



编辑部 整理自 MEET2026
量子位 | 公众号 QbitAI
对企业来说,如何判断大模型究竟是真的有用,还是只是噱头?
对此,潞晨科技创始人兼董事长,新加坡国立大学校长青年教授尤洋给出了他的判断框架:
有三类企业需要行业模型或者私有模型:传统大型企业、有海量数据的中小型企业,以及颠覆行业的新兴公司。

具体落地方面,尤洋给出的判断标准也很明确。
首先,如果只是业务只涉及日常办公,或主要处理文本数据,没必要上私有模型。
直接调用现成的大模型API,或RAG+API,足以覆盖大多数需求。
但如果企业本身拥有海量多模态数据,或对数据隐私有要求,构建私有模型是比较好的选择。
为了完整呈现尤洋的思考,在不改变原意的基础上,量子位对演讲内容进行了整理编辑,希望能提供新的视角与洞察。
MEET2026智能未来大会是由量子位主办的行业峰会,近30位产业代表与会讨论。线下参会观众近1500人,线上直播观众350万+,获得了主流媒体的广泛关注与报道。
核心观点梳理
大模型的应用肯定不仅限于聊天机器人或者编程助手,未来大模型在千行百业里边落地,才能产生它最大的价值。大模型的价值在很多场景还没有真正发挥出来。
有三类企业需要行业模型或者私有模型,第一类是传统大型企业,第二类是有海量数据的中小型企业,第三类是颠覆行业的新兴公司。
用大模型做To B,最关键的是后训练或Agent化,如果只是调大模型API,大家用的模型都一样,显然没有任何差异性。开源模型只有在被“专业训练”后才能战胜闭源模型。
企业部署大模型成功的关键,一是要最大化算力效率,另外还要有微调SDK和低代码模板。
潞晨云最新上线微调SDK,开发者仅需专注模型与算法创新,训练调度、分布式框架适配、底层云基础设施及运维由平台完成。
以下是尤洋的演讲全文:
四年收获八个世界五百强,十个世界两千强
今天很开心在量子位大会跟大家交流,潞晨坚信未来AI大模型在千行百业里面落地,才能产生它最大的价值,而不仅仅限于聊天机器人或者编程助手。
我是新加坡国立大学的教授,很荣幸在2021年ChatGPT为代表的大模型浪潮前,就创立了潞晨科技这家公司,专注于该领域。
首先介绍一下潞晨在过去几年的一些实践,取得的一些成绩。

技术方面,2018年开始,潞晨开始着手做一些大模型的基础设施相关的软件,最下层的不管从编译器还是CUDA包括优化器,都是训练部署大模型比较需要的。
比如2018年打造的LAMB优化器,在Google的千卡集群TPU Pod上将大模型训练时间从三天缩减到76分钟。
今天,LAMB优化器和方法还在被微软的DeepSpeed、字节的Megascale,以及英伟达的Megatron-LM等万卡集群系统所使用。
基于LAMB,潞晨做了一些后续工作,成功应用在华为的盘古大模型以及字节的推荐模型里,并获得了ACL杰出论文。
世界上最顶尖的专家之一,Benjamin Mann(Anthropic的联合创始人,GPT-3的共同第一作者),他在2019年使用LAMB,首次把Transformer训练扩展到128个GPU。
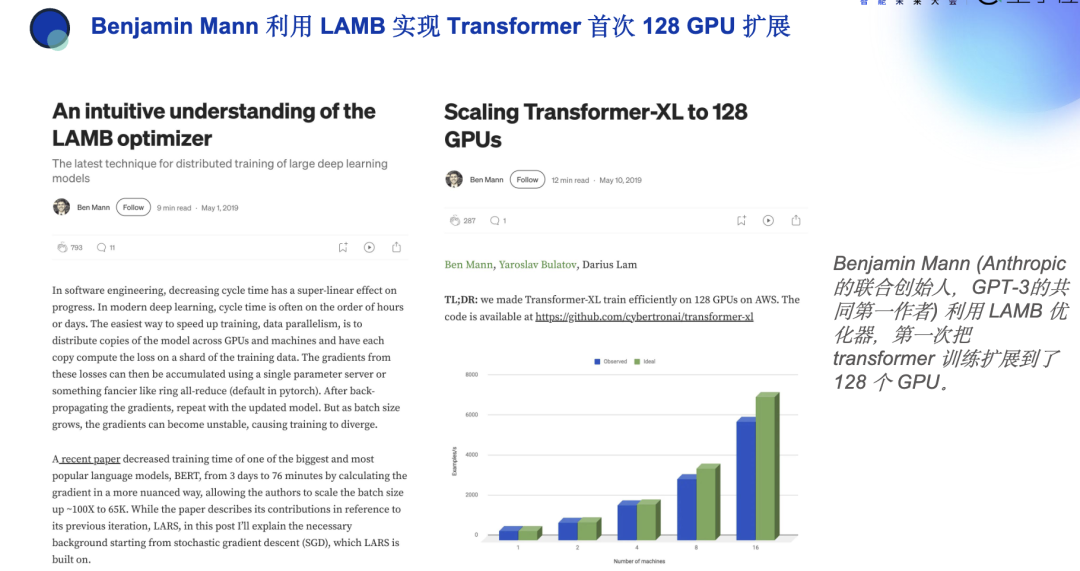
这从英伟达官方GitHub上可以查到,英伟达专家曾经使用过LAMB取得17倍的加速。

之后,潞晨把这些针对大模型训推性能的系统优化技术,打造成了一个软件系统Colossal-AI,并对基础版本进行了开源。
潞晨希望通过更好用、速度更快、性价比更高的系统或者软件,帮助用户降本增效的做出所需要的私有模型。
经过几年发展,Colossal-AI在GitHub上这个细分赛道里面指标是最高的,大家可以尝试一下开源版本,潞晨也提供相应的进阶商业支持。
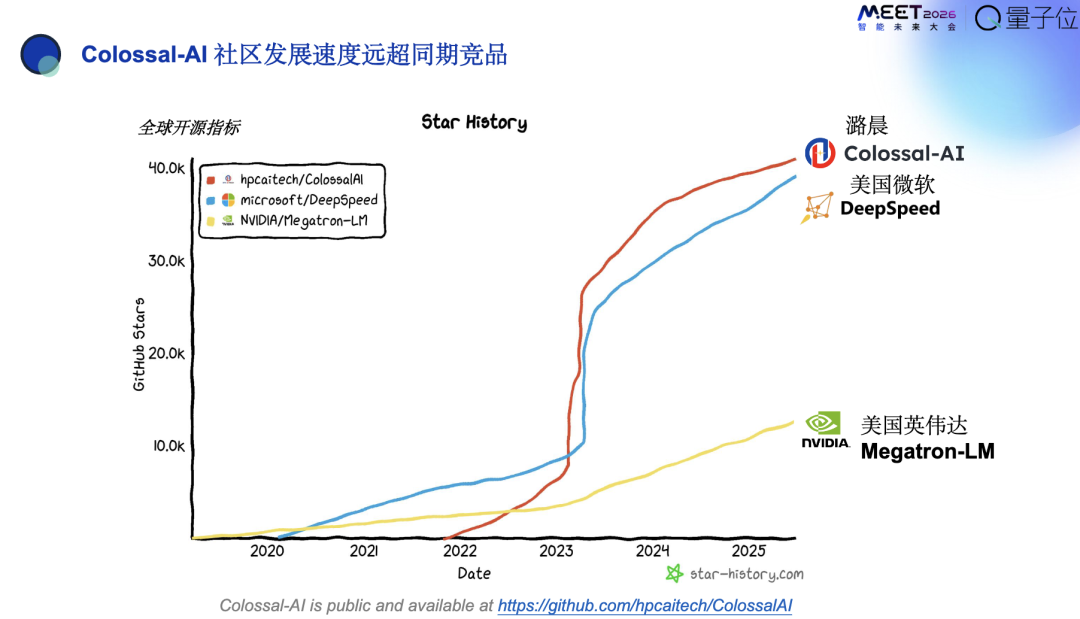
目前,潞晨收获了八个世界五百强,十个世界两千强,六十个一流大学和三千家企业在内来自全球的付费客户,涵盖了汽车、互联网、手机、制药、制造业等等。
这个过程之中,大家对大模型的认可程度是逐渐变高的。
对标Thinking Machines Lab,挖掘AI落地千行百业的价值
OpenAI前CTO也做了一个创业公司叫Thinking Machines Lab,虽然没有任何收入但是估值已经120亿美金了。
它跟潞晨做的事情也比较类似,打造了Tinker模型微调开发平台,帮助企业和研发人员做出自己的私有模型或者AI Agent。
还有Together AI,通过优化技术提升GPU的价值。
任何企业做大模型,大多数决策者首先要问的第一个问题就是:我的企业是否真的需要大模型,大模型是不是真的有效,还是只是一个噱头?
先展示一些互联网上可以查到的案例:中石油的三千亿参数的昆仑大模型,Bloomberg的金融大模型,华为云发布的盘古气象大模型,宝马的优化汽车制造流程的大模型以及李维斯、航空航天、动画、西门子,还有制药行业。

从这大概可以看出这些行业的数据特点,不仅仅是DeepSeek或者ChatGPT这样的通用文本或者编程模型能解决的,更重要的是大模型在千行百业落地价值,很多场景还没有真正发挥出来。
比如说未来的石油勘探,让大模型判断地下的地质结构,研究地球的数据。比如打一口井成本是1000万美金,打十次才有一口比较好的油井,通过大模型优化即使只提升10%,在这个行业的收益前景也非常可观。
之前大家用一些正演反演算法判断地下的断层、地下复杂的结构数据量非常大,PB级别的,传统的算法稳定性不好,速度也比较慢无法扩展。
大模型可以用更好的方式,核心都是在解方程组,可以给出一个很好的近似解。因此,大模型在千行百业的价值还没有完全发挥出来。
下一个问题是:到底什么样的企业或者什么样的业务需要自己做一个私有大模型,不仅仅调用一下标准模型的API就够了?
至少有三类:
第一类,传统的大型企业,包括世界五百强全球两千强,这些企业或多或少都有自己行业比较珍贵的大量信息或者数据。
第二类,有海量数据的中小型企业,可能专精于某个细分领域,数据就是大模型的源泉。
第三类,颠覆行业的新型公司用AI技术找到新的思路,不管金融、制药、社交、游戏、电商等等都可以。这些企业是最需要自己造一个私有大模型或者行业大模型的企业。
具体落地方式有三种。
第一,假如说没有行业数据,只是处理一些日常办公或者处理文本类的东西,企业直接调用ChatGPT或者通义千问API一般就能满足需求。
第二,假如说有足量的文本数据,这个阶段很多时候不用构建自己的大模型,构建RAG/Agent加上大模型API也能满足。
第三,如果一个企业有海量多模态数据或者强隐私要求,不管是石油勘探或者高铁、汽车、制药、金融等,往往有很多多模态数据,这时候构建一个私有模型是比较好的选择来满足需求。
这张图来自于一个Grand View Research,它对大语言模型市场的预测,大概分为三个部分。
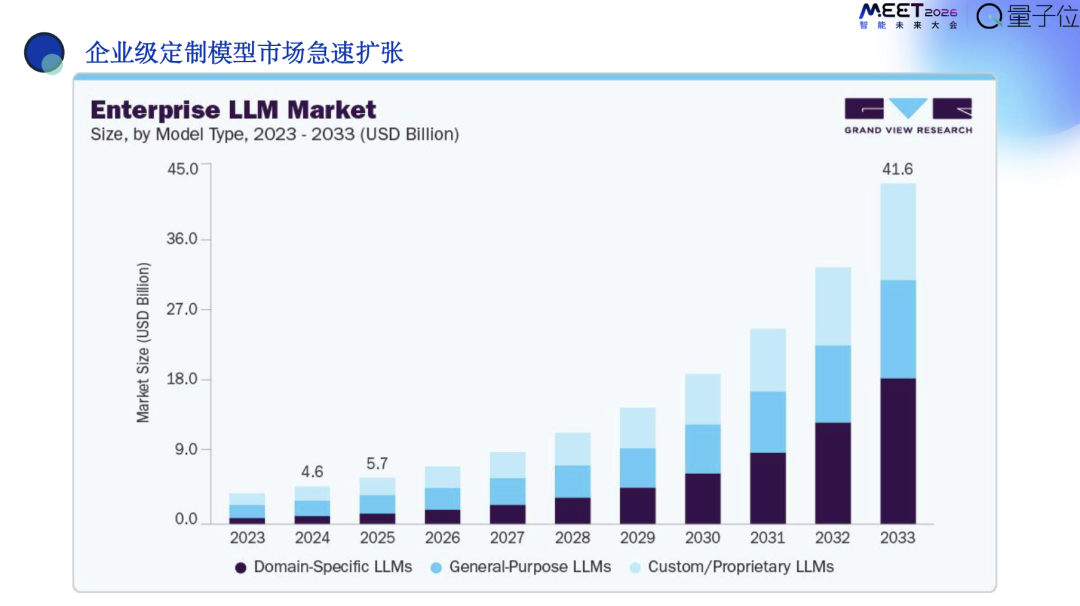
第一,Domain-Specific LLMs,就是领域大模型,做法律GPT、医疗GPT、教育GPT、或者说石油化工GPT这种都是领域大模型。
第二,通用大模型。
第三,私有大模型,这个大模型只能放在公司内部用,与外部隔离。
当然这个预测不一定准确,但潞晨可以观察一下它预测的未来趋势:
领域大模型未来到2033年的时候是最大的,大概占40%的市场份额;
通用大模型ChatGPT或者豆包或者Gemini占30%;
私有大模型也能占到30%。
Training As A Service
下一个问题,如果决定打造自己的私有大模型或者行业大模型,如何用好大模型?
在大模型ToB赛道,首先先不用考虑去做通用的ChatGPT或DeepSeek,因为不在同一个赛道。
如果用大模型做ToB的话,最关键的就是后训练或者Agent化。如果只是调通用大模型API的话,大家用的大模型都一模一样,显然没有任何差异性和竞争壁垒。
开源基模或者标准API,经过专业的后处理,才能战胜闭源模型。即给它足量的行业数据,最好是多模态数据,在高效优化情况下把大模型优化成行业专才。
这要求企业把两方面事情做好:
第一,最大化算力的效率,只要我在造私有大模型,肯定算力一个很大的账单。
第二,做出很好的微调模板,让用户快速做出自己行业模型、私有模型。
刚才提到目前业界龙头是Thinking Machines Lab的Tinker,潞晨打造了一个类似的产品,潞晨云的微调SDK。
潞晨希望打造成标准化模板式的服务,让用户只需用微调SDK就可以达到Training As A Service的效果。
不管是强化学习还是微调本质上都是Training,都是在算梯度,算出更好的梯度,梯度不断的更新参数。
开发人员、研究人员不管是石油公司的大模型开发人员还是金融公司、制药公司的,他们应该专注于自己的数据和业务,而不应该花太多时间构建自己的GPU集群、分布式计算、优化器等大模型基础设施的东西。
目前这类产品有两个极端:
第一,极端强调零代码微调,坏处用户对模型的控制力度大幅度下降,只能搭建demo级别的玩具,很难在真实业务落地。
第二,极端全手写裸机开发,全栈工程师自己搞定操作系统、分布式计算、优化器、张量并行、数据并行、集群运维等,显然浪费太多精力。
潞晨希望把复杂的流程变成函数级的管理。用户的目的本质上就是算梯度,由这几个函数负责把后台这些东西管理好,这样用户只需要调用这几个函数级的指令就可以快速的造出自己的行业模型、私有模型。
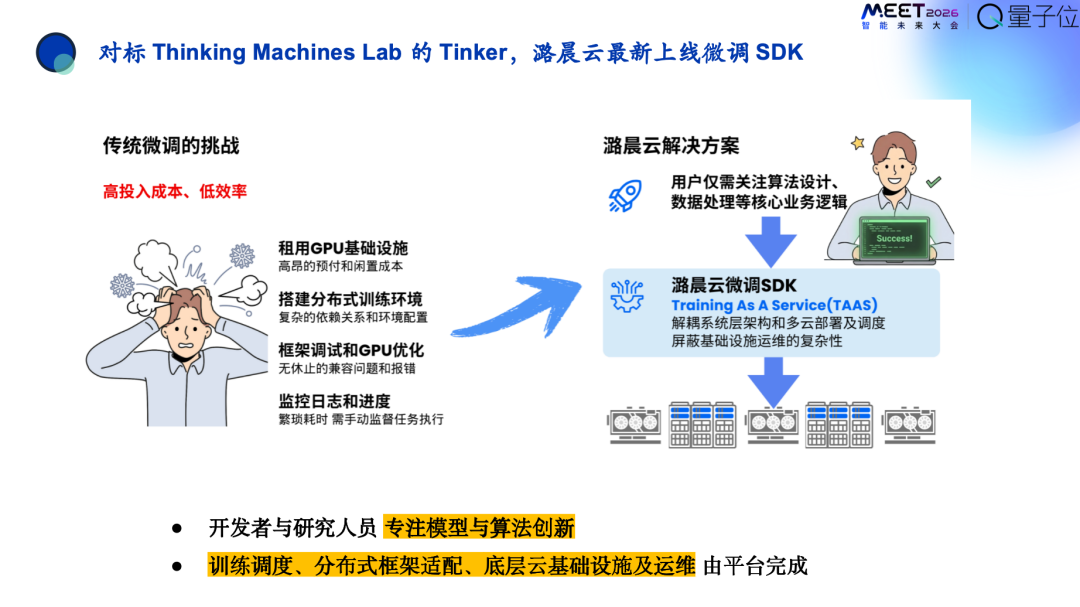
想让用户快速、简便、低成本地造出自己的行业模型、私有模型,关键在于实现工程与灵活度的最优平衡,既不是零代码的微调也不是全手写的裸机。
这是整个流程,通过这种方式按照SDK定义一下模型和数据一键式在云上训练部署,这样也能兼容Tinker的各种开源的SDK,实现监督微调、强化学习等。背后也集成了潞晨对算力性能优化的工具Colossal-AI来帮助用户降低成本。
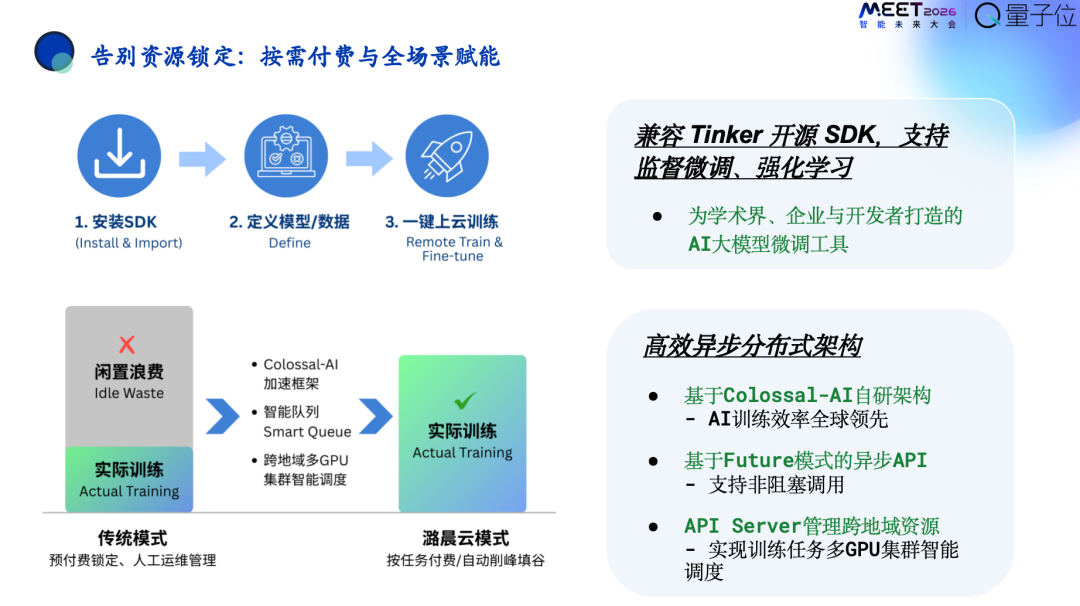
当然,用户也可以选择自己的框架、编程工具、任务调度方式等。
最后是一些真实案例:
某个世界五百强车企通过这套技术打造出多模态自动化的决策支持系统;
世界五百强电商的自动驾驶业务,在3D点云技术也在潞晨的帮助下得到很大的提升;
潞晨也助力另一家世界五百强车企打造智能座舱模型;
潞晨还帮助一家制造业世界500强企业打造了基于AI Agent及具身智能的供应链系统。


















 33
33

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









