



鱼羊 发自 凹非寺
量子位 | 公众号 QbitAI
国产大模型,最近有点卷。
这不,刚在写代码这事儿上刷新SOTA,Qwen2.5系列又双叒突然更新了——
一口气读三本《三体》不费事,并且45秒左右就能完整总结出这69万token的主要内容,be like:
还真不是糊弄事儿,“大海捞针”实验显示,这个全新的Qwen2.5-Turbo在100万token上下文中有全绿的表现。
也就是说,这100万上下文里,有细节Qwen2.5-Turbo是真能100%捕捉到。
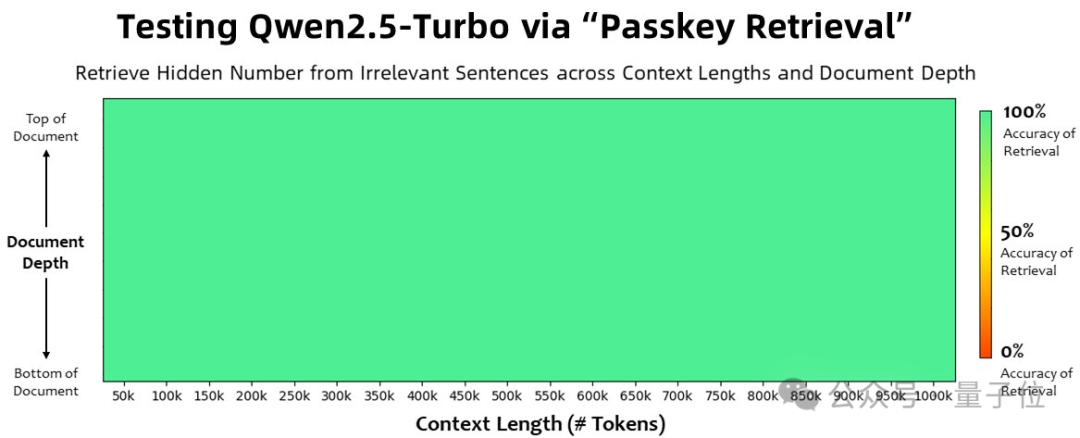
没错,Qwen2.5系列新成员Qwen2.5-Turbo,这回主打的就是支持超长上下文,并且把性价比卷出了花儿:
上下文长度从128k扩展到1M,相当于100万个英文单词或150万个汉字,也就是10部长篇小说、150小时语音记录、30000行代码的量。

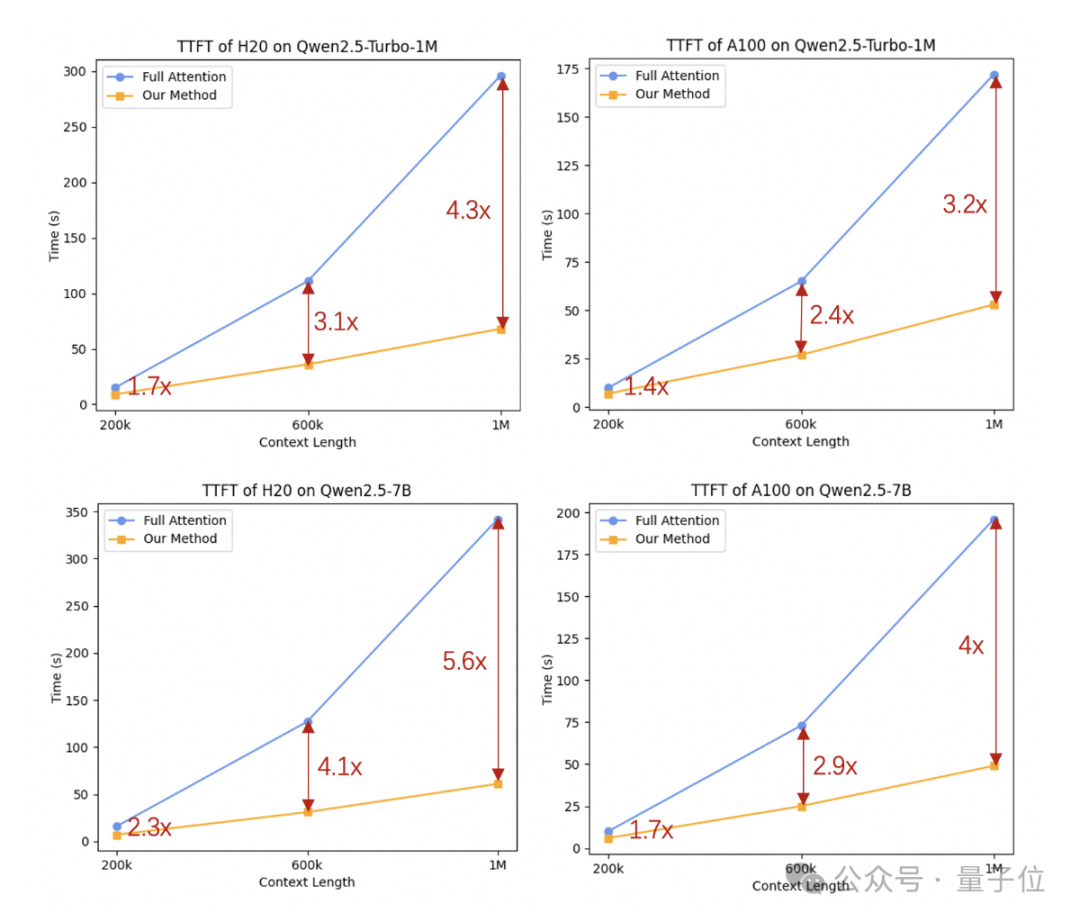
更快的推理速度:基于稀疏注意力机制,处理百万上下文时,首字返回时间从4.9分钟降低到了68秒,实现了4.3倍加速。

关键是还便宜:0.3元/1M tokens。这意味着,在相同成本下,Qwen2.5-Turbo可以处理的token数量是GPT-4o-mini的3.6倍。

看到这波更新,不少网友直接爆出了***:
有人直言:这么长的上下文这么快的速度下,RAG已经过时了。
还有人开启大赞特赞模式:现在在开源领域,Qwen比Llama还值得期待了。

上下文能力扩展不影响性能
除了一口气啃下3本长篇小说,Qwen官方还展示了Qwen2.5-Turbo超长上下文的更多实用功能。
比如快速掌握一整个代码库的信息。
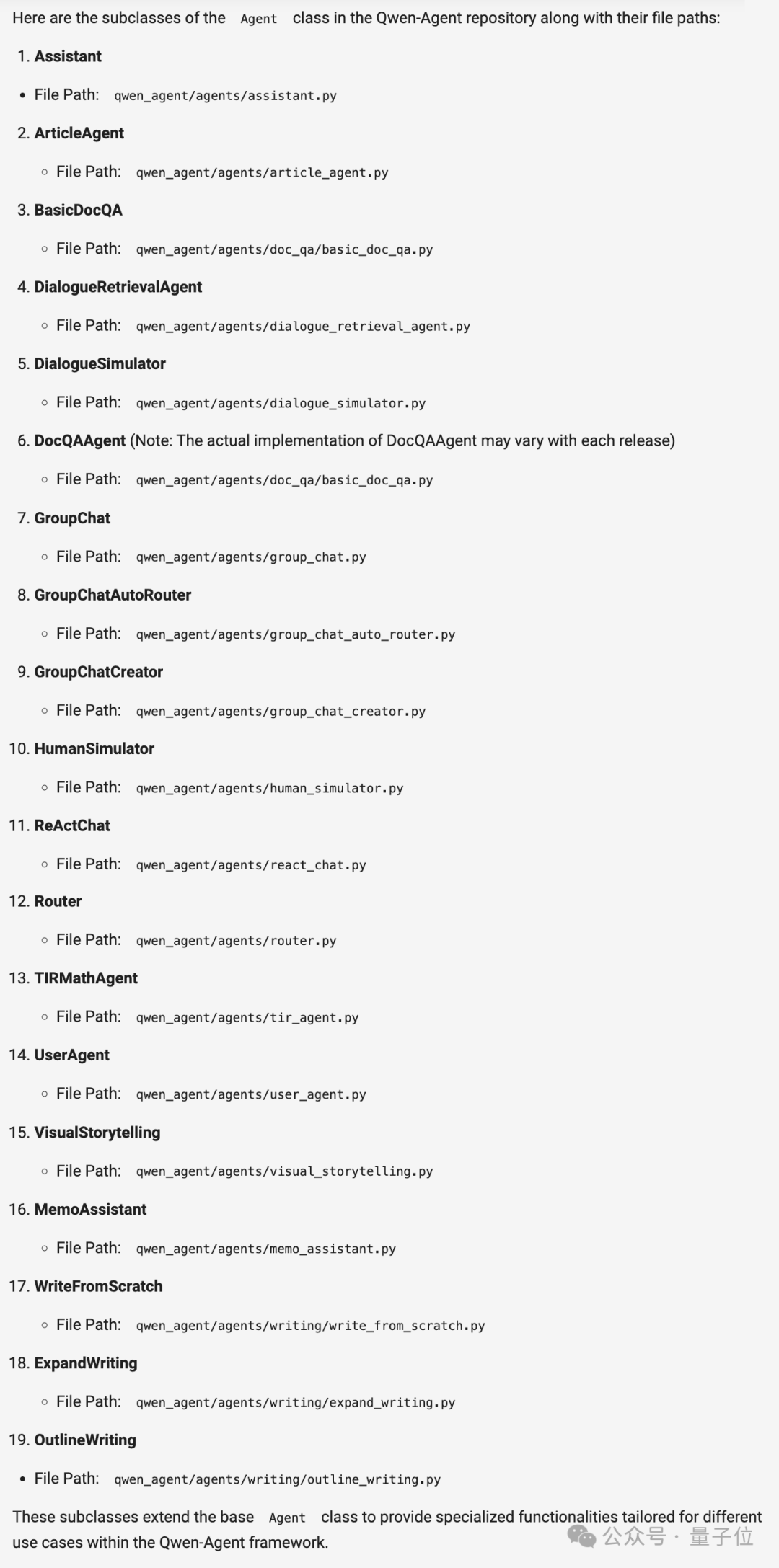
如Demo所演示,上传包含Qwen-Agent仓库中所有代码文件的文本文件(13.3万token),只需几秒钟,大模型就能读完全部代码并准确输出各种细节。
用户:这个存储库中有哪些Agent子类?提供它们的文件路径。
Qwen2.5-Turbo:
一口气读7篇论文,完成论文分类、论文摘要,也不在话下:
我们也实际测试了一下。可以看到,在没有给任何提示的情况下,Qwen2.5-Turbo能准确掌握不同论文的细节信息,并完成对比分析。
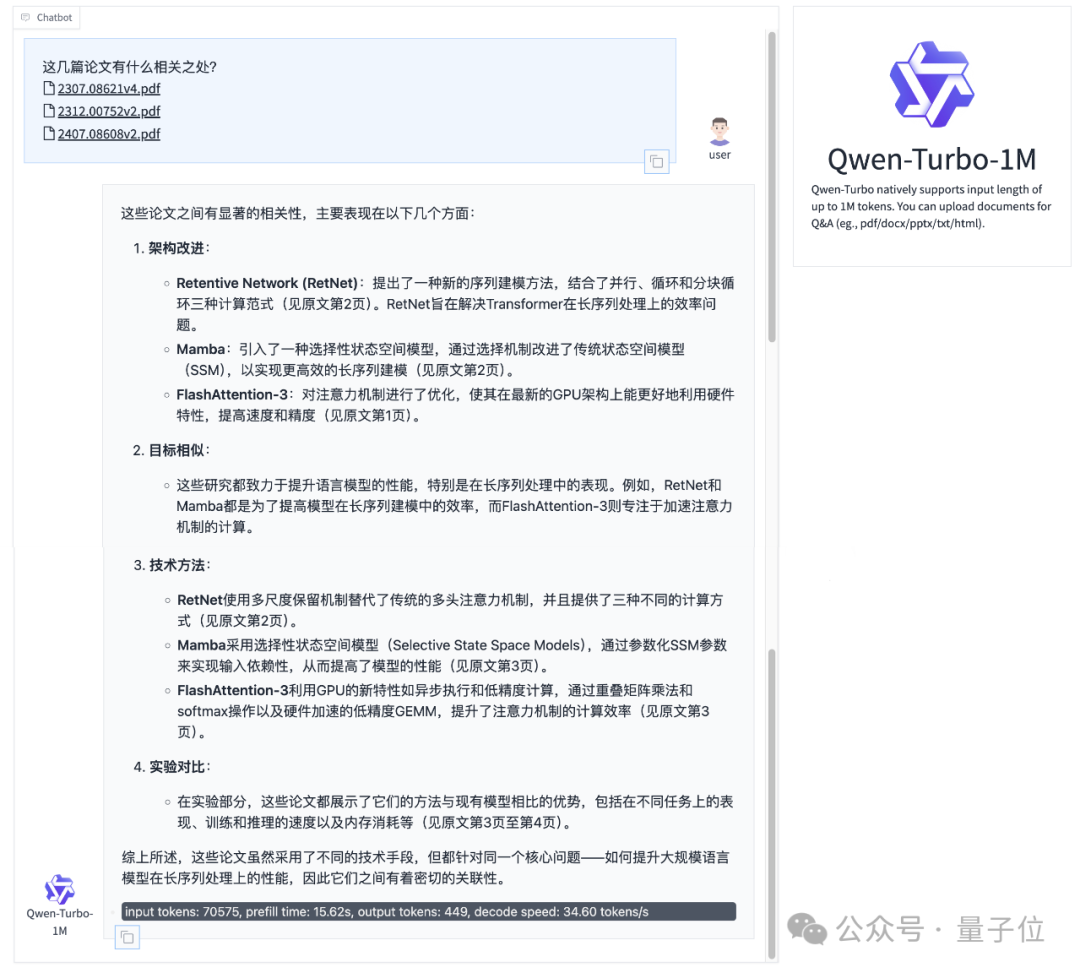
除了大海捞针实验之外,Qwen团队还在更复杂的长文本任务上测试了Qwen2.5-Turbo的能力。
包括:
RULER:基于大海捞针的扩展基准,任务包括在无关上下文中查找多“针”或回答多个问题,或找到上下文中出现最多或最少的词。数据的上下文长度最长为128K。
LV-Eval:要求同时理解众多证据片段的基准测试。Qwen团队对LV-Eval原始版本中的评估指标进行了调整,避免因为过于严苛的匹配规则所导致的假阴性结果。数据的上下文长度最长为128K。
Longbench-Chat:一个评价长文本任务中人类偏好对齐的数据集。数据的上下文长度最长为100K。
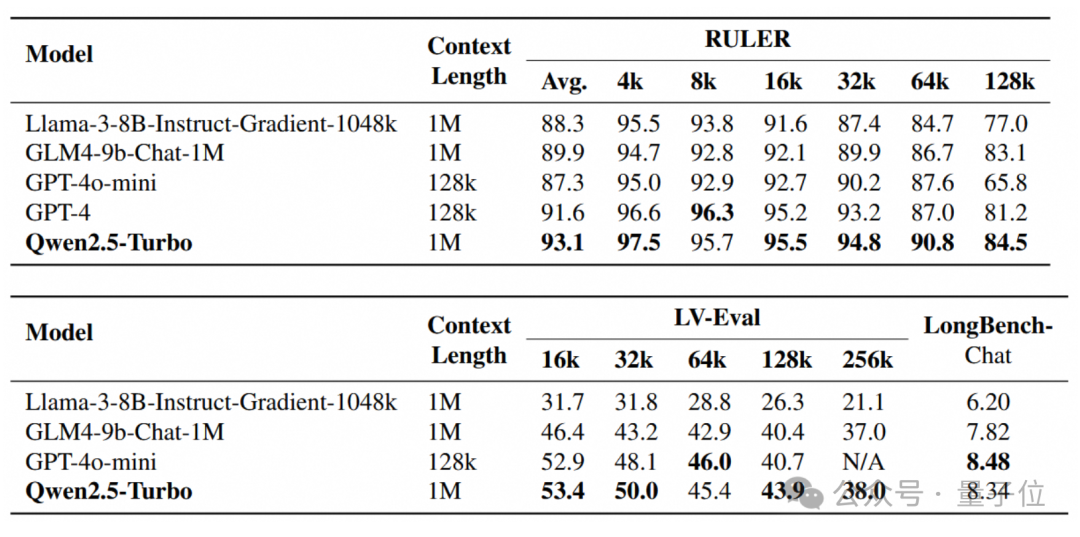
结果显示,在RULER基准测试中,Qwen2.5-Turbo取得了93.1分,超过了GPT-4o-mini和GPT-4。
在LV-Eval、LongBench-Chat等更接近真实情况的长文本任务中,Qwen2.5-Turbo在多数维度上超越了GPT-4o-mini,并且能够进一步扩展到超过128 tokens上下文的问题上。
值得一提的是,现有的上下文长度扩展方案经常会导致模型在处理短文本时出现比较明显的性能下降。
Qwen团队也在短文本任务上对Qwen2.5-Turbo进行了测试。
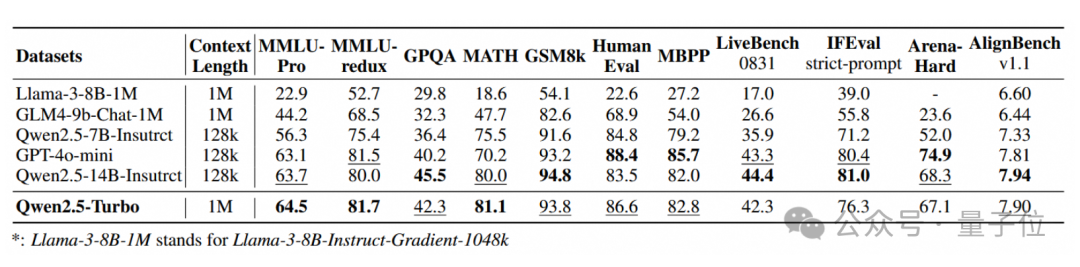
结果显示,Qwen2.5-Turbo在大部分任务上显著超越了其他上下文长度为1M tokens的开源模型。
和GPT-4o-mini以及Qwen2.5-14B-Instruct相比,Qwen2.5-Turbo在短文本任务上的能力并不逊色,但同时能hold住8倍于前两个模型的上下文。
此外,在推理速度方面,利用稀疏注意力机制,Qwen2.5-Turbo将注意力部分的计算量压缩到了原来的2/25,在不同硬件配置下实现了3.2-4.3倍的加速比。
现在,在HuggingFace和魔搭社区,Qwen2.5-Turbo均提供了可以在线体验的Demo。
API服务也已上线阿里云大模型服务平台,跟OpenAI API是兼容的。

至于模型权重什么时候开源?
阿里通义开源负责人林俊旸的说法是:目前还没有开源计划,但正在努力中。
反正HuggingFace联合创始人Thomas Wolf是帮咱催上了(手动狗头)。
Demo传送门:
https://huggingface.co/spaces/Qwen/Qwen2.5-Turbo-1M-Demo
https://www.modelscope.cn/studios/Qwen/Qwen2.5-Turbo-1M-Demo
参考链接:
https://qwenlm.github.io/zh/blog/qwen2.5-turbo/
— 完 —
定档12月11日
「MEET2025智能未来大会」开启报名
李开复博士、周志华教授、智源研究院王仲远院长都来量子位MEET2025智能未来大会探讨行业破局之道了!
首批嘉宾阵容在此,观众报名通道已开启!欢迎来到MEET智能未来大会,期待与您一起预见智能科技新未来!
点这里👇关注我,记得标星哦~


















 6
6

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









