



梦晨 发自 凹非寺
量子位 | 公众号 QbitAI
如今很多大模型都声称擅长数学,谁有真才实学?谁是靠背测试题“作弊”的?
有人在今年刚刚公布题目的匈牙利全国数学期末考试上做了一把全面测试。
很多模型一下子就“现原形”了。
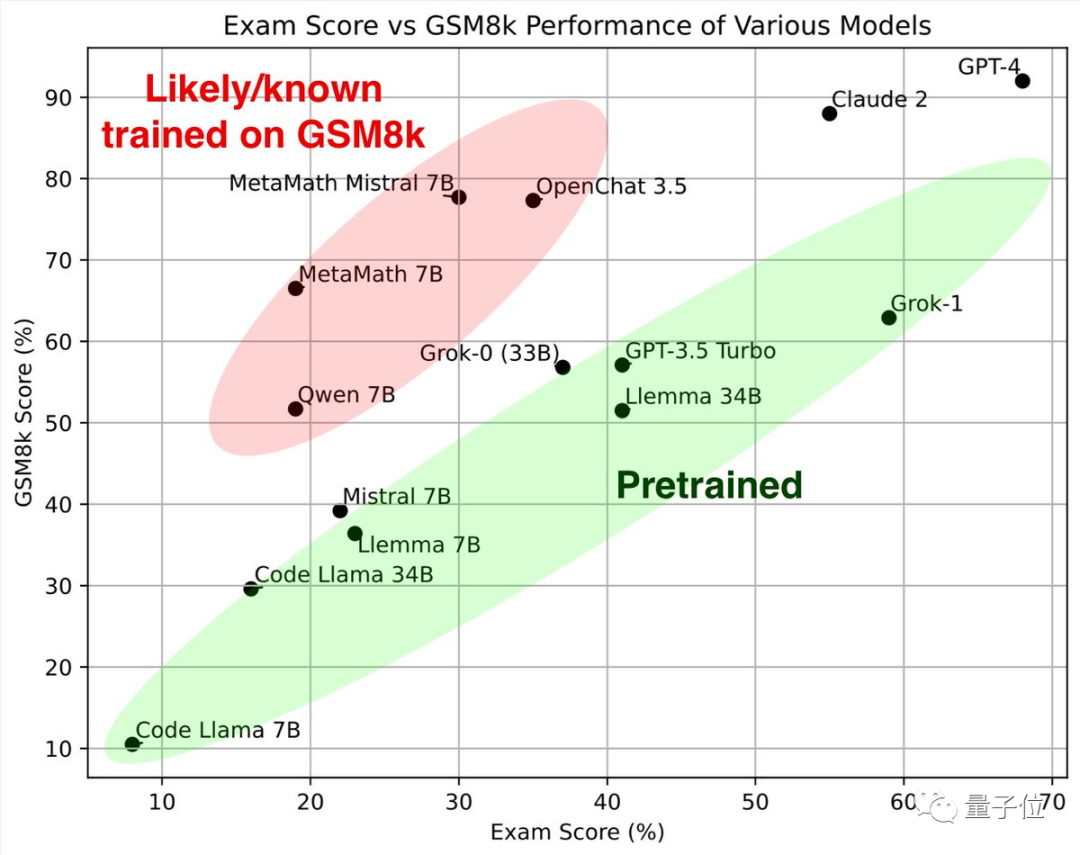
先看绿色部分,这些大模型在经典数学测试集GSM8k和全新卷子上取得的成绩差不多,共同组成参照标准。
再看红色部分,在GSM8K上的成绩显著高于同参数规模的大模型,一到全新卷子上成绩却明显下降,与同规模大模型差不多了。
研究者把他们归类为“疑似或已知在GSM8k上训练过”。

网友看过这项测试后表示,是时候开始在大模型从来没见过的题目上搞评测了。

也有人认为,这项测试+每个人实际上手使用大模型的经验,是目前唯一靠谱的评估手段。
马斯克Grok仅次于GPT-4,开源Llemma成绩出色
测试者Keiran Paster是多伦多大学博士生、谷歌学生研究者,也是测试中Lemma大模型的作者之一。
让大模型考匈牙利全国高中数学期末考试,这招出自马斯克的xAI。
xAI的Grok大模型发布时,除了几个常见的测试集,还额外做了这项测试,就是为了排除模型无意中在网络数据见过测试题的问题。
这个考试今年5月底才考完,当前大模型基本没机会见过这套试题。
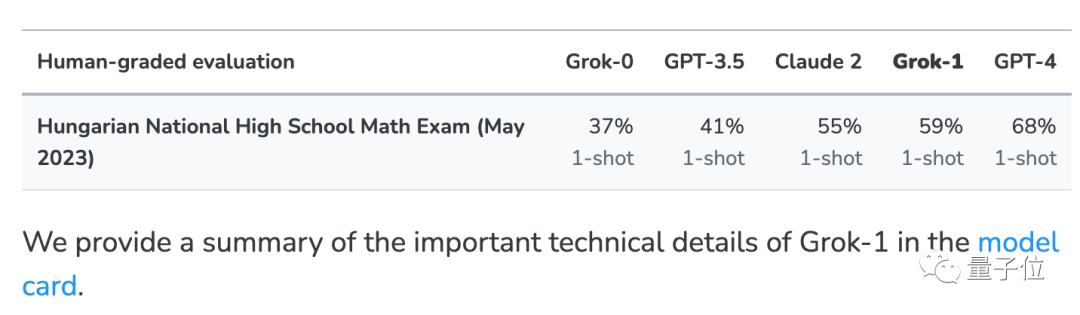
xAI发布时还公布了的GPT-3.5、GPT-4、Claude 2的成绩作为比较。
在这组数据基础上,Paster进一步测试了多个生成数学能力强的开源模型。
并把测试题目、测试脚本、各模型回答结果都开源在了Huggingface上,供大家检验以及进一步测试其他模型。
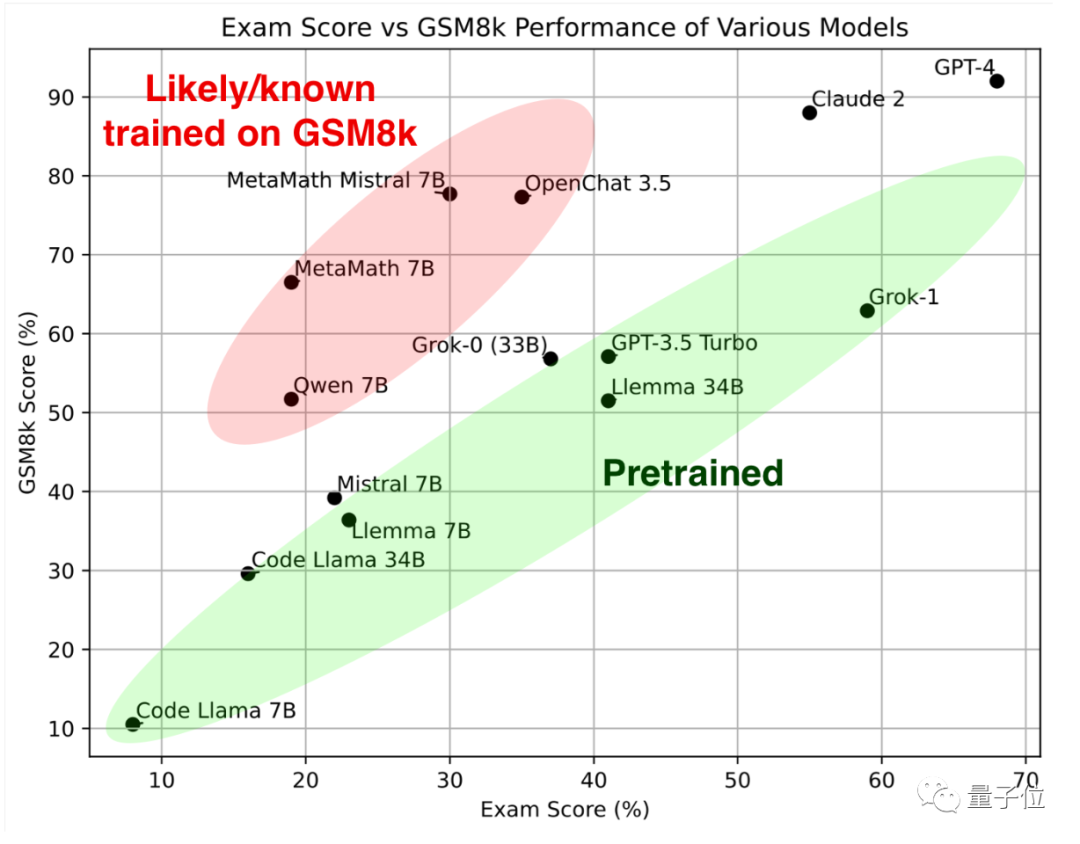
结果来看,GPT-4和Claude-2组成第一梯队,在GSM8k和新卷子上成绩都很高。
虽然这不代表GPT-4和Claude 2的训练数据中完全没有GSM8k的泄露题,但至少它俩泛化能力不错、能做对新题,就不计较了。
接下来,马斯克xAI的Grok-0(33B)和Grok-1(未公布参数规模)表现都不错。
Grok-1是“未作弊组”里成绩最高的,新卷子成绩甚至高过Claude 2。
Grok-0在GSM8k上的表现接近GPT3.5-Turbo,新卷子上略差一些。
除了上面这几个闭源模型,测试中其他的都是开源模型了。
Code Llama系列是Meta自己在Llama 2基础上微调的,主打根据自然语言生成代码,现在看来数学能力比同规模的模型稍差。

在Code Llama的基础上,多所大学和研究机构共同推出Llemma系列,并由EleutherAI开源。
团队从科学论文、包含数学的网络数据和数学代码中收集了Proof-Pile-2数据集,训练后的Llemma能使用工具和做形式定理证明,无需任何进一步的微调。
Llemma 34B在新卷子上与GPT-3.5 Turbo水平接近。

Mistral系列则是法国AI独角兽Mistral AI训练的,Apache2.0开源协议比Llama更宽松,成为羊驼家族之后最受开源社区欢迎的基础模型。
“过拟合组”里的OpenChat 3.5和MetaMath Mistral都是基于Mistral生态微调而来。
MetaMath和MAmmoTH Code则是基于Code Llama生态。
有在实际业务中选择开源大模型的就要小心避开这一组了,它们很有可能只是刷榜成绩好看,但实际能力弱于同规模模型。

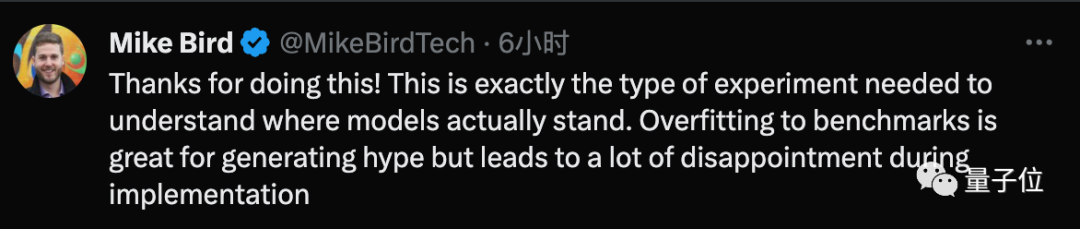
不少网友都对Paster这项试验表示感谢,认为这正是了解模型实际情况所需要的。
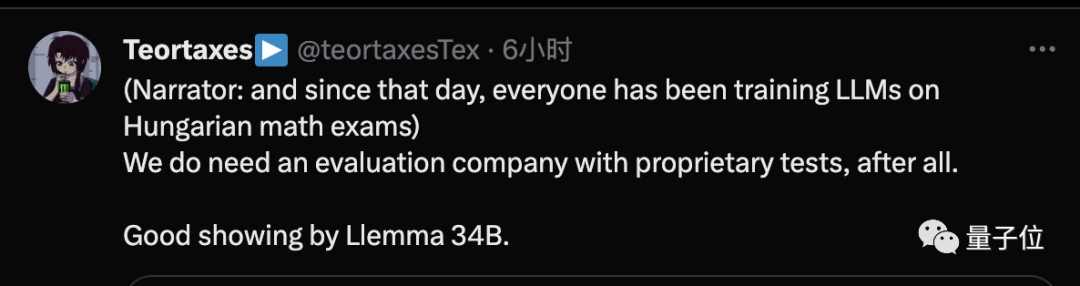
也有人提出担心:
从这一天起,所有训练大模型的人都会加入匈牙利历年数学考试题。
同时他认为,解决办法可能是有一家拥有专有测试的专门大模型评估公司。
另一项提议是建立一个逐年更新的测试基准,来缓和过度拟合问题。

参考链接:
[1]https://x.com/keirp1/status/1724518513874739618
[2]https://ai.meta.com/blog/code-llama-large-language-model-coding/
[3]https://arxiv.org/abs/2310.10631
— 完 —
「量子位2023人工智能年度评选」企业申报倒计时!
今年,量子位2023人工智能年度评选从企业、人物、产品/解决方案三大维度设立了5类奖项!扫码参与评选 ⬇️
MEET 2024大会已经开启报名!> 点此跳转报名 <

点这里👇关注我,记得标星噢


















 11
11

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









