 ResPA攻击方法研究
ResPA攻击方法研究





本文提出了一种基于残差扰动搜索的对抗样本生成方法ResPA,通过优化全局平坦性提升迁移性。针对现有方法过度依赖局部尖锐区域的问题,利用指数移动平均梯度捕获历史方向变化,以残差梯度定位扰动点,平衡初始损失与扰动损失。算法结合平坦性正则项,在迭代中通过均匀采样和梯度聚合更新参数,最终生成在Lp范数约束下的对抗样本。实验表明,该方法能有效避免局部最优,显著提高对抗样本在黑盒攻击中的迁移性能。核心创新在于残差梯度机制和平坦性优化策略,解决了传统方法因局部尖锐区域导致的迁移性下降问题。
发现的问题:现有的文献忽视了扰动方向的影响。
提出解决方法:依靠残差梯度作为扰动方向,引导对抗样本朝向损失函数的平坦区域。且新方法不是严重依赖源自当前梯度的局部平坦作为扰动方向,而是利用当前梯度和参考梯度之间的残差来捕捉全局扰动方向的变化。
看图解析
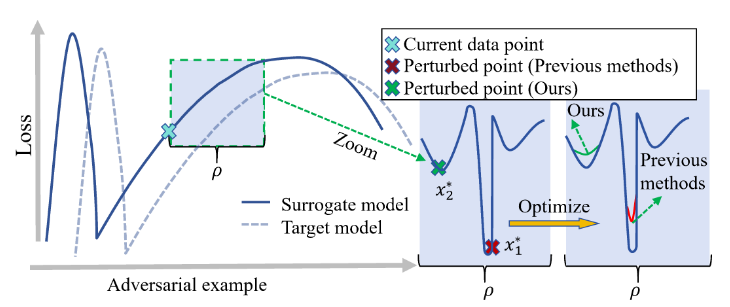
可以看出的是,以前的模型是通过优化最尖端区域的扰动点的损失,而新方法优化的是对全局情况有利的扰动点的损失。
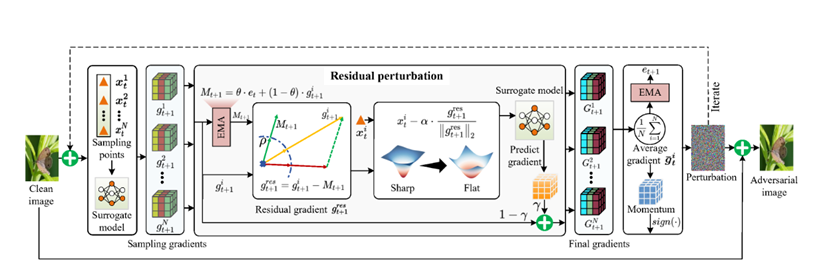
相关公式及理解
1.交叉熵损失函数
![]()
其中x为输入图像,y为其对应的真实标签,代理模型1的分类器输出记为![]() ,其中C是类别数,y=0或1是one-hot编码向量,满足系数与第k类,yk=1,否则yk=0.
,其中C是类别数,y=0或1是one-hot编码向量,满足系数与第k类,yk=1,否则yk=0.
实验目的,是使得对抗样本使分类器输出一个与真实标签不同的标签![]() ,同时保持人类不可感知。
,同时保持人类不可感知。
2.不可感知性
通过遵守约束
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 178
178

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









