 谷歌DeepMind与普林斯顿大学提升GPT-4能力:思维树助力复杂任务解决
谷歌DeepMind与普林斯顿大学提升GPT-4能力:思维树助力复杂任务解决




克雷西 发自 凹非寺
量子位 | 公众号 QbitAI
有了这个项目的支持,GPT-4可以完成更复杂的规划性任务了。
24点、创意写作,甚至填字游戏,通通不在话下。
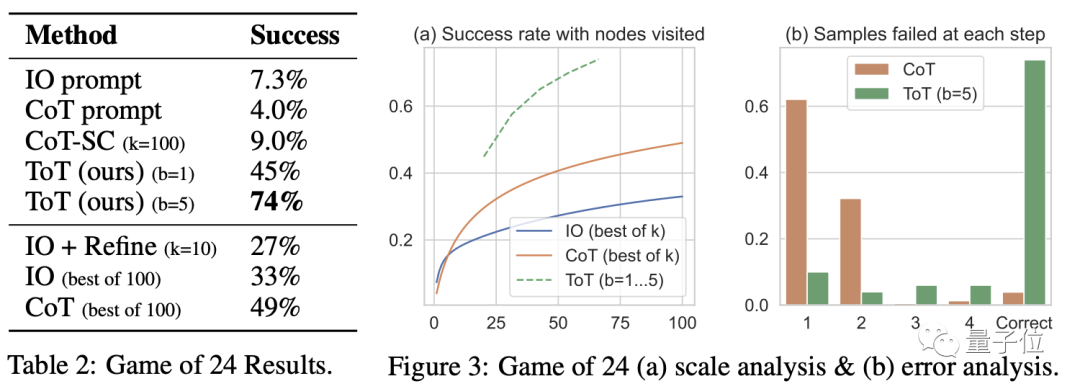
过去GPT-4在24点上寥寥4%的准确率,直接暴增至74%。
这个项目由刚合并的谷歌DeepMind实验室与普林斯顿大学共同打造,也是合并以来首批以该实验室名义发表的成果之一。
他们提出了名为“思维树”的概念,作为“思维链”的延伸。
“思维链”同样由谷歌推出,在相当程度上激发了大语言模型(LLM)解决复杂推理问题的能力。
“思维树”的出现弥补了LLM无法解决规划等前瞻性问题的不足。
能算24点,还会填字游戏
团队一共使用了24点、创意写作、填字游戏三种任务进行测试。
因为在他们看来,这些任务即使对于当前最优秀的LLM来说也十分困难。
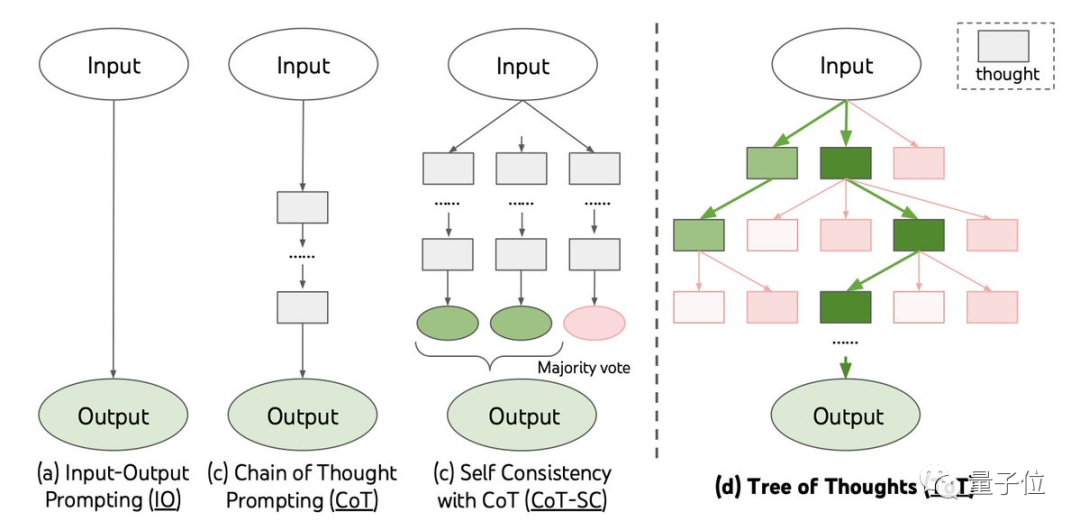
在测试过程中,思维树方法的表现会被与直接提问和思维链进行比较。
24点
团队将一个24点题库中的1362个问题按照难度进行排序。
判断难度的方式是人类解决问题所需时间。
之后,具有一定难度的、编号为901-1000的100道题目被用做测试数据。
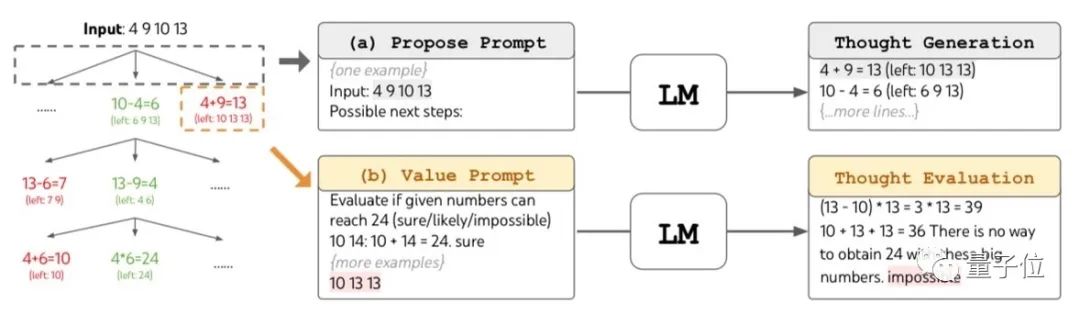
无论是直接提问还是用思维链方式,GPT-4的成功率均不足10%。
宽度b=1的思维树提示方式成功率为45%,而将b提高到5时成功率达到了74%。
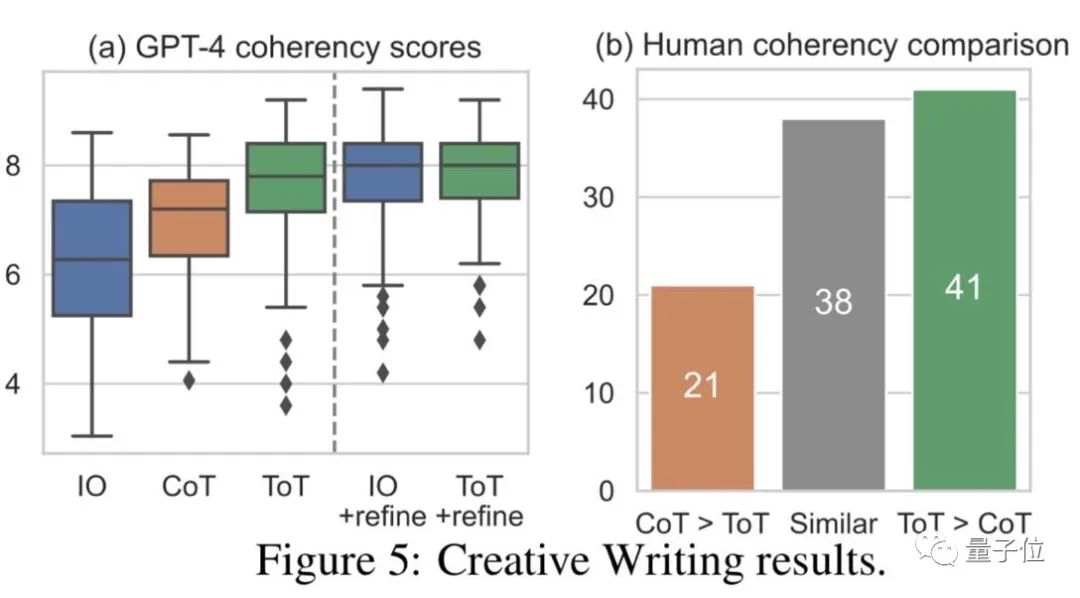
创意写作
而在创意写作任务中,团队随机生成了100个句子用于测试。
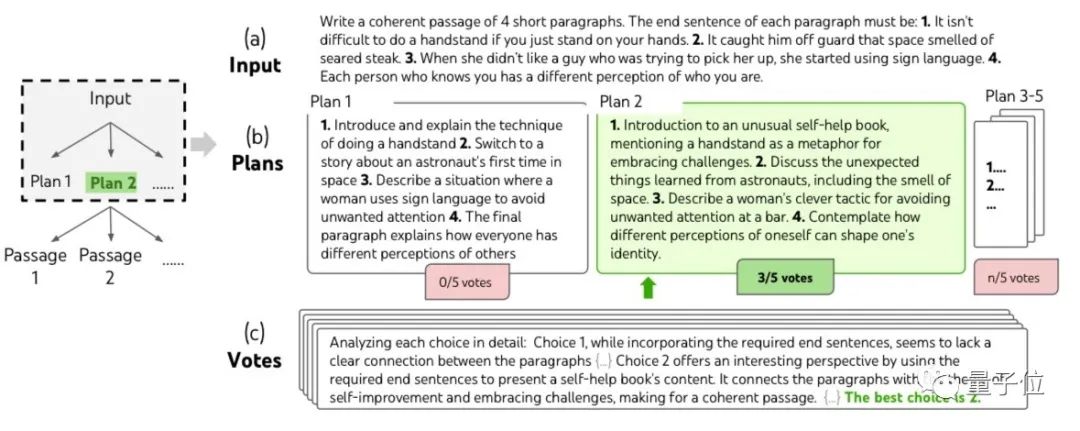
由于写作很难有对错之分,这轮测试的评价分为两部分。
第一部分是让未经专门训练的GPT-4对生成的文本进行1-10分的打分。
另一部分则是由人工对思维链和思维树两种提示方式下的作品进行定性比较。
结果显示,在没有进行优化时,GPT-4对思维树方式的评价均高于直接提问和思维链方式。
人工评判中认为思维树比思维链表现好的也最多。
填字游戏
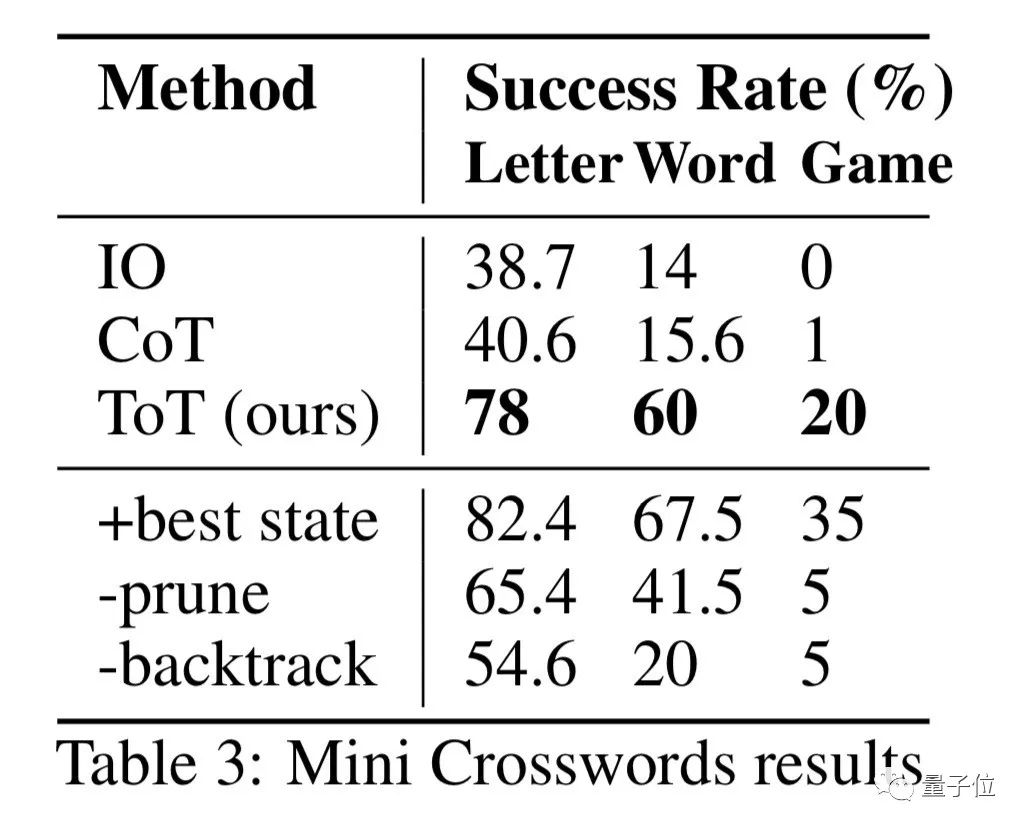
填字游戏方面,团队选取了156个5×5的游戏,并在1-96号中每隔5个选取一个作为测试数据。
另外,还有5个被用于创建提示。
最终,各种提示方式的表现分别从字母、单词和游戏整体的尺度上被记录。
从以上任意一个层次上看,思维树提示法的表现都更为出色,在字母层面的成功率更是高达78%。
从游戏整体上看,思维树方式的成功率尽管只有20%,但比起根本没成功过的其他方式,好了不要太多。
变链为树,随时自动回溯
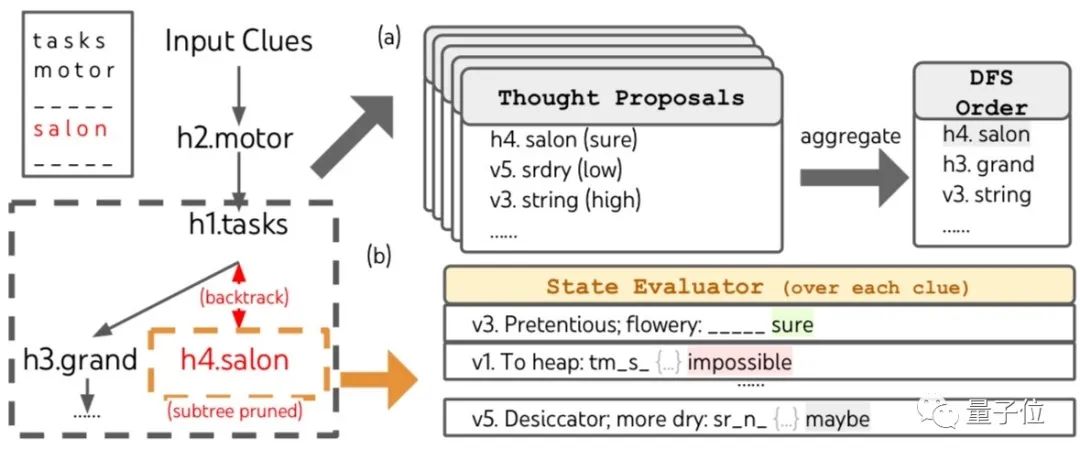
与思维链方式相比,思维树在开始增加了思维拆解的步骤。
根据目标的不同,拆解的结果可以是等式、写作计划或几组单词。

拆解的大小要适中,让LLM既能生成更多样本,又能对自身进行评估。
第二步是思维生成,为LLM后续的思维活动提供素材。
这步可以采用样本和命令两种模式。
前者适用于思维空间比较宽泛的情况,后者则在思维空间受限时表现更好。
第三步是状态评估,目的是评价解决问题的过程,为搜索算法接下来处理的内容和顺序提供启发。
根据评估结果,可以按需进行跳跃或回溯,从而提高任务的成功率。
不同于传统的编程或学习式评价方法,团队提出了让LLM进行评价,既高效又灵活。
与写作的评价方式类似,这一步中的评价模式包含打分和投票两种,只不过这里的投票不再是人工完成。
最后一步就是在思维树框架中运行搜索算法了,根据树结构的不同可以使用的算法也多种多样。
团队则主要研究了宽度优先和深度优先两种搜索算法。
如何体验
首先需要申请一个OpenAI(或其他LLM)的api。
当然,也可以调用自己的模型。
准备工作就绪之后,把GitHub项目克隆到本地:
git clone https://github.com/kyegomez/tree-of-thoughts然后打开目录:
cd tree-of-thoughts接着安装OpenAI(或其他)模型:
pip install openai然后创建一个Python脚本,内容如下:
from tree_of_thoughts import OpenAILanguageModel, CustomLanguageModel, TreeofThoughts, OptimizedOpenAILanguageModel, OptimizedTreeofThoughts
#v1
model = OpenAILanguageModel('api key')
#v2 parallel execution, caching, adaptive temperature
model = OptimizedOpenAILanguageModel('api key')
#choose search algorithm('BFS' or 'DFS')
search_algorithm = "BFS"
#cot or propose
strategy="cot"
# value or vote
evaluation_strategy = "value"
#create an instance of the tree of thoughts class v1
tree_of_thoughts = TreeofThoughts(model, search_algorithm)
#or v2 -> dynamic beam width -< adjust the beam width [b] dynamically based on the search depth quality of the generated thoughts
tree_of_thoughts= OptimizedTreeofThoughts(model, search_algorithm)
input_problem = "What are next generation reasoning methods for Large Language Models"
k = 5
T = 3
b = 5
vth = 0.5
#call the solve method with the input problem and other params
solution = tree_of_thoughts.solve(input_problem, k, T, b, vth, )
#use the solution in your production environment
print(solution)也可以集成自己的模型:
之后运行脚本就可以了。
论文地址:
https://arxiv.org/abs/2305.10601
GitHub页面:
https://github.com/ysymyth/tree-of-thought-llm


















 11
11

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









