈现出明显的上升趋势。
实验数据表明,当采样数K从1增加到16时,模型在各类迷宫上的平均性能提升了10-20%。
展望
VR-Bench的发布,标志着视频生成模型正在从“艺术创作”走向“通用智能”。
如果说Sora让大家看到了视频生成的惊艳效果,那Wan-R1更像是我们在“让视频学会思考”这条路上做的一次初步探索。
这项研究真正的价值,在于它为我们打开了一扇通往未来的窗户。
试想一下,未来的具身智能机器人或许不再需要在现实世界中撞得头破血流去试错。
在真正动手之前,它们可以先在脑子里生成一段视频,预演一下机械臂的运动轨迹,或者模拟一下复杂的交通路况下变道会有什么后果。这种通过视频来“预知未来”的能力,让模型不仅能理解当下的物理规则,更能推演未来的连锁反应,这或许才是通往World Simulator那把关键的钥匙。
Reasoning via Video,这场视觉智能的革命才刚刚开始。
目前,作者已在Github开源了代码和数据集。感兴趣的朋友可以自己创造不同的迷宫种类,并用自己的视频模型进行评测。

论文地址:https://arxiv.org/abs/2511.15065
代码地址:https://github.com/FoundationAgents/VR-Bench
数据集:https://huggingface.co/datasets/amagipeng/VR-Bench
网页地址: https://imyangc7.github.io/VRBench_Web/


















 17
17

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









