




ML DL RL
-
✅ 真需求 :基于公开的 RNA 骨架结构,生成 RNA 序列,探索高效设计RNA分子方法,为医药多个领域提供基础支持。
-
✅ 真数据 :两千余个公开的 RNA 骨架结构及其对应的真实序列,拒绝“纸上谈兵”。
学习竞赛通用流程
针对 赛题数据 学习数据探索分析、数据清洗、特征工程、模型训练、模型验证、结果输出的全部竞赛实践流程。
需求分析
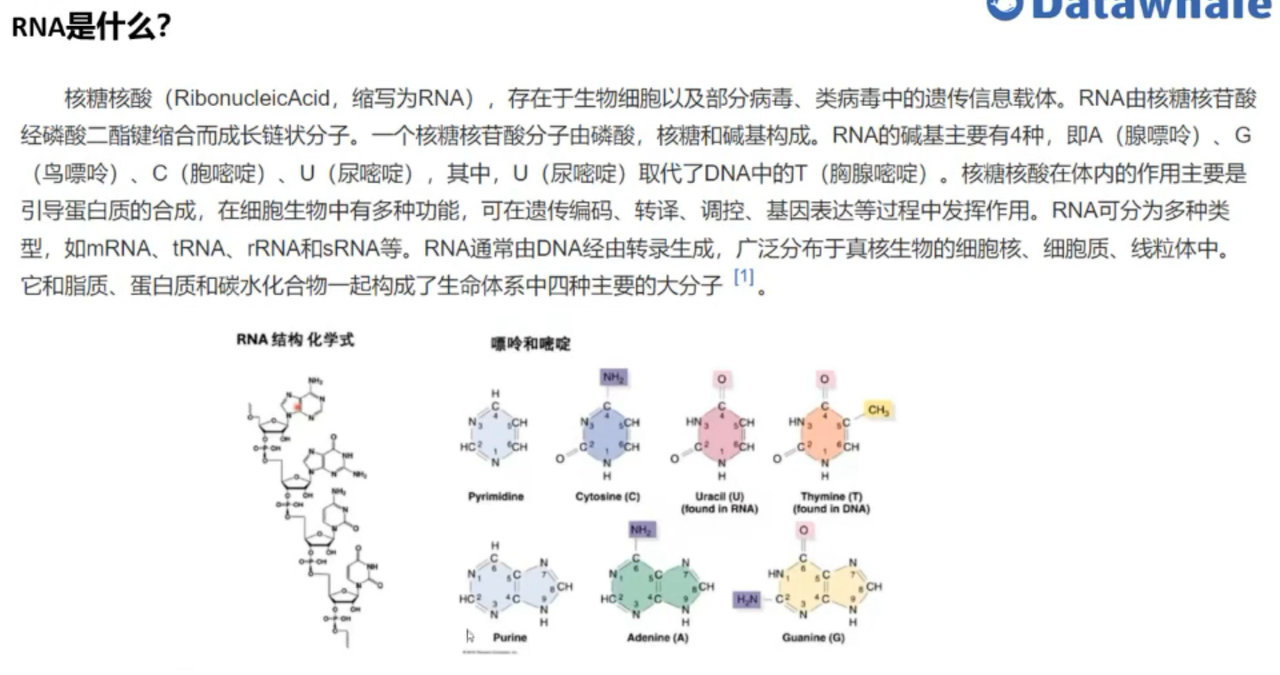
RNA (核糖核酸) 在细胞生命活动中扮演着至关重要的角色,从基因表达调控到催化生化反应,都离不开 RNA 的参与。RNA 的功能很大程度上取决于其三维 (3D) 结构。理解 RNA 的结构与功能之间的关系,是生物学和生物技术领域的核心挑战之一。RNA 折叠 是指 RNA 序列自发形成特定三维结构的过程。而 RNA 逆折叠 则是一个更具挑战性的问题,即基于给定的RNA 三维骨架结构设计出能够折叠成这种结构的 RNA 序列。
核心是 RNA 逆折叠问题,具体来说,是基于给定的 RNA 三维骨架结构,生成一个或多个 RNA 序列,使得这些序列能够折叠并尽可能接近给定的目标三维骨架结构。评估标准是序列的恢复率 (recovery rate),即算法生成的 RNA 序列,在多大程度上与真实能够折叠成目标结构的 RNA 序列相似。恢复率越高,表明算法性能越好。
数据集
初赛官方提供了2个zip文件,其中RNA_design_public.zip 是RNA的训练样本数据,dummy_submit.zip是提交的样例数据
官方的数据下载观察文件的结构
RNAdesignv1
|- train
|- coords
|- seqs选择seqs其中的一个文件夹打开可以看到如下信息
>1A9N_1_Q
CCUGGUAUUGCAGUACCUCCAGGU1A9N_1_Q 就是这个RNA的名称 CCUGGUAUUGCAGUACCUCCAGGU 就是这个RNA的序列结构,需要注意的是,RNA序列只有 AUCG 4个碱基组成 同样的coords文件夹中存放的是RNA折叠后的空间信息,采用npy文件保存 我们可以使用numpy对文件进行读取
import numpy as np
file_path= "./RNAdesignv1/train/coords/1A9N_1_Q.npy"
data = np.load(file_path)
print(data.shape)
#(24, 7, 3)可以看到数组是 2473 的数组 其中 24是RNA的序列长度 7就是 RNA 骨架原子 3就是每个原子的坐标为三维坐标(x, y, z)。如果原始数据中某个原子不存在,则该位置会以 NaN 填充。
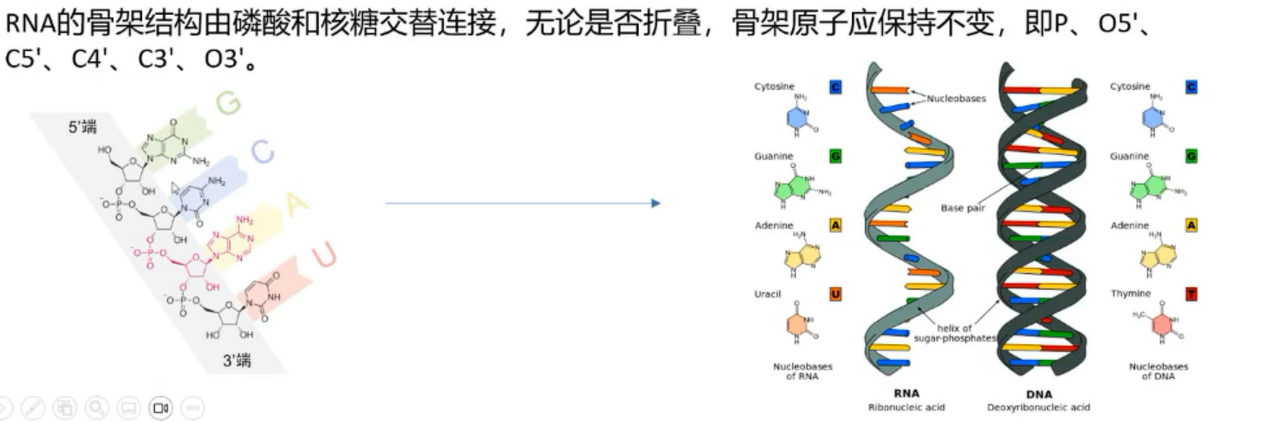
7个RNA骨架分别如下
-
RNA 骨架原子 (6 个):
-
P(磷酸基团)
-
O5'(5' 氧原子)
-
C5'(5' 碳原子)
-
C4'(4' 碳原子)
-
C3'(3' 碳原子)
-
O3'(3' 氧原子)
-
RNA 侧链原子 (1 个):
到这里我们就了解了赛题中的全部数据的含义。
到这里我们大概就知道了比赛的目的,通过(L,7,3)的数据信息 推测 (L,4)的可能的RNA序列,类似端到端的效果。
尝试理解baseline (具体代码及输出见资源)
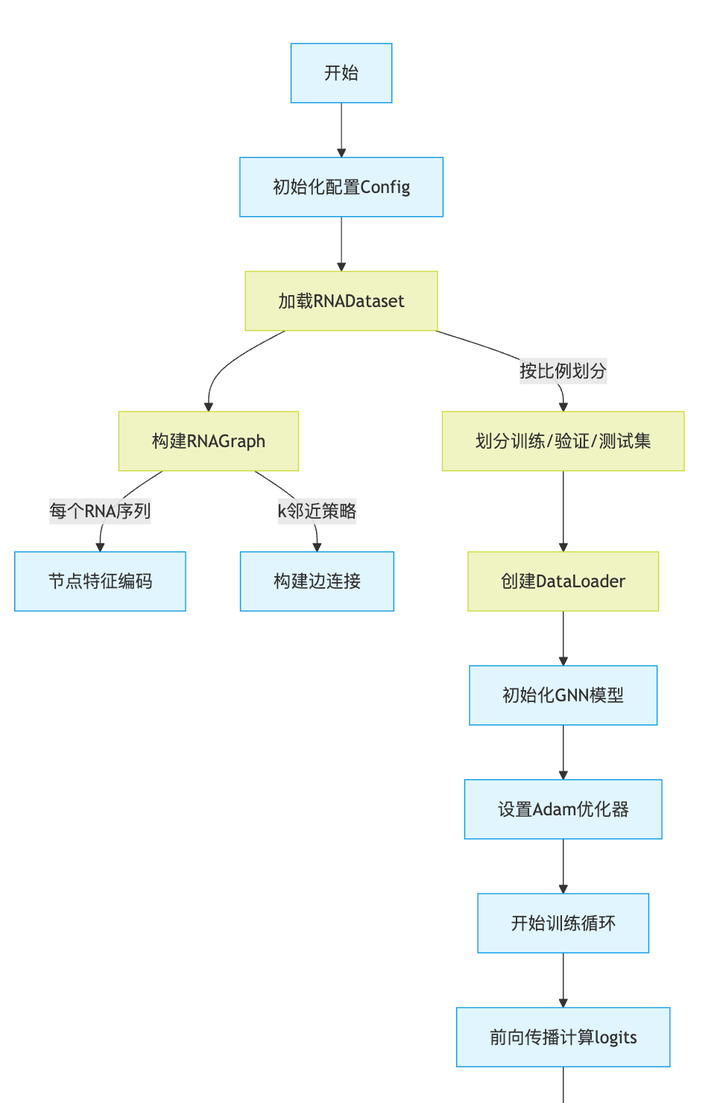

diffusion_baseline
rna逆折叠 diffusionunzip file.zip -d /path/to/directory
我会使用工具来递归地读取 sais_third_medicine_baseline 文件夹的内容,展示三层目录结构。
Ran tool
让我们继续查看 __MACOSX 目录:
Ran tool
让我们查看 RNA_design_public 目录:
Ran tool
让我们查看 RNAdesignv1 目录:
Ran tool
让我们查看 train 目录:
Ran tool
这是完整的三层目录结构:
```
sais_third_medicine_baseline/
├── baseline_4.ipynb (0.0B)
├── baseline.ipynb (12KB)
├── __MACOSX/
│ ├── RNA_design_public/
│ └── ._RNA_design_public (163B)
└── RNA_design_public/
├── public.ipynb (59KB)
├── .DS_Store (6.0KB)
└── RNAdesignv1/
├── .DS_Store (6.0KB)
└── train/
├── .DS_Store (6.0KB)
├── seqs/
└── coords/
```
这个目录结构显示了:
1. 根目录包含两个 notebook 文件和两个子目录
2. `__MACOSX` 目录是 macOS 系统生成的元数据目录
3. `RNA_design_public` 目录包含主要的项目文件,包括:
- `public.ipynb` notebook
- `RNAdesignv1` 子目录,其中包含训练数据目录
4. 训练数据分为 `seqs` 和 `coords` 两个子目录
注意:有一些 `.DS_Store` 文件,这些是 macOS 系统生成的隐藏文件,用于存储目录的显示属性。
导入模块
基于RiboDiffusion论文优化baseline代码。根据论文内容,RiboDiffusion的主要创新点包括:
- 使用扩散模型进行RNA序列生成
- 结合结构模块(Structure Module)和序列模块(Sequence Module)
- 使用Transformer架构处理序列信息
- 采用多样化采样策略
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 460
460


 到【灌水乐园】发言
到【灌水乐园】发言








