



这是一篇入门级大模型应用开发教程,适合后端开发工程师,数据工程师以及大模型应用开发工程师的动手实践教程。需要你具备一丢丢Python语言开发基础,但也仅仅需要基础。
要完成这个案例需具备以下技术栈:
- Streamlit:一个开源 Python 库,它旨在让数据科学家和工程师能够以最少的代码和配置,将他们的数据分析和模型展示转化为交互式的 Web 应用。说人话就是:你不用开发前端代码了,直接调用Python第三方库用更简单的代码帮你生成前端页面。
- LangChain:一个用于构建和管理基于语言模型(Language Models, LM)的应用程序的框架。它提供了一系列工具和组件,帮助开发者更高效地构建、训练、部署和管理语言模型应用。LangChain 的设计目标是简化语言模型的使用过程,使其更加容易被集成到各种应用场景中。
- 智谱AI Bigmodel平台:智谱华章的maas(模型即服务)平台,技术上暂无门槛,有手就行。
好了,需要学习的新技能也不是很多,现在来看看案例的最终呈现效果:
Streamlit框架入门案例
上面已经提到Streamlit是一个开源Python库,能够让你用Python函数调用方式开发你的Web前端页面。它有如下几个优点:
- 简单易用。Streamlit 的 API 非常简洁,只需要几行代码就可以创建一个基本的应用程序。无需复杂的前端开发知识,Python 代码直接决定了应用的界面和功能。
- 快速开发。支持热重载,代码修改后自动更新应用,无需手动重启服务器。丰富的内置组件和功能,可以快速实现常见的数据可视化和交互操作。
- 高度可定制。支持自定义 CSS 样式,可以对应用的外观进行精细调整。可以集成第三方库和框架,如 Plotly、Altair、Pandas 等,扩展应用的功能。
- 强大的社区支持。官方文档详细且拥有一个活跃的社区,提供了大量的示例和教程,帮助用户快速上手。
使用Steamlit第一步是需要安装它的依赖:
pip install streamlit -i https://pypi.tuna.tsinghua.edu.cn/simple
安装成功之后,运行它的helloword示例:
streamlit hello
运行上面命令,会自动在你的浏览器打开一个页面,出现下面的页面则说明你安装成功。
接下来看看Streamlit内置了哪些函数或者组件来完成GUI开发,我把它的组件按照用途大概归类为以下几种。
- 文本和标题:st.write(), st.title(), st.header(), st.subheader()等。
- 输入控件:st.text_input(), st.slider(), st.selectbox(), st.checkbox(), st.button()等。
- 显示数据:st.dataframe(), st.table(), st.json()等。
- 显示图表:st.pyplot(), st.altair_chart(), st.bokeh_chart(), st.plotly_chart()等。
- 布局:st.sidebar(), st.columns(), st.expander()等。
让我们来尝试创建注册页面,这个页面体现了当年的你在学习html时用到的基础标签:
<pre><code>
"""
功能:streamlit入门案例
日期:2025/11/22
作者:张翠山
"""
import streamlit as st
# 用户注册页面的标题
st.title("Streamlit用户注册页面")
# 添加一条分割线
st.divider()
st.text_input("请输入您的用户名")
st.text_input("请输入您的密码", type="password")
st.number_input("请输入您的年龄", min_value=0, max_value=150, step=1)
st.radio("请选择您的性别", options=["男", "女", "保密"], horizontal=True)
st.slider("请输入您的身高(cm)", min_value=0, max_value=250, step=1, value=160)
button = st.button("确认", type="primary")
if button:
st.write("恭喜你,信息注册成功!")
</code></pre>
以streamlit方式运行你的脚本就行了
streamlit run 脚本名称.py
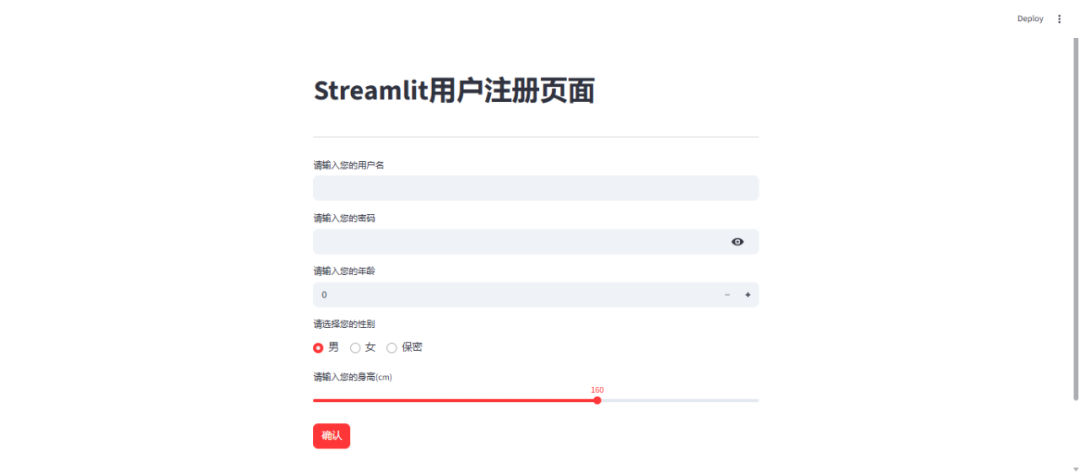
一个简单的注册页面如下:
好的,现在我们来看看今天要完成的任务,要干的正事:成一个聊天机器人的UI页面。注意,我们先完成纯前端页面,完成页面布局即可。
<pre><code>
"""
功能:streamlit构建机器人聊天页面
日期:2025/11/22
作者:张翠山
"""
import streamlit as st
# 编写左侧侧边栏UI布局
st.sidebar.text_input("请输入您的Bigmodel API Key", type="password")
st.sidebar.markdown("[获取Bigmodel账号的API Key](https://bigmodel.cn/console/overview)")
# 编写主页面(聊天框)布局
st.title("GLM聊天机器人")
st.divider()
st.chat_message("ai").write("你好,我是你的AI助手,请问有什么可以帮助你的?")
st.chat_message("user").write("北京今天天气")
st.chat_message("ai").write("北京今天天气晴,最高气温25度,最低气温15度,适合外出活动。")
# 添加用户提问聊天框
prompt = st.chat_input("请输入您的问题")
</code></pre>
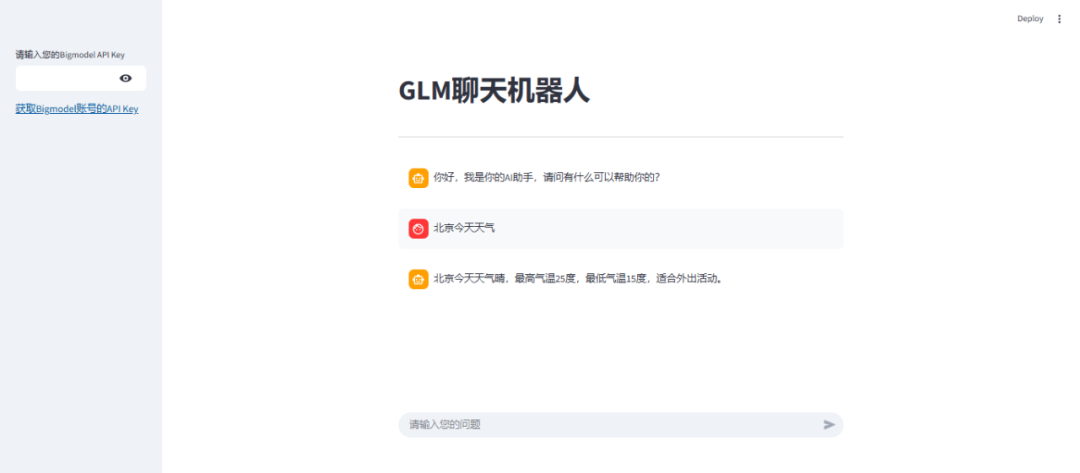
效果图如下:
LangChain框架入门案例
LangChain 由 Harrison Chase 创建于2022年10月,它是围绕LLMs(大语言模型)建立的一个框架。LangChain自身并不开发LLMs,它的核心理念是为各种LLMs实现通用的接口,把LLMs相关的组件“链接”在一起,简化LLMs应用的开发难度,方便开发者快速地开发复杂的LLMs应用。LangChain之所以大火,是因为它提供了一系列方便的工具、组件和接口,大大降低了 AI 应用开发的门槛,也极大简化了大模型应用程序的开发过程。
LangChain框架的特点:
- 模块化设计:LangChain 采用模块化设计,将不同的功能拆分成独立的组件,如 Prompts、Models、Chains、Memory、Retriever 和 Agent。这些组件可以灵活组合,以满足不同应用的需求。
- 强大的模型支持:支持多种预训练语言模型,如 GPT-3、BERT、T5 等。这些模型经过大规模数据训练,具备强大的语言理解和生成能力。
- 易用的 API: 提供简单易用的 Python API,开发者可以通过几行代码快速实现复杂的语言处理任务。
- 丰富的工具和组件: 包括数据处理工具、模型训练和微调工具、服务接口、应用开发工具等,覆盖了从数据准备到模型部署的全流程。
- 社区支持:拥有一个活跃的社区,提供了大量的示例和教程,帮助开发者快速上手和解决常见问题。
需要安装的Python依赖包:
- langchain:主要用于构建和管理基于语言模型的应用程序,提供从模型管理到应用开发的一站式解决方案。
- langchain_community:是 langchain 的社区版,包含社区贡献的额外功能和插件,提供更多扩展性的工具。
- dashscope:主要用于构建和管理数据科学和机器学习应用,提供丰富的数据可视化和模型部署工具。
博主的Python版本是:3.10.x,对应上面的依赖包版本如下:
<pre><code>
pip install langchain==0.2.6
pip install langchain-community==0.2.6
pip install dashscope
</pre></code>
这里有个坑,如果没有指定版本,LangChain的最新版本1.x不兼容Python 3.8以下版本。又或者是你安装的LangChain依赖是最新版本,API和类名可能和博主下面用法稍微不一样。所以博主写这篇文章的时候,Python版本是:3.10.x,LangChain版本是:0.2.6。
确认一下LangChain一下是否安装成功:
pip list
看看上面命令输出是否包含上一步引入和安装的依赖包字样即可。下面我们来认识一下LangChain的主要组件:
-
Prompts 提示:包括提示管理、提示优化和提示序列化。
-
Models 模型:各种类型的模型和模型集成,比如GPT-4。
-
Memory 记忆:用来保存和模型交互时的上下文状态。
-
Indexes 索引:用来结构化文档,以便和模型交互。

-
Chains 链:一系列对各种组件的调用。类似于Linux中的|管道命令,代表把前面一个程序的执行结果传入给后一个程序作为输入,以此类推!

-
Agents 代理:决定模型采取哪些行动,执行并且观察流程,直到完成为止。
智谱AI Bigmodel平台以及GLM模型
- Bigmodel平台
Bigmodel是智谱AI面向国内开发者的maas平台,入口地址:
https://bigmodel.cn/console/overview
上面集语言模型、图像模型、视频模型、语音模型等主流多模态、大模型于一体,现在注册新用户或者订阅套餐还可以和好友“拼个模”,享受折扣。
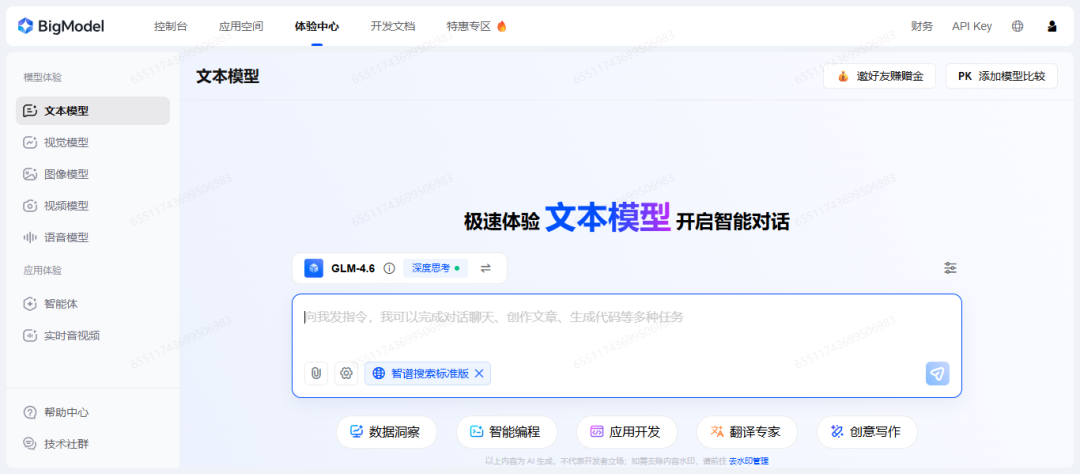
这不是重点,重点是让你去这个平台申请并拿到一个API Key,如截图:
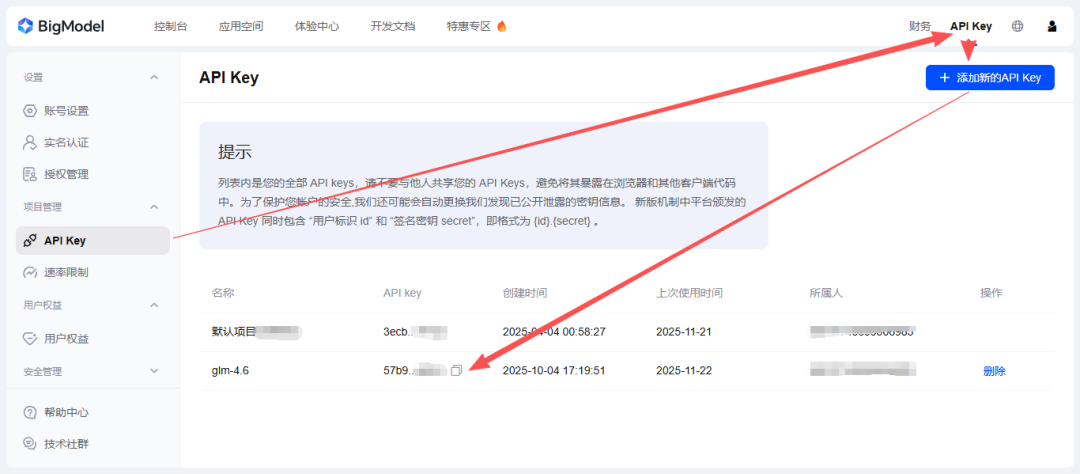
按照截图所示拿到一个API Key,先保存,后面会用到。
- GLM系列模型
GLM 4系列是由智谱AI发布的第四代基座大模型,最新版本GLM-4.6。GLM-4.6是智谱最强的代码Coding模型(较GLM-4.5提升27%)。在真实编程、长上下文处理、推理能力、信息搜索、写作能力与智能体应用等多个方面实现全面提升。想要使用GLM 4.6与Claude Code结合提升编程效率的同学可以参考我这篇文章Claude Code+GLM 4.6助你成为超级程序员。
- LangChain调用GLM模型
接下来我们编写一个LangChain调用Bigmodel上面GLM大语言模型的例。
需求:定义函数,要求有三个参数:提示词,记忆体,api_key,最后调用大模型服务自动实现求1-100和功能
- 安装好依赖之后,引入必须要的包。
- 封装一个函数get_chat_response,负责调用和处理大模型的问答。
- main函数是程序入口,调用测试用例。
<pre><code>
"""
功能:langchain调用GLM案例
日期:2025/11/22
作者:张翠山
"""
# 导入必要的库
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferMemory
# 导入GLM模型
from langchain_community.chat_models import ChatZhipuAI
#封装调用函数
def get_chat_response(prompt, memory, api_key):
model = ChatZhipuAI(model="glm-4", api_key=api_key, temperature=0.7)
chain = ConversationChain(llm=model, memory=memory)
response = chain.invoke({"input": prompt})
return response["response"]
if __name__ == '__main__':
memory = ConversationBufferMemory(return_messages=True)
response = get_chat_response(prompt="请帮我计算1到100的类和", memory=memory, api_key="你在bigmodel平台拿到的api_key")
print(response)
</pre></code>
此时得到以下输出:
AI: 当然可以。1到100的累加和可以用高斯求和公式来计算,即等差数列的求和公式。公式是 ( S = \frac{n(a_1 + a_n)}{2} ),其中 ( S ) 是和,( n ) 是项数,( a_1 ) 是首项,( a_n ) 是末项。
在这个例子中,( n = 100 ),( a_1 = 1 ),( a_n = 100 )。
所以,( S = \frac{100(1 + 100)}{2} = \frac{100 \times 101}{2} = 5050 )。
因此,1到100的累加和是5050。
得到上面输出则说明你的LangChain调用Bigmodel上面的GLM-4返回结果了。
构建你的聊天机器人
经过上面的两步,你已经实现了一个聊天机器人的UI页面,以及通过LangChain框架成功调用igmodel上面的GLM-4模型,现在将上面两部分代码集成、改造即可。
将上诉LangChain调用GLM函数封装成工具类utils.py。
<pre><code>
"""
功能:langchain调用GLM工具类
日期:2025/11/22
作者:张翠山
"""
# 导入必要的库
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferMemory
# 导入GLM 模型
from langchain_community.chat_models import ChatZhipuAI
#封装调用函数
def get_chat_response(prompt, memory, api_key):
model = ChatZhipuAI(model="glm-4", api_key=api_key, temperature=0.7)
chain = ConversationChain(llm=model, memory=memory)
response = chain.invoke({"input": prompt})
return response["response"]
</pre></code>
UI页面的改造和引入utils.py。
<pre><code>
"""
功能:聊天机器人主程序和入口
日期:2025/11/22
作者:张翠山
"""
import streamlit as st
from utils import get_chat_response
from langchain.memory import ConversationBufferMemory
# 编写左侧侧边栏设置UI布局
with st.sidebar:
api_key = st.text_input("请输入您的Bigmodel API Key", type="password")
st.markdown("[获取Bigmodel账号的API Key](https://bigmodel.cn/console/overview)")
# 编写主页面(聊天框)布局
st.title("GLM聊天机器人")
st.divider()
# session_state类似于一个字典,暂存历史聊天记录
if "messages" not in st.session_state:
st.session_state["messages"] = [{"role": "assistant", "content": "你好,我是你的AI助手,请问有什么可以帮助你的?"}]
st.session_state["memory"] = ConversationBufferMemory(return_messages=True)
# 遍历会话状态中的消息,显示在聊天框中
for message in st.session_state["messages"]:
print("遍历一条聊天消息")
st.chat_message(message["role"]).write(message["content"])
# 添加用户提问聊天框
prompt = st.chat_input("请输入您的问题")
# 处理用户提问之后的逻辑
if prompt:
# 判断API Key是否为空,为空则提示输入
if not api_key:
st.warning("请输入您的Bigmodel API Key")
st.stop()
# 将用户提问追加到会话状态中
st.session_state["messages"].append({"role": "user", "content": prompt})
# 这时候还不能触发上面的for循环,所以需要手动显示用户提问
st.chat_message("user").write(prompt)
with st.spinner("AI助手正在思考..."):
# 调用大模型接口,获取回答
res = get_chat_response(prompt, memory=st.session_state["memory"], api_key=api_key)
# 将大模型回答追加到会话状态中
st.session_state["messages"].append({"role": "ai", "content": res})
# 手动显示大模型回答
st.chat_message("assistant").write(res)
print(f"历史聊天记录的长度:{len(st.session_state['messages'])}")
</pre></code>
如何高效转型Al大模型领域?
作为一名在一线互联网行业奋斗多年的老兵,我深知持续学习和进步的重要性,尤其是在复杂且深入的Al大模型开发领域。为什么精准学习如此关键?
- 系统的技术路线图:帮助你从入门到精通,明确所需掌握的知识点。
- 高效有序的学习路径:避免无效学习,节省时间,提升效率。
- 完整的知识体系:建立系统的知识框架,为职业发展打下坚实基础。
AI大模型从业者的核心竞争力
- 持续学习能力:Al技术日新月异,保持学习是关键。
- 跨领域思维:Al大模型需要结合业务场景,具备跨领域思考能力的从业者更受欢迎。
- 解决问题的能力:AI大模型的应用需要解决实际问题,你的编程经验将大放异彩。
以前总有人问我说:老师能不能帮我预测预测将来的风口在哪里?
现在没什么可说了,一定是Al;我们国家已经提出来:算力即国力!
未来已来,大模型在未来必然走向人类的生活中,无论你是前端,后端还是数据分析,都可以在这个领域上来,我还是那句话,在大语言AI模型时代,只要你有想法,你就有结果!只要你愿意去学习,你就能卷动的过别人!
现在,你需要的只是一份清晰的转型计划和一群志同道合的伙伴。作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。

第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
- 硬件选型
- 带你了解全球大模型
- 使用国产大模型服务
- 搭建 OpenAI 代理
- 热身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地计算机运行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何优雅地在阿里云私有部署开源大模型
- 部署一套开源 LLM 项目
- 内容安全
- 互联网信息服务算法备案
- …
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】


















 2153
2153

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









