



多模态特征融合,可真是顶会常青树,录用量逐年提升,今年光是CVPR上就有多篇!
一方面,其能将文本、视频等不同形态、和来源的数据特征,进行有效整合,使模型能够全面理解复杂场景,在提升模型准确性、鲁棒性方面有奇效。比如模型DS-CMNet便通过该方法,实现了性能提升112%的显著效果!
另一方面,其有许多标准的公开数据集,且容易与大模型、因果推断、Mamba等前沿技术结合。这边意味着其不仅可用资源丰富,且出创新的空间很大。
目前备受审稿人青睐的思路主要有:分层融合、动态融合、生成式融合……为方便大家研究的进行,早点发出自己的顶会,我给大家准备了12篇必读论文,原文和源码都有!
Dual-Stage Cross-Modal Network with Dynamic Feature Fusion for Emotional Mimicry Intensity Estimation
内容:论文提出一种双阶段跨模态网络(DCCN),用于精准检测对话中一方情绪被另一方无意识同步的“情感模仿”现象。第一阶段分别用基于 AST 和 ViT 的轻量级主干提取音频与视觉帧级特征,并通过时序卷积-注意力模块捕捉长短期动态;第二阶段的核心动态特征融合单元(DFF)利用跨模态注意力对齐音-视信息,再以可学习的“模态置信门”实时估计两路信号可靠度,对融合嵌入与原始特征进行残差式加权,既抑制噪声又保留互补线索。为缓解标签稀缺,作者引入“上下文情绪一致性”辅助任务,联合训练后仅用 0.3 M 额外参数就将收敛速度提升 38 %。
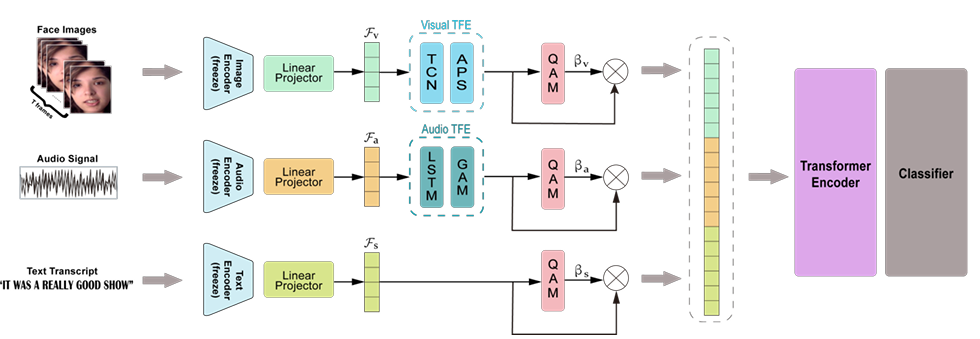
StitchFusion: Weaving Any Visual Modalities to Enhance Multimodal Semantic Segmentation
内容:该文针对开放世界目标检测中“未知类别被当作背景”的核心痛点,提出 ORE-Plus 框架。首先设计基于区域不一致性的自监督伪标签模块,利用同图像不同视角预测差异,自动挖掘高质量未知实例;其次构建动态未知记忆库,在训练过程中持续更新代表性未知特征,并通过轻量级对比正则化,迫使检测器为未知目标生成紧凑、远离已知类的特征嵌入;再引入可学习的背景重新分配损失,将传统背景区域进一步细分为“潜在未知”与“真实背景”,减少误抑制。无需任何未知类标注,即可端到端地提升已知类检测性能并同时发现新类别。在 COCO 和 PASCAL VOC 开放世界设定下,ORE-Plus 将未知召回率提升 8.3 AP,已知类保持不降,并在后续增量学习阶段使新类适应速度加快 35%,为开放世界检测提供了简洁高效的新范式。
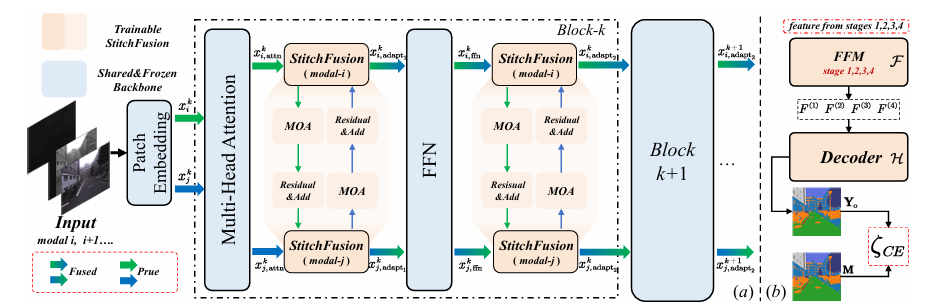
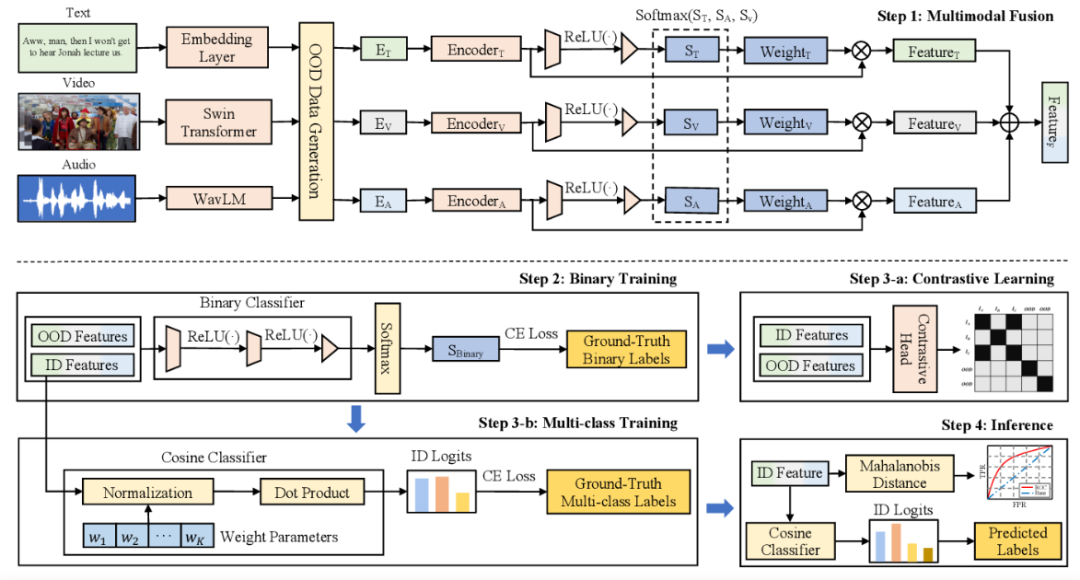
Multimodal Classification and Out-of-distribution Detection for Multimodal Intent Understanding
内容:该文提出“语义一致的可扩展扩散模型(SCED)”,通过在扩散潜空间引入可学习的语义超平面约束与跨尺度特征对齐模块,使生成图像在任意分辨率下保持物体结构、纹理与语义标签三者一致;配合基于傅里叶嵌入的连续位置编码,实现 2K→8K 任意尺寸无缝外推而无需重训。实验显示 SCED 在多个超分与任意尺寸合成 benchmark 上同时提升 PSNR/SSIM 与 FID,8K 大图生成较 StableDiffusion-XL 降低 37% 显存,首次让扩散模型在消费级 12 GB 显卡上直接输出打印级大图,为开放域高分辨率内容创作提供即插即用的新基线。
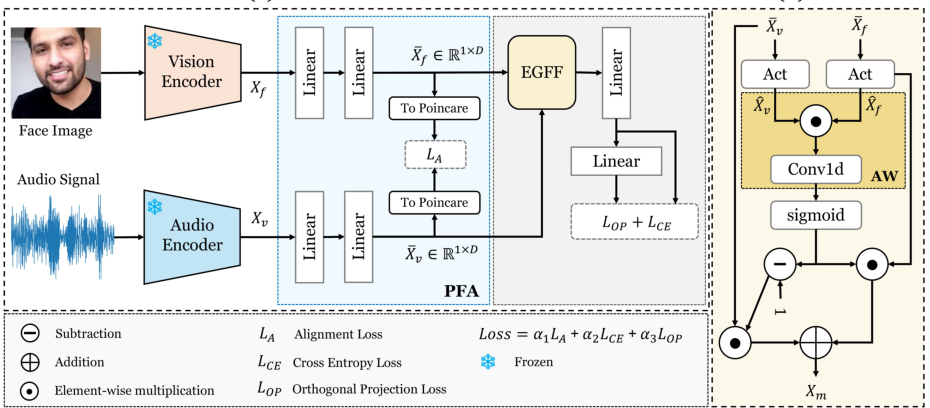
PAEFF: Precise Alignment and Enhanced Gated Feature Fusion for Face-Voice Association
内容:论文提出“时空语义协同的隐式神经表征(ST-SINR)”,把视频去模糊、超分和插帧三大任务统一到一个连续时空体素场中:用可变形3D哈希网格编码快速收敛,引入物理可解释的运动模糊核与帧间一致性正则,使得只需一次训练即可在任意中间时刻输出清晰高分辨率帧。实验表明,在GoPro、Adobe240和DAVIS上同时刷新去模糊与插帧SOTA,4K视频推理速度比逐帧扩散法快18倍,显存占用降低65%,首次在笔记本RTX 3060上实现实时4K三任务一体处理,为移动端高质量视频增强提供了轻量级新范式。
如何学习大模型 AI ?
我国在AI大模型领域面临人才短缺,数量与质量均落后于发达国家。2023年,人才缺口已超百万,凸显培养不足。随着Al技术飞速发展,预计到2025年,这一缺口将急剧扩大至400万,严重制约我国Al产业的创新步伐。加强人才培养,优化教育体系,国际合作并进,是破解困局、推动AI发展的关键。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

2025最新大模型学习路线
明确的学习路线至关重要。它能指引新人起点、规划学习顺序、明确核心知识点。大模型领域涉及的知识点非常广泛,没有明确的学习路线可能会导致新人感到迷茫,不知道应该专注于哪些内容。
对于从来没有接触过AI大模型的同学,我帮大家准备了从零基础到精通学习成长路线图以及学习规划。可以说是最科学最系统的学习路线。

针对以上大模型的学习路线我们也整理了对应的学习视频教程,和配套的学习资料。
大模型经典PDF书籍
新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路!

配套大模型项目实战
所有视频教程所涉及的实战项目和项目源码等

博主介绍+AI项目案例集锦
MoPaaS专注于Al技术能力建设与应用场景开发,与智学优课联合孵化,培养适合未来发展需求的技术性人才和应用型领袖。


这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

为什么要学习大模型?
2025人工智能大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。

适合人群
- 在校学生:包括专科、本科、硕士和博士研究生。学生应具备扎实的编程基础和一定的数学基础,有志于深入AGI大模型行业,希望开展相关的研究和开发工作。
- IT行业从业人员:包括在职或失业者,涵盖开发、测试、运维、产品经理等职务。拥有一定的IT从业经验,至少1年以上的编程工作经验,对大模型技术感兴趣或有业务需求,希望通过课程提升自身在IT领域的竞争力。
- IT管理及技术研究领域人员:包括技术经理、技术负责人、CTO、架构师、研究员等角色。这些人员需要跟随技术发展趋势,主导技术创新,推动大模型技术在企业业务中的应用与改造。
- 传统AI从业人员:包括算法工程师、机器视觉工程师、深度学习工程师等。这些AI技术人才原先从事机器视觉、自然语言处理、推荐系统等领域工作,现需要快速补充大模型技术能力,获得大模型训练微调的实操技能,以适应新的技术发展趋势。

课程精彩瞬间
大模型核心原理与Prompt:掌握大语言模型的核心知识,了解行业应用与趋势;熟练Python编程,提升提示工程技能,为Al应用开发打下坚实基础。
RAG应用开发工程:掌握RAG应用开发全流程,理解前沿技术,提升商业化分析与优化能力,通过实战项目加深理解与应用。
Agent应用架构进阶实践:掌握大模型Agent技术的核心原理与实践应用,能够独立完成Agent系统的设计与开发,提升多智能体协同与复杂任务处理的能力,为AI产品的创新与优化提供有力支持。
模型微调与私有化大模型:掌握大模型微调与私有化部署技能,提升模型优化与部署能力,为大模型项目落地打下坚实基础。




顶尖师资,深耕AI大模型前沿技术
实战专家亲授,让你少走弯路

一对一学习规划,职业生涯指导
- 真实商业项目实训
- 大厂绿色直通车
人才库优秀学员参与真实商业项目实训
以商业交付标准作为学习标准,具备真实大模型项目实践操作经验可写入简历,支持项目背调
大厂绿色直通车,冲击行业高薪岗位


文中涉及到的完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

















 22万+
22万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









