



鹭羽 发自 凹非寺
量子位 | 公众号 QbitAI
2025都有哪些AI趋势,大神卡帕西的年终总结,正在火爆硅谷。
6大论断,硬核又颇有启发:
RLVR(可验证奖励强化学习)成为训练新阶段
大模型不应被类比为动物智能
Cursor展现了大模型应用的Next Level
Claude Code加速端侧智能体普及
Vibe Coding将重塑软件行业
Nano Banana重塑人机交互

新范式、新应用、新模型……回首望去,过去一年大模型带来的变革让人兴奋。
然而卡帕西大胆预言:
大模型的潜力,才刚刚挖掘10%。
一切不过是刚刚开始……
2025LLM年度回顾
为什么卡帕西认为大模型潜力只挖掘了10%?
一方面展现出强大的推理能力,另一方面也暴露出潜在的理解缺陷,既让人兴奋又让人谨慎,具体包括:
RLVR成为训练新阶段
在年初之前,全世界的大模型都基本遵循以下训练范式:
- 预训练:代表模型是GPT2和GPT3;
- SFT(监督微调):标志是2022年发布的InstructGPT;
- RLHF(人类反馈强化学习):2022年开始广泛流行。
而到了2025年,RLVR开始加入其中。
模型通过在可自动验证的奖励环境中进行强化学习训练,会自发地形成推理策略,比如将问题分解为中间计算、循环计算等,具体可参考DeepSeek R1。

而这些策略如果用旧范式其实极难实现,因为大模型的最佳推理轨迹和恢复过程并不清晰。
另外,与SFT和RLHF不同,RLVR由于涉及客观奖励函数的训练,优化时间较长。但事实也证明,RLVR能够带来较高的“能力/成本”比,它消耗了原先用于预训练的计算资源。
因此,RLVR成为这一年大模型能力增长的重要驱动因素,且在大模型规模相当的前提下,强化学习的运行时间大幅度延长。
随之而来的,还有一个全新的调控手段和相关的Scaling Law,可以通过生成更长的推理轨迹和增加思考时间,来控制能力作为测试时间计算量的函数。
2024年末的o1模型是首个RLVR模型的展示,但2025年初o3的发布才是明显的拐点。
大模型不应被类比为动物智能
2025年,整个行业第一次开始直观地理解大模型智能的形态——不是在动物进化,而是在召唤幽灵。
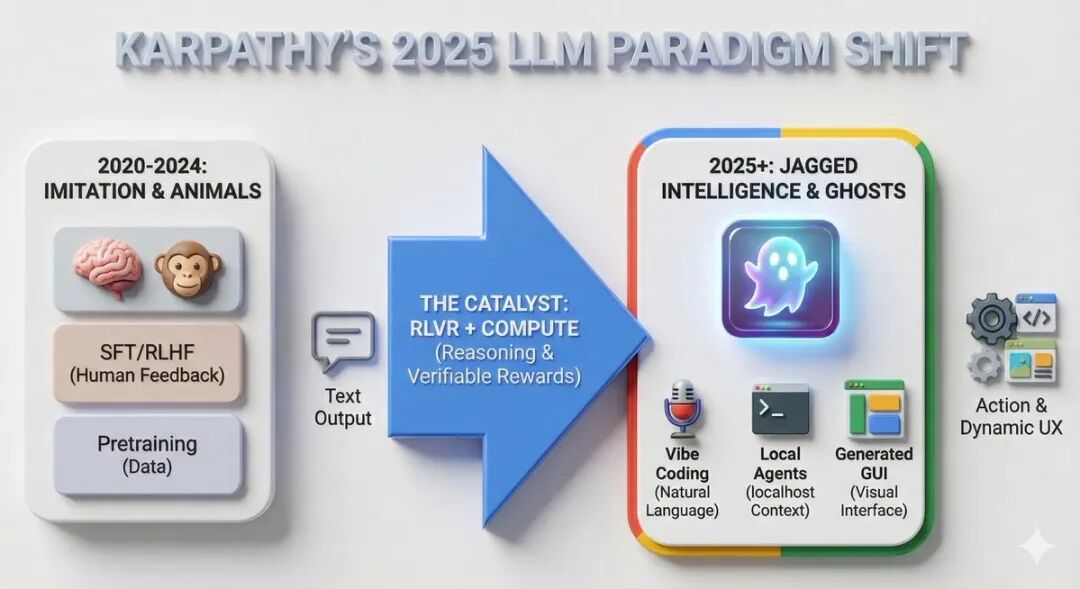
由于大模型技术栈的方方面面(神经架构、训练数据、训练算法,尤其是优化压力)都有所不同,所以会导致智能实体之间差异很大,如果单纯用看待动物的视角来理解它们其实是不对的。
从监督层面来讲,人类的神经网络是为了生存而优化,而大模型的神经网络则是为了模仿人类、获得奖励而优化的。
随着可验证领域采用RLVR,大模型的性能会快速爆发,并且整体呈现出锯齿状性能特征,也就是常说的锯齿智能。
简单来说,这样的大模型既是通才,也是认知能力有限的小学生,随时可能被越狱攻击,从而导致数据泄漏。
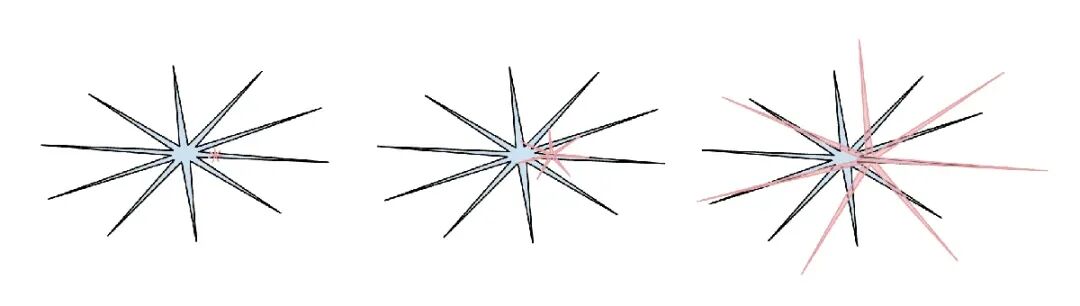
而这也能说明为什么卡帕西自己对基准测试普遍信任不足,核心问题就在于,基准测试几乎在构建之初就是可验证的环境,因此它们极易受到RLVR以及合成数据的影响。
研发大模型的团队也会不可避免地围绕基准测试构建环境,并形成锯齿状的模型表现,换言之,就是在测试集上进行训练。
这也就能解释,为什么现在的大模型可以在所有基准测试中取得压倒性胜利,但仍然未能实现AGI。
Cursor展现了大模型应用的Next Level
值得关注的是,Cursor的出现揭示了大模型应用的一个新层面,也就是今年人们常说的“Cursor for X”。

它不仅仅是一个模型接口,而是围绕模型调用构建的应用层,能够:
进行上下文工程(context engineering);
协调多个模型调用,并组成复杂的DAG(有向无环图),但需要精心衡量性能和成本;
提供特定应用的GUI;
带有自主性滑块(autonomy slider)。
2025年,人们已经花了大量时间集中讨论一个问题:新的AI应用层到底会有多“厚”?
这一层的价值是会被创建底层模型的大模型实验室完全榨干,还是会给垂直领域的大模型应用开发者留下生存空间?
在这一点上,卡帕西预测,大模型实验室未来会趋向于培养出一个“能力全面的大学毕业生”。
而大模型应用开发者则会负责组织、微调,并让一整支这样的“学生团队”真正动起来,成为特定行业里可以被部署、可以交付成果的专业人才,这将通过引入私有数据、传感器、执行器以及反馈闭环来实现。
Claude Code加速端侧智能体普及
Claude Code(CC)是首个令人信服的大模型智能体范例。
它利用一种循环的方式将工具使用和推理结合,以解决复杂问题。能够在个人电脑上运行,并将用户的私有环境、数据和上下文加以利用。
与之相反的是OpenAI,它们过多地将精力集中在由ChatGPT编排的云部署容器上,而不是端侧部署。
虽然云端运行的智能体集群通常被视作AGI的终极形态,但当前大模型能力参差不齐,且整体发展处于较为缓慢的过渡阶段。
在这种现实情况下,CC直接让智能体在本地电脑上运行,直接适配开发者工作流程,会更贴合实际需求。可以说,CC才是正确地把握了这一优先级,并将其包装成一种美观简约的命令行界面形式,彻底改变了人们对AI的传统认知。
它让AI不再是类似谷歌的访问网站,而是像栖息在个人电脑里的小精灵,创造了一种与AI互动的全新且独特的模式。
Vibe Coding将重塑软件行业
2025年也是AI跨越能力门槛的一年,只需要通过自然语言就能构建出各种程序。
有意思的是,氛围编程和前面提及的锯齿智能都是由卡帕西命名的,但彼时的他还并未料到,这两个词会成为2025年AI发展的最佳注解。
言归正传,在氛围编程的帮助下,编程不再局限于专业人士,任何人现在都能参与其中,而受过训练的专业人士也能通过它编写出更多的有意思的软件。
例如在卡帕西自己的nanochat项目中,他就用氛围编程的方式,在Rust语言中,编写了定制的高效BPE分词器,而不是采用现有的库或学习更多的Rust知识。
总的来说,他认为,氛围编程将重塑软件行业,并改变现有的工作内容。
Nano Banana重塑人机交互
要说今年最令人惊讶、最具范式转移意义的模型之一,就绕不开谷歌的Gemini Nano Banana。
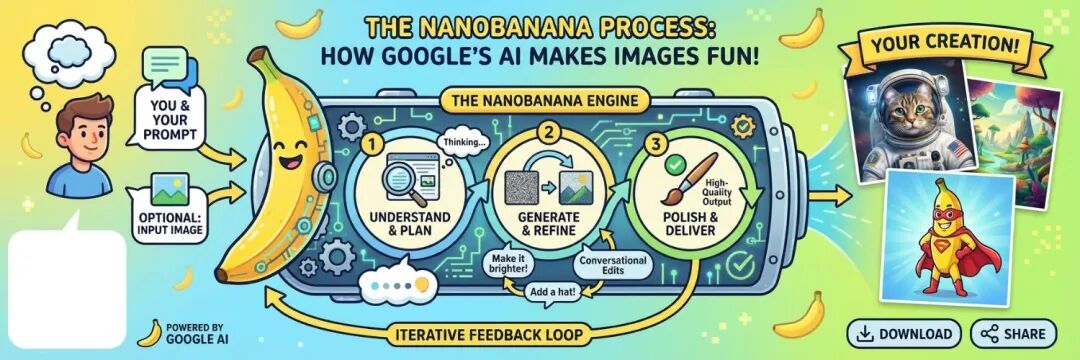
在卡帕西看来,大模型是继计算机时代后的下一个主要的计算范式,在很多层面上彼此之间存在相似性,尤其是用户界面和用户体验(UIUX)方面。
因为人们喜欢以视觉和空间的方式获取信息,所以大模型也应该提供类似格式,对文本进行美化和视觉排版。
而Nano Banana就展现了这一趋势,它并非只关注图像生成这一单一功能,它还将文本生成、图像生成和世界知识全部融合在一起,为未来大模型GUI发展提供了参考。
参考链接:
[1]https://karpathy.bearblog.dev/year-in-review-2025/


















 25
25

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









